
0.PTA得分截图
1.本周学习总结
1.1 总结树及串内容
串
-
定义:零个或多个字符组成的有限序列
-
串的存储结构:
-
定长顺序存储:用一组地址连续的存储单元存储串值的字符序列,称为顺序串。可用一个数组来表示。
- 结构定义:
#define MaxSize 100
typedef struct
{
char data[MaxSize];//data域存储字符串,
int length;//length域存储字符串长度,
} SqString;
-
堆分配顺序存储:仍用一组地址连续的存储单元存储串值的字符序列,但其存储空间是动态分配。
- 结构定义:
typedef struct
{
char *ch;//为空是NULL,不为空,按串长度分配存储区域
int length;//存字符串长度
}HString;
-
链式存储:链串中的一个结点可以存储多个字符。通常将链串中每个结点所存储的字符个数称为结点大小。
-
提醒:链式串没有顺序串灵活,操作复杂。
-
结构定义:
-
typedef struct Chunk{
char ch[MaxSIZE];
struct Chunk *next;
}Chunk;
typedef struct{
Chunk *head,*tail; //串的头指针和尾指针
int curlen; //串的当前长度
}LString;
3.基本操作
StrAssign(&s,cstr):将字符串常量cstr赋给串s,即生成其值等于cstr的串s。
StrCopy(&s,t):串的复制。将串t赋给串s。
StrEqual(s,t):判断串是否相等。如果相等返回真,不等返回假。
StrLength(s):求串的长度。返回串s中字符的个数。
Concat(s,t):串的连接。返回由串s和串t连接在一起形成的新串。
SubStr(s,i,j):求子串。返回串s中从第i个(1≤i≤n)字符开始的、由连续j个字符组成的子串。
InsStr(s1,i,s2):插入。将串s2插入到串s1的第i个字符中(1≤i≤n+1),即将s2的第一个字符作为s1的第i个字符,并返回产生的新串。
DelStr(s,i,j):删除。从串s中删去第i个字符(1≤i≤n)开始的长度为j的子串,并返回产生的新串。
RepStr(s,i,j,t):替换。在串s中,将第i个字符(1≤i≤n)开始的第j个字符构成的子串用串t替换,并返回产生的新串。
DispStr(s):输出。输出串s的所有元素的值。
4.C++中的string
总结:
- 属于一个类,使用时加上“#include
” - 不必担心字符长度、内存大小的问题,集合了大部分函数
- 注意:getline(cin,s):读取一行字符串;cin>>s:读取空格前的字符
5.串的应用(BF/KMP算法)
BF算法
- 基本思路:
1.从目标串的首个字符开始和模式串的首个字符比较;
2.相等则继续比较后续字符,否则从目标串的第二个字符开始重新与模式串的第一个字符进行比较;
3.以此类推,成功返回目标串的首个字符地址,否则返回-1.
- 代码展示
int index(SqString s, SqString t)
{
int i = 0, j = 0;
while (i < s.length && j < t.length) //两个串都没有扫描完时循环
{
if (s.data[i] == t.data[j])//当前比较的两个字符相同
{
i++; j++;//依次比较后续的两个字符
}
else//当前比较的两个字符不相同
{
i = i - j + 1; j = 0;//扫描目标串的i回退,子串从头开始匹配
}
}
if (j >= t.length)//j 超界,表示t是s的子串
return(i - t.length);//返回t在s中的位置
else//模式匹配失败
return(-1);//返回-1
}
KMP算法
-
优势:每一趟比较重出现字符不等时,不需要回溯索引指针i,而是利用已经得到的部分匹配的结果将子串向右滑动尽可能远的距离,继续进行比较。
-
关键:引进next[j],这里的next[j]数组指的是对应j之前的字符串中, 最长相同字串的长度,通过求出匹配串t的next数组表示的信息时,就可以用来消除主串指针的回溯,从而减少程序运行的时间。
-
代码:
void Getnext(int next[],String t)
{
int j=0,k=-1;
next[0]=-1;
while(j<t.length-1)
{
if(k == -1 || t[j] == t[k])
{
j++;k++;
next[j] = k;
}
else k = next[k];//此语句是这段代码最反人类的地方,如果你一下子就能看懂,那么请允许我称呼你一声大神!
