

[java-project-gl]压力测试和性能优化
压力测试和性能优化
压力测试
压力测试考察当前软硬件环境下系统所能承受的最大负荷并帮助找出系统瓶颈所在。压测都是为了系统在线上的处理能力和稳定性维持在一个标准范围内,做到心中有数。
使用压力测试,我们有希望找到很多种用其他测试方法更难发现的错误。有两种错误类型是:内存泄漏,并发与同步。
有效的压力测试系统将应用以下这些关键条件:重复,并发,量级,随机变化。
性能指标
- 响应时间(Response Time: RT)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。
- HPS (Hits Per Second) :每秒点击次数,单位是次秒。
- TPS (Transaction per Second);,系統每秒处理交易数,单位是笔秒。
- OPS (Query per Second) :系统每秒处理查询次数,单位是次秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么TPS-QPS-HPS,一般情况下用TPS来衡量整个业务流程,用QPS来衡量接口查询次数,用HPS来表示对服务器单击请求。
- 无论TPS. QPS. HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
金融行业: 1000TPS-50000TPs,不包括互联网化的活动
保险行业: 100TPS-100000Tps. 包括互联网化的活动
制造行业: 10TPS-5000TPS
互联网电子商务: 1000OTPS-1000000TPS
互联网中型网站: 1000TPS-50000TPS
互联网小型网站: 500TPS~1000TPS
-
最大响应时间(Max Resonse Time,指用户发出请求或者指令到系统做出反应(响应)的最大时间。
-
最少响应时间(Mininum RespanseTime)指用户发出请求或者指令到系统做出反应(响应)的最少时间。
-
90%响应时间(90% Response Time) 是指所有用户的响应时间进行排序,第90%的响应时间。
-
从外部看,性能测试主要关注如下三个指标
吞吐量;每秒钟系统能够处理的请求数、任务数. 响应时间:服务处理一个请求或一个任务的耗时。 错误率:一批请求中结果出错的请求所占比例。
JMeter
JMeter安装
下载页:http://jmeter.apache.org/download_jmeter.cgi
下载对应的压缩包,解压运行bin下的jmeter.bat即可

打开修改中文

添加线程组模拟用户

模拟200个用户1s内启动,循环100次,即20000个请求

添加http请求

请求百度

添加查看结果树,汇总报告

请求项目测试
JMeter Address Already in use错误解决
这个因电脑而异,我的电脑默认已经是这个设置了
windows本身提供的端口访问机制的问题。
Windows提供给TCP/IP错接的端口为1024-5000,并且要四分钟来循环回收他们。就导致我们在短时间内跑大量的请求时将端口占落了.
1.cmd中,用regedit命令打开注册表
2在 HKEY LOCAL MACHINESYSTEM\CurrentControlSet\Services\Ticpip\lParameters 下,
1、右击parameters,添加一个新的DWORD.名字为MaxUserPort
2、然后双击MaxUserPort,输入数值数据为65534,基数选择十进制(如果是分布式运行的话,控制机器和负载机器都需要这样操作哦)
3、30s即回收端口 TCPTimedWaitDelay: 30
3,修改配置完毕之后记得重启机器才会生效
jconsole与jvisualvm
Jdk的两个小工具console visulvm (升级版的consoke),通过命令行启动,可监控本地和远程应用.远程应用需要配置
参考:使用步骤
前言
Java VisualVM是jdk自带一款工具,可以十分友好的监控java进程相关的应用服务及中间件。
工具位置
jdk的bin目录下,找到jvisualvm.exe,双击打开即可。
自己的电脑没带这个,下载地址:https://visualvm.github.io/releases.html
下载完解压直接把整个文件放到JDK的bin目录下即可
功能介绍
1、抽样器和profiler,这两个差不多,用其中一个即可。

比如抽样器,点击CPU,就可以看到各个类以及方法执行的时间,可以监控哪个类的方法执行时间较长,一眼就能定位到具体的异常方法。

点击内存,也一样,很直观的就能找到哪个位置可能存在内存泄漏的情况。

2、安装visualGC插件
直接在java visualVM上安装是安装不上的,要去官网下载插件。
地址:https://visualvm.github.io/pluginscenters.html
java -version查一下java版本,然后根据版本下载对应的插件。


