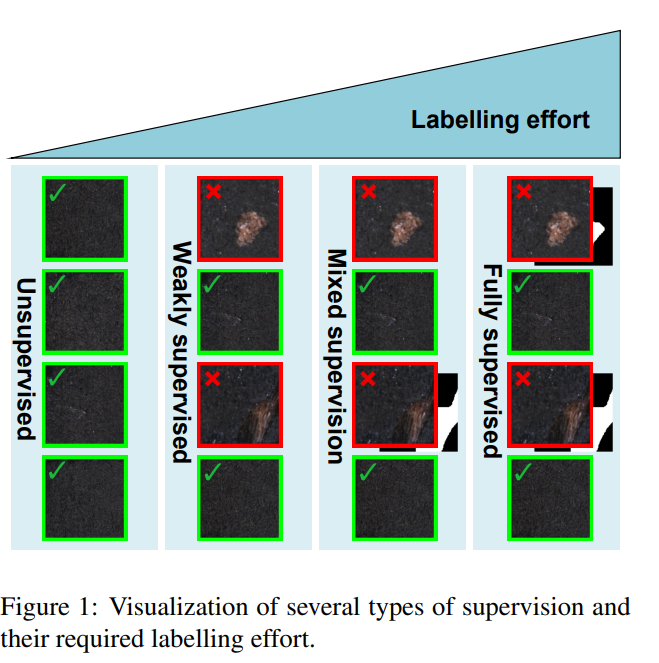
这篇文章不管是网络结构还是文章中提到的亮点基本都是复用了<End-to-end training of a two-stage neural network for defect detection>
唯一的不同点就是针对混合监督,针对其中只有正负标签,没有分割标签的数据,损失函数只是用分类损失函数,如果都有,就是用分类函数和分割函数一起
这样的好处,可以降低有分割标签数据的数量,可以节省做分割标签的时间。
End-to-end learning We combine the segmentation and the classification losses into a single unified loss, which allows for a simultaneous learning in an end-to-end manner.
The combined loss is defined as:
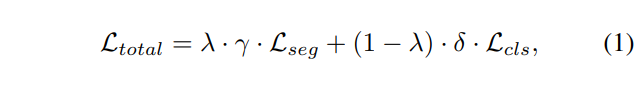
端到端的学习 我们将分割和分类的损失合并成一个简单的统一的损失,它允许在端到端过程中进行同步的学习, 综合损失定义为:
Using weakly labeled data The proposed end-to-end learning pipeline is designed to enable utilisation of the weakly labeled data alongside fully labeled one. Such adoption of mixed supervision allows us to take a full advantage of any pixel-level labels when available, which weakly and unsupervised methods are not capable of using. We use γ from Eq. 1 to control the learning of the segmentation subnetwork based on the presence of pixel-level annotation:

使用弱标签数据 提出的端到端的学习管道被设计为可以使用弱标签与完全标签数据一起使用。像这样采用混合监督允许我们充分利用任何有用的像素级别标签,这是弱和无监督方法无法使用的,我们使用y等于1来控制基于像素级别标签存在的分割子网络
通过使用is_segmented[sub_iter]来判断是否添加分割的损失函数。
if is_segmented[sub_iter]: if self.cfg.WEIGHTED_SEG_LOSS: loss_seg = torch.mean(criterion_seg(output_seg_mask, seg_masks_) * seg_loss_masks_) else: loss_seg = criterion_seg(output_seg_mask, seg_masks_) loss_dec = criterion_dec(decision, is_pos_) # 这个地方有疑问 total_loss_seg += loss_seg.item() total_loss_dec += loss_dec.item() total_correct += (decision > 0.0).item() == is_pos_.item() loss = weight_loss_seg * loss_seg + weight_loss_dec * loss_dec # 对结果进行加权 else: loss_dec = criterion_dec(decision, is_pos_) total_loss_dec += loss_dec.item() total_correct += (decision > 0.0).item() == is_pos_.item() loss = weight_loss_dec * loss_dec

 浙公网安备 33010602011771号
浙公网安备 33010602011771号