}
}
1.2 二叉树存储结构、建法、遍历及应用
1. 存储结构:
- 顺序存储结构:首先对该树中的每个结点进行编号,编号作为下标,把各结点的值对应下标存储到一个数组中。比如说,树根结点的编号为1,接着按照从上到下和从左到右的次序编号。

特点:
- 完全二叉树和满二叉树采用顺序存储比较合适;
- 节省空间且数组元素下标值能确定结点在二叉树中的位置和结点之间的关系;
- 空间利用率不高。
- 链式存储结构:用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址。

特点:
- 使用较顺序存储更多;
- 在含有n个结点的二叉链表中,含有n+1个空链域;
- 使用不同的存储结构时(此外还有孩子兄弟链等结构),实现二叉树操作的算法也会不同,因此要根据实际应用场合选择合适的存储结构。
2.建立方法:
- 顺序存储转二叉树:
BTree CreateBTree(string str, int i)
{
if (str[1] == '\0') return NULL;
if (i > str.size() - 1) return NULL;
if (str[i] == '#') return NULL;
BTree bt;
bt = new BTNode;
bt->data = str[i];
bt->lchild = CreateBTree(str, 2 * i);
bt->rchild = CreateBTree(str, 2 * i + 1);
return bt;
}
- 先序遍历建二叉树:
void CreateTree(PTree &tree, string str, int len)
{
tree = new Tree;
if (i >= len || i < 0)
{
tree = NULL;
return;
}
if (str[i] == '#')
{
i++;
tree = NULL;
return;
}
tree->data = str[i];
i++;
CreateTree(tree->lchild, str, len );
CreateTree(tree->rchild, str, len );
}
- 层次遍历建二叉树:
void CreateBTree(BTree &BT,string str)
{
BTree T;
int i=0;
quueue<BTree> qu;
if( str[0]!='0' )
{
BT =new BTNode;
BT->data = str[0];
BT->lchild=BT->rchild=NULL;
qu.push(BT);
}
else BT=NULL;
while( !qu.empty())
{
T = qu.front();
qu.pop();
i++;
if(str[i]=='0' ) T->lchild = NULL;
else
{
T->lchild = new BTNode;
T->lchild->data = str[i];
T->lchild->lchild=T->lchild->rchild=NULL;
qu.push(T->lchild);
}
i++;
if(str[i]=='0') T->rchild = NULL;
else
{
T->rchild = new BTNode;;
T->rchild->data = str[i];
T->rchild->lchild=T->rchild->rchild=NULL;
qu.push(T->rchild);
}
}
}
- 先序中序建二叉树:
PTree GetTree(char *pre, char *in, int n)
{
PTree s;
char *p;
int k;
if (n <= 0)return NULL;
s = new Tree;
s->data=*pre;
for (p = in; p < in + n; p++)
if (*p == *pre)
break;
k = p - in;
s->lchild = GetTree(pre + 1, in, k);
s->rchild = GetTree(pre + k + 1, p + 1, n - k - 1);
return s;
}
- 后序中序建二叉树:
BTree CreateBTree(int* post, int* in, int n)
{
if (n <= 0) return NULL;
BTree bt;
int* pos;
int k;
bt = new BTNode;
bt->data = post[n-1];
for (pos = in;pos < in + n;pos++)
{
if (*pos == post[n-1]) break;
}
k = pos - in;
bt->lchild = CreateBTree(post, in, k);
bt->rchild = CreateBTree(post + k, pos + 1, n - k - 1);
return bt;
}
3.遍历方法:
- 先序遍历
void PreOrder(BTree bt)
{
if (bt == NULL) return;
cout << " " << bt->data;
PreOrder(bt->lchild);
PreOrder(bt->rchild);
}
-
中序、后序遍历与上述类似
-
层次遍历
void levelorder(PTree tree)
{
queue<PTree>s;
PTree t;
if (tree != NULL)s.push(tree);
else
cout << "NULL";
while (!s.empty())
{
t = s.front();
s.pop();
if (t->lchild!=NULL&&t->rchild!=NULL)
cout << t->data << " ";
else
cout << t->data;
if(t->lchild != NULL)
s.push(t->lchild);
if (t->rchild != NULL)
s.push(t->rchild);
}
}
1.3 树的存储结构、操作、遍历及应用
1.树的存储结构:
- 双亲存储结构
typedef struct
{
ElemType data;
int parent;
} Tree[MaxSize];
不足:无法进行孩子查找
- 孩子链存储结构
typedef struct TSnode
{
ElemType data;
struct TSnode *child[MaxSons];