然后点击工具-插件,将地址改为正确的地址:

然后就可以安装插件了,勾选可用插件中的这两个:BTrace Workbench和Visual GC

点击安装即可。
装完后:

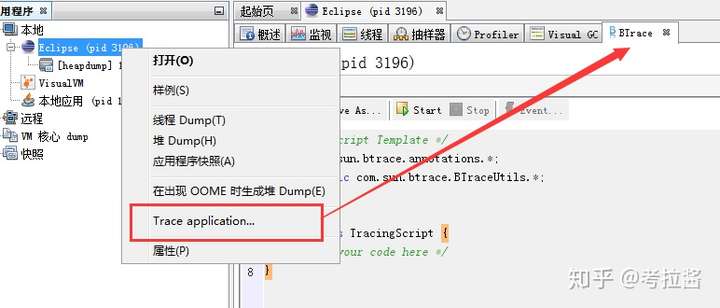
3、JVisualVM监控tomcat(在第2点的基础上)
1)、配置要监控的远程tomcat中的catalina.sh文件,加入以下部分:
找到JAVA_OPTS,在上方加入:(主要是端口port和主机hostname,记住端口不要和服务器上已经占用的发生冲突,如果是云服务器要开放端口。)
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9004 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.net.preferIPv4Stack=true -Djava.rmi.server.hostname=39.108.70.86"

保存,重启。
2)、远程-右键,添加主机:

添加jmx连接:


然后就和监控本地一样了!
总结:
个人经过测试,监控内网服务器没问题,但是阿里云服务器远程连接会报错:【无法使用 service:jmx:rmi:///jndi/rmi:///jmxrmi 连接到9004】,这是因为云服务器自己的安全策略阻挡了远程监控,所以VisualVM最好的使用场景是远程监控局域网内的服务器。
- SQL耗时越小越好,一般情况下微秒级别.
- 命中率越高越好,一般情况下不能低于95%
- 锁等待次数越低越好,等待时间越短越好。
优化
根据上面的步骤【JMeter安装】下的操作步骤,新建一个线程组,
-
线程数:50; 时间:1; 循环次数:永远
-
添加HTTP请求;协议:http; 服务器名称或者IP:192.168.109.128 ; 路径:/
-
添加查看结果树、汇总报告、聚合报告。
中间件对性能的影响
对Nginx进行测试
- 修改:服务器名称或者IP:192.168.109.128 ; 端口:80 路径:/ ;这个路径为访问虚拟机主页的地址,默认是这个不用修改

监控nginx状态
docker stats

内存消耗少。多计算、耗cpu
开启线程组,过个20-30秒停下,统计数据,从聚合报告里得到数据,填写到下面的表格中
测试数据表格:
| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 5095 | 2 | 293 |
| Gateway | ||||
| 简单服务 | ||||
| 首页一级菜单渲染 | ||||
| 首页渲染(开缓存) | ||||
| 三级分类数据获取 | ||||
| 首页全量数据获取 | ||||
| Nginx+Gateway | ||||
| Gateway 简单服务 | ||||
| 全链路 |
对Gateway进行压测,同时监控内存
- 修改:服务器名称或者IP:localhost ; 端口:88 路径:/ ;


耗cpu

伊甸园区内存小,GC频繁
-
测试结果:
压测内容 压测线程数 吞吐量/s 90%响应时间 99%响应时间 Gateway 50 11956 7 25
简单优化吞吐量测试
对简单请求进行压测
web包下的IndexController.java下,添加下面的代码
/**
* 简单请求
* @return
*/
@ResponseBody
@GetMapping("/hello")
public String hello() {
return "hello";
}
访问http://localhost:10001/hello,出现hello
- 修改:服务器名称或者IP:localhost ; 端口:10001 路径:/hello ;



