精通python网络爬虫之自动爬取网页的爬虫 代码记录
items的编写


1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class AutopjtItem(scrapy.Item): 12 # define the fields for your item here like: 13 # 用来存储商品名 14 name = scrapy.Field() 15 #用来存储商品价格 16 price = scrapy.Field() 17 # 用来存储商品链接 18 link = scrapy.Field() 19 # 用来存储商品评论数 20 comnum = scrapy.Field() 21 # 用来存储商品评论内容链接 22 comnum_link = scrapy.Field()
piplines的编写
1 # -*- coding: utf-8 -*- 2 import codecs 3 import json 4 # Define your item pipelines here 5 # 6 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 7 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 8 9 class AutopjtPipeline(object): 10 def __init__(self): 11 self.file = codecs.open("D:/git/learn_scray/day11/1.json", "wb", encoding="utf-8") 12 13 def process_item(self, item, spider): 14 # 爬取当前页的所有信息 15 for i in range(len(item["name"])): 16 name = item["name"][i] 17 price = item["price"][i] 18 link = item["link"][i] 19 comnum = item["comnum"][i] 20 comnum_link = item["comnum_link"][i] 21 current_conent = {"name":name,"price":price,"link":link, 22 "comnum":comnum,"comnum_link":comnum_link} 23 j = json.dumps(dict(current_conent),ensure_ascii=False) 24 # 为每条数据添加换行 25 line = j + '\n' 26 print(line) 27 self.file.write(line) 28 # for key,value in current_conent.items(): 29 # print(key,value) 30 return item 31 32 def close_spider(self,spider): 33 self.file.close()
自动爬虫编写实战
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from autopjt.items import AutopjtItem 4 from scrapy.http import Request 5 6 class AutospdSpider(scrapy.Spider): 7 name = 'autospd' 8 allowed_domains = ['dangdang.com'] 9 # 当当地方特产 10 start_urls = ['http://category.dangdang.com/pg1-cid10010056.html'] 11 12 def parse(self, response): 13 item = AutopjtItem() 14 print("进入item") 15 # print("获取标题:") 16 # 获取标题 17 item["name"] = response.xpath("//p[@class='name']/a/@title").extract() 18 # print(title) 19 20 # print("获取价格:") 21 # 价格 22 item["price"] = response.xpath("//span[@class='price_n']/text()").extract() 23 # print(price) 24 25 # print("获取商品链接:") 26 # 获取商品链接 27 item["link"] = response.xpath("//p[@class='name']/a/@href").extract() 28 # print(link) 29 30 # print("\n") 31 # print("获取商品评论数:") 32 # 获取商品评论数 33 item["comnum"] = response.xpath("//a[@name='itemlist-review']/text()").extract() 34 # comnum = response.xpath("//a[@name='itemlist-review']/text()").extract() 35 # print(comnum) 36 37 # print("获取商品评论数链接:") 38 # 获取商品评论数链接 39 item["comnum_link"] = response.xpath("//a[@name='itemlist-review']/@href").extract() 40 # comnum_link = response.xpath("//a[@name='itemlist-review']/@href").extract() 41 # print(comnum_link) 42 yield item 43 for i in range(1,79): 44 # print(i) 45 url = "http://category.dangdang.com/pg"+ str(i) + "-cid10010056.html" 46 # print(url) 47 yield Request(url, callback=self.parse)
yield详解:
https://stackoverflow.com/questions/231767/what-does-the-yield-keyword-do
settings的设置:
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for autopjt project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # https://doc.scrapy.org/en/latest/topics/settings.html 9 # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 10 # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'autopjt' 13 14 SPIDER_MODULES = ['autopjt.spiders'] 15 NEWSPIDER_MODULE = 'autopjt.spiders' 16 17 18 # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 #USER_AGENT = 'autopjt (+http://www.yourdomain.com)' 20 21 # Obey robots.txt rules 22 # 默认为true遵守robots.txt协议 我试了一下能爬 为了保险设置为false 23 ROBOTSTXT_OBEY = True 24 25 # Configure maximum concurrent requests performed by Scrapy (default: 16) 26 #CONCURRENT_REQUESTS = 32 27 28 # Configure a delay for requests for the same website (default: 0) 29 # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay 30 # See also autothrottle settings and docs 31 #DOWNLOAD_DELAY = 3 32 # The download delay setting will honor only one of: 33 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 34 #CONCURRENT_REQUESTS_PER_IP = 16 35 36 # Disable cookies (enabled by default) 37 COOKIES_ENABLED = False 38 39 # Disable Telnet Console (enabled by default) 40 #TELNETCONSOLE_ENABLED = False 41 42 # Override the default request headers: 43 #DEFAULT_REQUEST_HEADERS = { 44 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 45 # 'Accept-Language': 'en', 46 #} 47 48 # Enable or disable spider middlewares 49 # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html 50 #SPIDER_MIDDLEWARES = { 51 # 'autopjt.middlewares.AutopjtSpiderMiddleware': 543, 52 #} 53 54 # Enable or disable downloader middlewares 55 # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 56 #DOWNLOADER_MIDDLEWARES = { 57 # 'autopjt.middlewares.AutopjtDownloaderMiddleware': 543, 58 #} 59 60 # Enable or disable extensions 61 # See https://doc.scrapy.org/en/latest/topics/extensions.html 62 #EXTENSIONS = { 63 # 'scrapy.extensions.telnet.TelnetConsole': None, 64 #} 65 66 # Configure item pipelines 67 # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 68 ITEM_PIPELINES = { 69 'autopjt.pipelines.AutopjtPipeline': 300, 70 } 71 72 # Enable and configure the AutoThrottle extension (disabled by default) 73 # See https://doc.scrapy.org/en/latest/topics/autothrottle.html 74 #AUTOTHROTTLE_ENABLED = True 75 # The initial download delay 76 #AUTOTHROTTLE_START_DELAY = 5 77 # The maximum download delay to be set in case of high latencies 78 #AUTOTHROTTLE_MAX_DELAY = 60 79 # The average number of requests Scrapy should be sending in parallel to 80 # each remote server 81 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 82 # Enable showing throttling stats for every response received: 83 #AUTOTHROTTLE_DEBUG = False 84 85 # Enable and configure HTTP caching (disabled by default) 86 # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 87 #HTTPCACHE_ENABLED = True 88 #HTTPCACHE_EXPIRATION_SECS = 0 89 #HTTPCACHE_DIR = 'httpcache' 90 #HTTPCACHE_IGNORE_HTTP_CODES = [] 91 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
最后的效果:
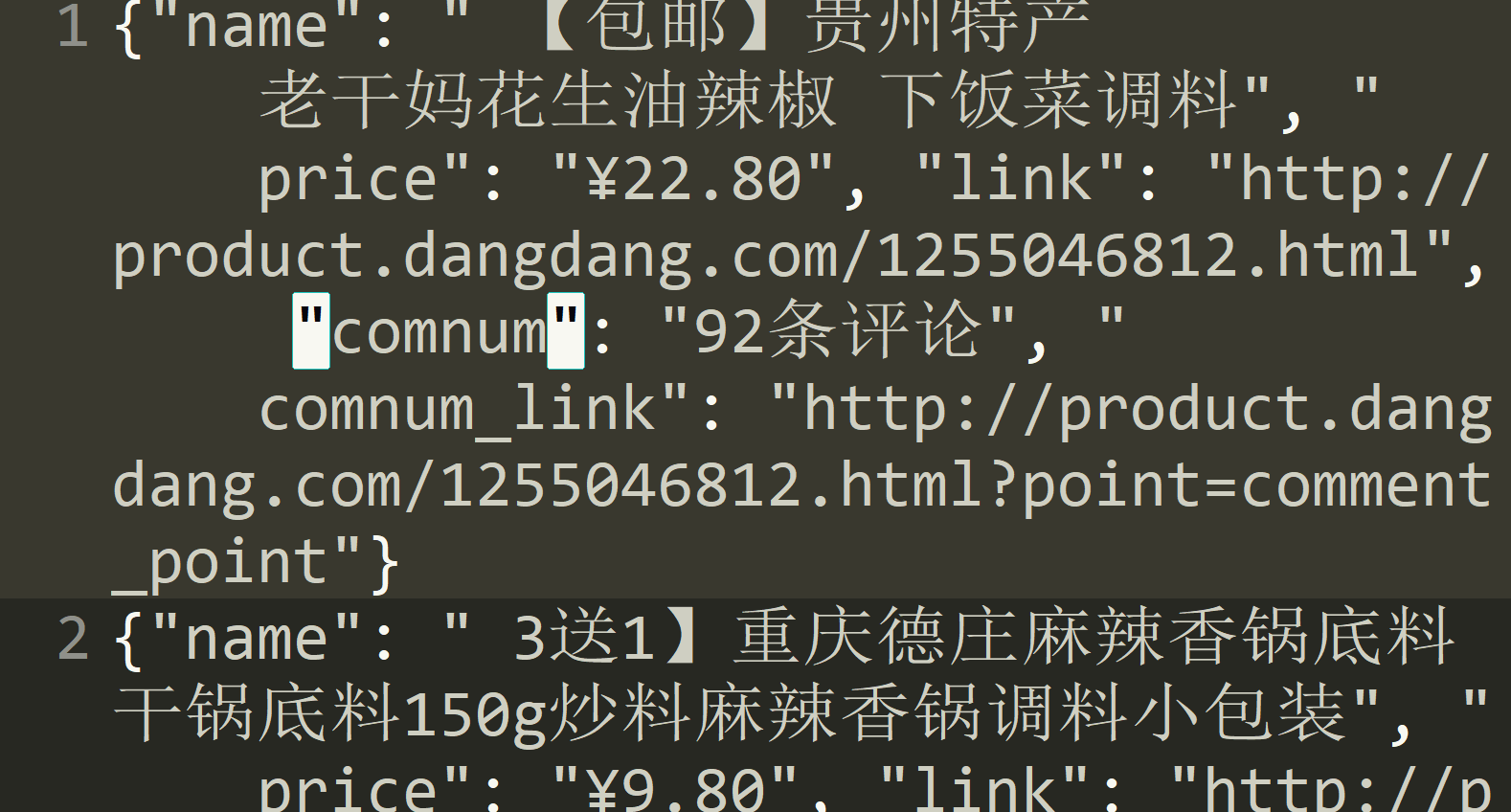
作者:以罗伊
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文链接,否则保留追究法律责任的权利。