} TNode;
不足:
- 空间利用率不高
- 找不到父母
- 孩子兄弟存储结构
typedef struct Tnode
{
ElemType data; //结点的值
struct Tnode *son; //指向兄弟
struct Tnode *brother; //指向孩子结点
} TSBNode;
不足:找双亲不容易
2.树的操作:遍历、插入、删除,但后两种看的少
1.4 线索二叉树
- 优点:将普通二叉树中的空节点利用了起来,提升了空间利用率
- 结构定义:
typedef struct TNode
{
ElemType data; //结点数据
struct BTNode *lchild, *rchild; //左右孩子指针
int ltag; //左右标志
int rtal;
}BTNode, *BTree;
- 三种线索二叉树:先序线索二叉树、中序线索二叉树、后序线索二叉树。
1.5 哈夫曼树、并查集
哈夫曼树
-
定义:带权路径长度最短的二叉树具体代码
-
结构定义
typedef struct {
int weight;
int parent;
int lchild;
int rchild;
}HTNODE;
- 具体代码
void CreateHT(HTNODE tree[], int n)
{
int i, j, k, lnode, rnode;
float min1, min2;
for (i = 0; i < 2 * n - 1; i++)//对节点初始化
tree[i].parent = tree[i].lchild = tree[i].rchild = -1;
for (i = n; i < 2 * n - 1; i++)
{
min1 = min2 = 2147483647;
lnode = rnode = -1;
for(k=0;k<=i-1;k++)
if (tree[k].parent == -1)//寻找weight最小两项
{
if (tree[k].weight < min1)
{
min2 = min1;
rnode = lnode;
min1 = tree[k].weight;
lnode = k;
}
else if (tree[k].weight < min2)
{
min2 = tree[k].weight;
rnode = k;
}
}
tree[lnode].parent = i; tree[rnode].parent = i;
tree[i].weight = tree[lnode].weight + tree[rnode].weight;
tree[i].lchild = lnode;
tree[i].rchild = rnode;
}
}
2. 谈谈你对树的认识及学习体会
树结构是我们学习的第一个非线性结构,应该说它确实在理解与应用上提高了难度,尤其是因为程序执行过程中多使用递归算法,过程不太具体形象,所以在做题时很多时候靠的的是一种感觉去写,代码背后是一遍又一遍的手动递归操作。总的来说,树是相当重要的,在实际应用中也常常可见,还需要花时间去巩固。
2.阅读代码
2.1 题目及解题代码

代码:
class Solution {
public boolean isSubtree(TreeNode s, TreeNode t) {
String tree1 = preOrder(s, true);
String tree2 = preOrder(t, true);
return tree1.indexOf(tree2) >= 0;
}
private String preOrder(TreeNode node, boolean left) {
if (node == null) {
if (left) return "lnull";
else return "rnull";
}
return "#" + node.val + " " + preOrder(node.left, true) + " " + preOrder(node.right, false);
}
}
2.1.1 该题的设计思路
先找到给定树 ss 和 tt 的先序遍历序列,分别由 ss 先序遍历和 tt 先序遍历给出(以字符串形式表示),检查 tt 先序遍历序列是否是 ss 先序遍历序列的子字符串;
2.1.3 运行结果
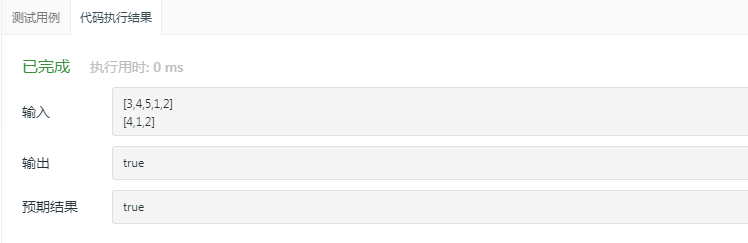
2.1.4分析该题目解题优势及难点
固有思路是每次只能取出一棵树中的一个节点的数据,再取出另一棵树的节点数据进行比较,但其实这是最慢的。而本代码首先比较两棵树是否相等的函数,因为如果一棵树是另一棵树的子树,那么必定存在这棵树和另一棵树的子树相等,而compare函数利用了遍历树的常规思路——递归,首先比较根节点,若根节点同时为空,则两树相等。使用递归,成功简化了过程。
2.2 题目及解题代码

代码:
static bool Symmetric(struct TreeNode* leftNode, struct TreeNode* rightNode)
{
if (NULL == leftNode && NULL == rightNode)
{
return true;
}
if (NULL == leftNode || NULL == rightNode)
{
return false;
}
return (leftNode->val == rightNode->val) &&
Symmetric(leftNode->right, rightNode->left) &&
Symmetric(leftNode->left, rightNode->right);
}
bool isSymmetric(struct TreeNode* root){
return Symmetric(root, root);
}
2.2.1 该题的设计思路
- 判断两个指针当前节点值是否相等
- 判断 A 的右子树与 B 的左子树是否对称
- 判断 A 的左子树与 B 的右子树是否对称
2.2.3 运行结果
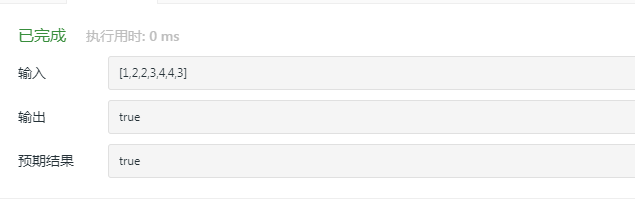
2.2.4分析该题目解题优势及难点
仅仅对树进行操作难以操作,但是转化为数组之后思路就比较明朗了,根据已知的二叉搜索树(BST)定义要注意到中序遍历的结果应该是升序序列,题解先添加到res数组中就可以避免每个元素都出现一次,而v[0]没有添加到res的情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号