测试结果:
| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| 简单服务 | 50 | 13287 | 6 | 7 |
网关+简单请求
- id: product_route
#lb 表示转发至服务 服务也需注册到nacos
uri: lb://mall-product
predicates:
#当请求为指定路径 断言为真 **代表任意 这个路径需往上写提高优先级不被/api/**给拦截
- Path=/api/product/**,/hello
filters:
#断言为真,重写路径/api/(?<segment>.*)改为/$\{segment}
#例请求http://localhost:88/api/product/category/list/tree会改为
#http://mall-product端口/product/category/list/tree
- RewritePath=/api/(?<segment>.*),/$\{segment}

- 以下测试结果,见最终下面的表格
吞吐量下降
全链路测试
修改:服务器名称或者IP:gulimall.com ; 端口:80 路径:/hello ;
测试20-30s
三级分类数据测试
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/index/catalog.json ;

首页一级菜单渲染测试
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/ ;
测试20-30s
首页一级菜单(开缓存)渲染测试
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/ ;
开缓存:
spring:
thymeleaf:
cache: true
测试20-30s
首页全量数据获取测试
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/ ;
高级:选上从HTML文件获取所有内含的数据,在选上并发下载 6
测试过程中,卡掉了,吞吐量为2
首页渲染(开缓存、优化数据库、关日志)测试
- 开缓存:
spring:
thymeleaf:
cache: true
- 关日志:
logging:
level:
com.atguigu.gulimall: error
- 优化数据库:
没加索引之前:
/**
* 1、查出所有的1级分类
* @return
*/
@Override
public List<CategoryEntity> getLevel1Categorys() {
long l = System.currentTimeMillis();
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", 0));
System.out.println("消耗时间:" + (System.currentTimeMillis()-l));
return categoryEntities;
}
访问gulimall.com
输出:
第一次访问
消耗时间:238
消耗时间:9
第二次访问
消耗时间:3
消耗时间:4
加索引:
数据库改变表结构

