我们进行了两部分的实验:
1:提取特征重要性之和大于95%的前5个特征,进行结果的预测,并统计时间
直接使用特征进行结果的预测,统计时间
2:在上述的基础上,研究了少量数据集所花的时间,以及精度的差异
代码:
第一步:数据读取
第二步:pd.dummies() 对文本标签进行one-hot编码
第三步:提取特征和标签
第四步:将特征和标签分为训练集和验证集
第五步:建立模型对数据进行预测,并统计时间
第六步:对特征重要性进行排序,选择出重要性最大的前5个特征
第七步:对提取出的特征进行训练和预测,统计时间
第八步:对原始的数据进行训练和测试,统计时间
第九步:画出时间,错误,准确度三者的条形图
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor import time # 第一步读取数据 data = pd.read_csv('data/temps_extended.csv') # 第二步:对文本标签使用one-hot编码 data = pd.get_dummies(data) # 第三步:提取特征和标签 X = data.drop('actual', axis=1) feature_names = np.array(X.columns) y = np.array(data['actual']) X = np.array(X) # 第四步:使用train_test_split进行样本的拆分 train_x, test_x, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=42) # 第五步:建立模型进行预测 start_time = time.time() rf = RandomForestRegressor(random_state=42, n_estimators=1000) rf.fit(train_x, train_y) pre_y = rf.predict(test_x) time_extend = time.time() - start_time print(time_extend) # MSE mse = round(abs(pre_y - test_y).mean(), 2) error = abs(pre_y - test_y).mean() # MAPE mape = round(((1 - abs(pre_y - test_y) / test_y)*100).mean(), 2) print(mse, mape) # 第六步:选取特征重要性加和达到95%的特征 # 获得特征重要性的得分 feature_importances = rf.feature_importances_ # 将特征重要性得分和特征名进行组合 feature_importances_names = [(feature_name, feature_importance) for feature_name, feature_importance in zip(feature_names, feature_importances)] # 对特征重要性进行按照特征得分进行排序 feature_importances_names = sorted(feature_importances_names, key=lambda x: x[1], reverse=True) # 获得排序后的特征名 feature_importances_n = [x[0] for x in feature_importances_names] # 获得排序后的特征重要性得分 feature_importances_v = [x[1] for x in feature_importances_names] # 画出特征重要性(已经经过排序)的条形图 plt.style.use('fivethirtyeight') plt.bar(range(len(feature_importances_n)), feature_importances_v, orientation='vertical') plt.xticks(range(len(feature_importances_n)), feature_importances_n, rotation='vertical') plt.show() # 将特征重要性进行加和做plot图 feature_importances_v_add = np.cumsum(feature_importances_v) plt.style.use('fivethirtyeight') figure = plt.figure() plt.plot(feature_importances_n, feature_importances_v_add, 'r-') plt.plot(feature_importances_n, [0.95 for x in range(len(feature_importances_n))], 'b--') plt.xticks(rotation=90) plt.show() # 使用np.where找出第几个特征下,特征的重要性大于95 little_feature_name = feature_importances_n[:np.where([feature_importances_v_add > 0.95])[1][0]+1] # 第七步:使用选取的特征做训练和预测并统计时间 X = data[little_feature_name].values y = data['actual'].values # 使用train_test_split进行样本的拆分 train_x, test_x, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=42) # 建立模型进行预测 start_time = time.time() rf = RandomForestRegressor(random_state=42, n_estimators=1000) rf.fit(train_x, train_y) pre_y = rf.predict(test_x) little_time = time.time() - start_time # MSE mse_little = round(abs(pre_y - test_y).mean(), 2) # MAPE mape_little = round(((1 - abs(pre_y - test_y) / test_y)*100).mean(), 2) print(mse_little, mape_little) little_error = abs(pre_y - test_y).mean() descrese_time = abs((little_time - time_extend) / time_extend) print(descrese_time) decrese_accuraccy = abs((mape_little - mape) / mape_little) result_pd = pd.DataFrame({'feature':['all', 'P-5'], 'error':[error, little_error], 'time':[time_extend, little_time]}) print(result_pd)
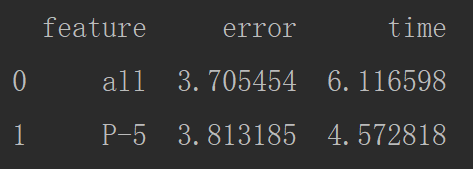
不同的特征个数的对比图
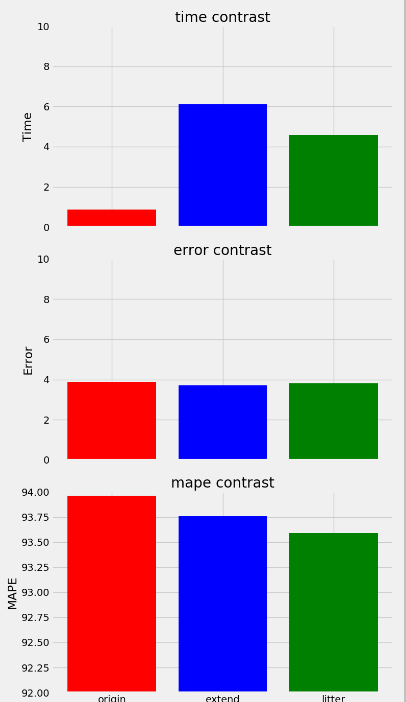
# 使用原来的数据进行计算 data = pd.read_csv('data/temps.csv') # 对文本标签使用one-hot编码 data = pd.get_dummies(data) # 提取特征和标签 X = data.drop('actual', axis=1) y = np.array(data['actual']) X = np.array(X) # 使用train_test_split进行样本的拆分 train_x, test_x, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=42) # 建立模型进行预测 start_time = time.time() Original_rf = RandomForestRegressor(random_state=42, n_estimators=1000) Original_rf.fit(train_x, train_y) pre_y = Original_rf.predict(test_x) time_orignal = time.time() - start_time # MSE mse_original = round(abs(pre_y - test_y).mean(), 2) error_original = abs(pre_y - test_y).mean() # MAPE mape_original = round(((1 - abs(pre_y - test_y) / test_y)*100).mean(), 2) print(mse_original, mape_original) # 将时间,error和mape进行合并 Result_contrast = pd.DataFrame({'time': [time_orignal, time_extend, little_time], 'error_1': [error_original, error, little_error], 'mape': [mape_original, mape, mape_little], 'model': ['origin', 'extend', 'litter']}) # 进行画图操作 print(Result_contrast.error_1.values) fig, ((ax1, ax2, ax3)) = plt.subplots(nrows=3, ncols=1, sharex = True, figsize=(8, 14)) plt.xticks(range(0, 3), list(Result_contrast['model']), ) ax1.bar(range(0, 3), Result_contrast['time'], color=['red', 'blue', 'green']) ax1.set_ylim(bottom=0, top=10); ax1.set_ylabel('Time'); ax1.set_title('time contrast') ax2.bar(range(0, 3), Result_contrast['error_1'], color=['red', 'blue', 'green']) ax2.set_ylim(bottom=0, top=10); ax2.set_ylabel('Error'); ax2.set_title('error contrast') ax3.bar(range(0, 3), Result_contrast['mape'], color=['red', 'blue', 'green']) ax3.set_ylim(bottom=92, top=94); ax3.set_ylabel('MAPE'); ax3.set_title('mape contrast') plt.tight_layout(h_pad=2) plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号