1. 源代码
import subprocess
import os
# Simple PDF format checker, author: Rose Yu (roseyu@ucsd.edu)
# prerequiste: brew install poppler (Mac)
def pdfinfo_cmd(filename):
# Execute the pdfinfo command
cmd = 'pdfinfo'
args = filename
temp = subprocess.Popen([cmd, args], stdout=subprocess.PIPE)
output =str(temp.communicate())
tokens = output.strip().split(r'\n')
res = []
for token in tokens:
res.append(token)
return res
def check_pdfinfo(filename):
# Check whether page limit and US letter size
res = pdfinfo_cmd(filename)
for i in range(1, len(res)-1):
line = res[i].split(':')
#print(line[0])
if line[0] == "Pages":
# line[1].replace('\\r' , ' ')
page_num = int(line[1].replace('\\r','').replace('\n','').replace('\t',''))
# page_num = page_num.replace('\\r','').replace('\n','').replace('\t','')
elif line[0] == "Page size":
page_size = [int(word) for word in line[1].split() if word.isdigit()]
#print('Filename', filename)
#print('page num: ', page_num)
#print('page size: ', page_size)
if page_num not in (12, 11, 9, 10, 4, 2):
print("page number error!")
return False
if page_size[0]!=612 and page_size[1]!=792:
print("page size error!")
return False
return True
def pdffonts_cmd(filename):
# Execute pdffonts command
cmd = 'pdffonts'
args = filename
temp = subprocess.Popen([cmd, args], stdout=subprocess.PIPE)
output =str(temp.communicate())
tokens = output.strip().split(r'\n')
#print('len of the tokens '+ str(len(tokens)))
res = []
for token in tokens:
res.append(token)
return res
def check_pdffonts(filename):
# Check whether the fonts are embedded
res = pdffonts_cmd(filename)
for i in range(2, len(res)-1):
line = res[i].split()
#print('len of the line ', len(line))
embed_font = line[4]
if embed_font != "yes":
print("embed font error!")
return False
return True
if __name__ == '__main__':
directory = "./"
for filename in os.listdir(directory):
if filename.endswith(".pdf"):
if not (check_pdfinfo(filename) and check_pdffonts(filename)):
print(os.path.join(directory, filename))
2. 关于代码的一些解释
- subprocess模块,subprocess 模块允许我们启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值。
- os模块,该模块提供了一些方便使用操作系统相关功能的函数。
- pdfinfo_cmd函数:
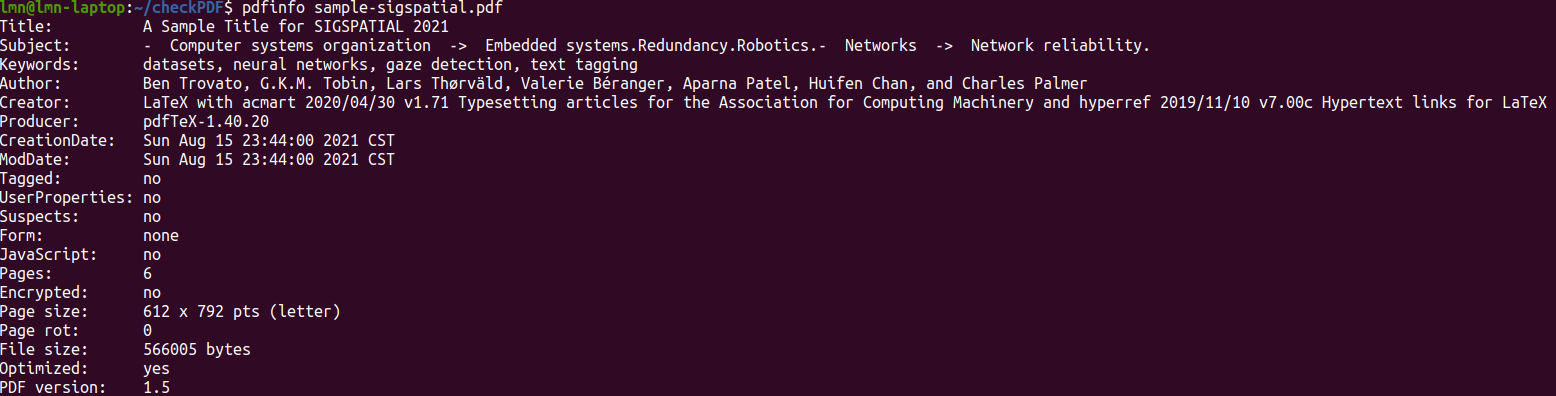
- subprocess.Popen用来创建子进程,子进程功能为执行pdfinfo命令,在linux终端下执行pdfinfo命令的输出结果如下所示
- communicate(input,timeout)是Popen对象的方法,功能为:和子进程交互,发送和读取数据。
- tokens = output.strip().split(r'\n'),先移除output字符串头尾的空格或换行符,然后按换行符对字符串进行切片,分割后的字符串列表存储到tokens中。
- 函数的最后四行我觉得是把列表tokens复制一下,然后返回复制后的列表,具体用意不大理解。
- check_pdfinfo函数:
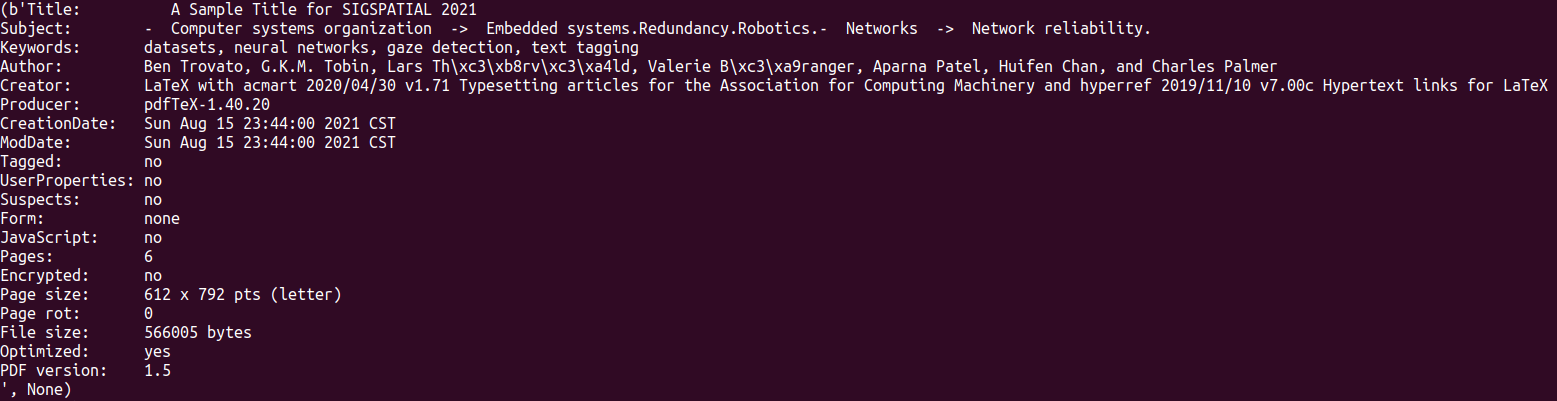
- res列表的全部元素如下所示
- 此函数中for循环并未遍历头尾两个元素
- for循环结束后可得到pdf的Pages和Page size,如下所示