点击保存即可
再次访问gulimall.com
输出结果:
消耗时间:2
消耗时间:2
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/ ;
过20-30s后统计数据
三级分类数据(开缓存、优化数据库、关日志)
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/index/catalog.json ;
过20-30s后统计数据
nginx动静分离
将静态资源static包下的内容传输到nginx的html文件夹下的static文件内
[root@localhost ~]# cd /mydata/nginx/html/
[root@localhost html]# mkdir static
[root@localhost html]# cd static/
[root@localhost static]#
修改之前conf.d下的商品服务配置文件gulimall.conf,添加上规则
server {
listen 80;
server_name gulimall.com;
#charset koi8-r;
#access_log /var/log/nginx/log/host.access.log main;
location /static/ { #添加的规则
root /usr/share/nginx/html;
}
location / {
proxy_set_header Host $host;
proxy_pass http://gulimall;
}
......
}
重启nginx
docker restart nginx
注意html文件中路径应该加上static,比如
href="/static/index/css/swiper-3.4.2.min.css"
首页全量数据获取(开缓存、优化数据库、关日志、nginx动静分离)
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/ ;
高级:选上从HTML文件获取所有内含的数据,在选上并发下载 6
过20-30s后统计数据
运行内存优化
调整product项目运行内存
VM options: -Xmx1024m -Xms1024m -Xmn
-Xmx1024m:最大内存
-Xms1024m:最小内存
-Xmn512m: 伊甸园区(Eden)+幸存者区(Survivor)
模拟线上应用内存崩溃宕机情况
200个线程 并行下载6
设置vm参数:-Xmx=100m
服务崩溃:
出现这种情况就是配置运行内存不合理,需要调大运行内存参数
可以调整参数为:
-Xmx1024m -Xms1024m -Xmn512m
调整完后再看监控:
现在就好多了
不过上线期间可以这样设置,还在代码开发、调试阶段,还是需要跳到-Xmx100m
业务逻辑优化
三级分类二(开缓存、优化数据库、关日志、nginx动静分离、业务逻辑调整)
package com.atguigu.gulimall.product.service.impl;
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
/**
* 1、将数据库的多次查询变为一次
*
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
//1、查出所有1级分类
List<CategoryEntity> level1Categorys = getParent_cid(selectList,0L);
//2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList,v.getCatId());
//2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo("v.getCatId()", null, l2.getCatId().toString(), l2.getName());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList,l2.getCatId());
if(level3Catelog!=null){
List<Catelog2Vo.Catelog3Vo> collect = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
private List<CategoryEntity> getParent_cid(List<CategoryEntity> selectList,Long parent_cid) {
List<CategoryEntity> collect = selectList.stream().filter(item -> item.getParentCid() == parent_cid).collect(Collectors.toList());
return collect;
//return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
}
测试数据统计
缓存优化
引入依赖
pom.xml
<!-- 引入redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
application.yml
spring:
redis:
host: 192.168.109.128
port: 6379
项目加入缓存:
@Service("categoryService")
public class CategoryServiceImpl extends ServiceImpl<CategoryDao, CategoryEntity> implements CategoryService {
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson(){
//给缓存中放json字符串,拿出的json字符串,还能逆转为能用的对象类型;【序列化与反序列化】
//1、加入缓存逻辑,缓存中存的数据是json字符串
//JSON跨语言,跨平台兼容。
String catalogJSON = redisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)){
//2、缓存中没有,查询数据库
Map<String, List<Catelog2Vo>> catalogJsonFromDb = getCatalogJsonFromDb();
//3、查到的数据再放入缓存,将对象转为json放在缓存中
String s = JSON.toJSONString(catalogJsonFromDb); //利用fastJSON把对象转为json字符串
redisTemplate.opsForValue().set("catalogJSON",s);
return catalogJsonFromDb;
}
//转为我们制定的对象
//fastJSON,把字符串JSON按照我们要转的类型(对象),进行转换; json--->Map<String, List<Catelog2Vo>>
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON,new TypeReference<Map<String, List<Catelog2Vo>>>(){});
return result;
}
//从数据库查询并封装分类数据
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDb(){
......
}
}
这个缓存优化还不完善,在分布式缓存中章节中,会不断完善优化
三级分类数据(开缓存、优化数据库、关日志、nginx动静分离、业务逻辑调整、redis缓存)
修改:服务器名称或者IP:localhost ; 端口:10001 路径:/index/catalog.json ;
过20-30s后统计数据
测试数据表格
| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 5095 | 2 | 293 |
| Gateway | 50 | 11956 | 7 | 25 |
| 简单服务 | 50 | 13287 | 4 | 7 |
| 首页一级菜单渲染 | 50 | 684(db,thymeleaf) | 82 | 132 |
| 首页渲染(开缓存) | 50 | 770 | 74 | 113 |
| 首页渲染(开缓存、优化数据库、关日志) | 50 | 1688 | 40 | 62 |
| 三级分类数据获取 | 50 | 5(db) | ... | ... |