- pdffonts_cmd函数:
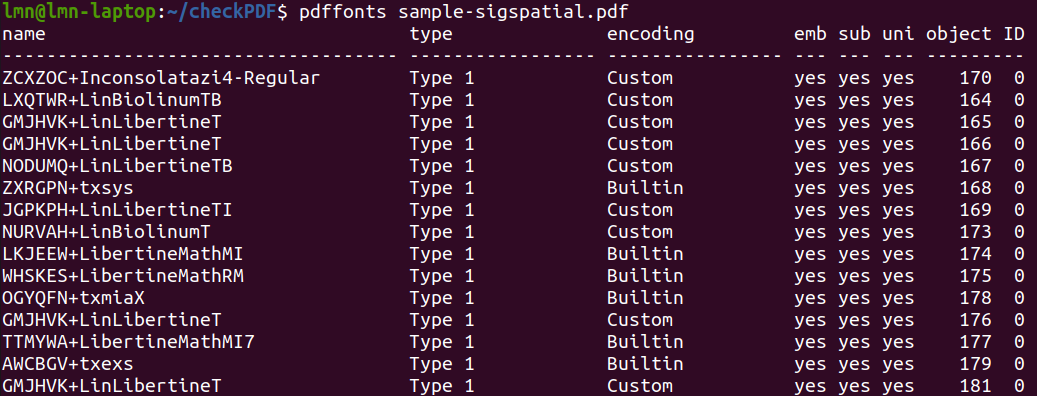
- 此函数功能大体上和pdfinfo_cmd函数一致,在linux终端下执行pdffonts命令的输出结果如下所示
- check_pdffonts函数:
- res列表的全部元素如下所示

- for循环并未遍历前两个和最后一个元素
- for循环只检查emb那一列的值是否全部为yes
- 论文中的字体必须是Type 1或True Type的,而且所有字体都要内嵌到pdf文件中
- emb列反映的是pdf文件使用的所有字体是否被内嵌了(点击了解更多相关信息)
- if __name__ == '__main__':
- 一个python文件通常有两种使用方法,第一是作为脚本直接执行,第二是 import 到其他的 python 脚本中被调用(模块重用)执行。
- if __name__ == '__main__': 的作用就是控制这两种情况执行代码的过程,在 if __name__ == '__main__': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行的。
- 此函数遍历了当前目录下所有后缀为.pdf的文件,若pdf文件不满足pdfinfo检查或不满足pdffonts检查,就输出此文件的路径
3. 代码逻辑及其检查的内容
- 此代码遍历当前目录下所有后缀为.pdf的文件,对它进行以下两个检查:
- pdf文件的页数和页面大小是否符合规定
- pdf文件中的所使用的字体是否都被内嵌
- 以上两个检查若有一个不合格,就输出相应的错误信息以及此文件的路径

 浙公网安备 33010602011771号
浙公网安备 33010602011771号