| 三级分类(开缓存、优化数据库、关日志) | 50 | 27(数据库加索引) | ... | ... |
| 三级分类(开缓存、优化数据库、关日志、nginx动静分离、业务逻辑调整) | 50 | 316 | ... | ... |
| 三级分类数据(开缓存、优化数据库、关日志、nginx动静分离、业务逻辑调整、redis缓存) | 50 | 748 | 82 | 106 |
| 首页全量数据获取 | 50 | 2(静态资源) | ||
| 首页全量数据获取(开缓存、优化数据库、关日志、nginx动静分离) | 50 | 44 | ||
| Nginx+Gateway | ||||
| Gateway 简单服务 | 50 | 4730 | 17 | 34 |
| 全链路 | 50 | 107 | 7 | 15044 |
中间件越多,性能损失越大,大多都损失网络交互了
由此推出:
单独网关服务,nginx,简单服务,吞吐量都很高,可是通过nginx代理到网关,然后网关路由到服务,吞吐量明显下降,可见调用链路越长,中间件越多,对性能影响越大。
性能优化从业务一般考虑如下几个方面:
1、DB(考虑sql加索引,sql优化,关日志)
2、模板渲染速度(thymeleaf线上要打开缓存,开发关闭)
3、静态资源(nginx动静分离)
4、visualvm查看GC情况,如果GC次数过多证明分配内存偏小
5、业务优化(优化掉频繁查库的操作)
6、加入redis缓存
优化三级分类数据获取
原有代码(查询了三次数据库):
/**
* 查出所有分类 返回首页json
*
* @return
*/
@Override
public Map<String, List<Catalog2Vo>> getCatalogJson() {
//先查出所有一级分类
List<CategoryEntity> level1Categorys = getLevel1Categorys();
//封装数据 map k,v 结构
Map<String, List<Catalog2Vo>> map = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> category2Entities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
List<Catalog2Vo> catelog2Vos = null;
if (category2Entities != null) {
catelog2Vos = category2Entities.stream().map(level2 -> {
//封装catalog2Vo
Catalog2Vo catalog2Vo = new Catalog2Vo(v.getCatId().toString(), null, level2.getCatId().toString(), level2.getName());
//每一个二级分类,查到三级分类
List<CategoryEntity> category3Entities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", level2.getCatId()));
if (category3Entities != null) {
List<Object> catalog3List = category3Entities.stream().map(level3 -> {
//封装catalog3Vo
Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(level2.getCatId().toString(), level3.getCatId().toString(), level3.getName());
return catalog3Vo;
}).collect(Collectors.toList());
//封装catalog3Vo到catalog2Vo
catalog2Vo.setCatalog3List(catalog3List);
}
return catalog2Vo;
}).collect(Collectors.toList());
}
//返回v=catalog2Vo
return catelog2Vos;
}));
return map;
}
应该第一次查询出来所有,后面拿查询出来的去操作
优化后:
/**
* 根据传进分类筛选出对应级别
*
* @param list
* @param parent_cid
* @return
*/
public List<CategoryEntity> getCategorys(List<CategoryEntity> list, Long parent_cid) {
List<CategoryEntity> collect = list.stream().filter(l -> parent_cid.equals(l.getParentCid())).collect(Collectors.toList());
return collect;
}
/**
* 查出所有分类 返回首页json
*
* @return
*/
@Override
public Map<String, List<Catalog2Vo>> getCatalogJson() {
//查询出所有分类
List<CategoryEntity> selectList = baseMapper.selectList(null);
//先查出所有一级分类
List<CategoryEntity> level1Categorys = getCategorys(selectList, 0L);
//封装数据 map k,v 结构
Map<String, List<Catalog2Vo>> map = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> category2Entities = getCategorys(selectList, v.getCatId());
List<Catalog2Vo> catelog2Vos = null;
if (category2Entities != null) {
catelog2Vos = category2Entities.stream().map(level2 -> {
//封装catalog2Vo
Catalog2Vo catalog2Vo = new Catalog2Vo(v.getCatId().toString(), null, level2.getCatId().toString(), level2.getName());
//每一个二级分类,查到三级分类
List<CategoryEntity> category3Entities = getCategorys(selectList, level2.getCatId());
if (category3Entities != null) {
List<Object> catalog3List = category3Entities.stream().map(level3 -> {
//封装catalog3Vo
Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(level2.getCatId().toString(), level3.getCatId().toString(), level3.getName());
return catalog3Vo;
}).collect(Collectors.toList());
//封装catalog3Vo到catalog2Vo
catalog2Vo.setCatalog3List(catalog3List);
}
return catalog2Vo;
}).collect(Collectors.toList());
}
//返回v=catalog2Vo
return catelog2Vos;
}));
return map;
}
[大型网站高性能架构](http://plusaber.com/2015/11/21/System Design_大型网站高性能架构c4/)
转载自:https://blog.csdn.net/D_A_I_H_A_O/article/details/106483398


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2020-03-09 人形词云,根据图片黑白形状绘制词云
2020-03-09 汉化的simple词云
2020-03-09 对于数据的平均值处理
2020-03-09 文字替换成函数返回数字进行排序
2020-03-09 校验
2020-03-09 Python:使用lambda对列表(list)和字典(dict)排序
2020-03-09 python中的数据排序