RabbitMQ
使用docker 下载 镜像docker pull rabbitmq:management
创建容器
docker run -d --name rabbitmq --publish 5671:5671 --publish 5672:5672 --publish 4369:4369 --publish 25672:25672 --publish 15671:15671 --publish 15672:15672 --restart unless-stopped \rabbitmq:management
RabbitMQ是实现AMQP(Advanced Message Queuing Protocol高级消息队列协议)的消息中间件 主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用 启动默认端口5672
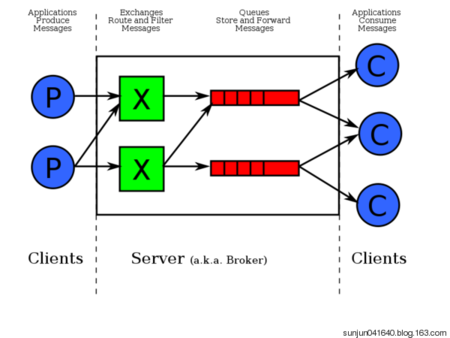
- 左侧 P 代表 生产者,也就是往 RabbitMQ 发消息的程序。
- 中间即是 RabbitMQ,_其中包括了 交换机 和 队列。
- 右侧 C 代表 消费者,也就是往 RabbitMQ 拿消息的程序。
- 虚拟主机:一个虚拟主机持有一组交换机、队列和绑定。为什么需要多个虚拟主机呢?很简单,RabbitMQ当中,_用户只能在虚拟主机的粒度进行权限控制。_ 因此,如果需要禁止A组访问B组的交换机/队列/绑定,必须为A和B分别创建一个虚拟主机。每一个RabbitMQ服务器都有一个默认的虚拟主机“/”。
- 交换机:_Exchange 用于转发消息,但是它不会做存储_ ,如果没有 Queue bind 到 Exchange 的话,它会直接丢弃掉 Producer 发送过来的消息。
- 这里有一个比较重要的概念:**路由键 ** 。消息到交换机的时候,交互机会转发到对应的队列中,那么究竟转发到哪个队列,就要根据该路由键。
- 绑定:也就是交换机需要和队列相绑定,这其中如上图所示,是多对多的关系。
什么是交换机
rabbitmq的message model实际上消息不直接发送到queue中,中间有一个exchange是做消息分发,producer甚至不知道消息发送到那个队列中去。因此,当exchange收到message时,必须准确知道该如何分发。是append到一定规则的queue,还是append到多个queue中,还是被丢弃?
它的职责是把message路由到不同的queue中。
交换机的功能主要是接收消息并且转发到绑定的队列,交换机不存储消息,在启用ack模式后,交换机找不到队列会返回错误。交换机有四种类型:Direct, topic, Headers and Fanout
- Direct:direct 类型的行为是”先匹配, 再投送”. 即在绑定时设定一个 routing_key, 消息的routing_key 匹配时, 才会被交换器投送到绑定的队列中去.
- Topic:按规则转发消息(最灵活)
- Headers:设置header attribute参数类型的交换机
- Fanout:转发消息到所有绑定队列
Direct Exchange 根据key全文匹配去寻找队列

Topic Exchange
rabbitTemplate.convertAndSend("testTopicExchange","key1.a.c.key2", " this is RabbitMQ!");
Headers Exchange
headers 也是根据规则匹配, 相较于 direct 和 topic 固定地使用 routing_key , headers 则是一个自定义匹配规则的类型. 在队列与交换器绑定时, 会设定一组键值对规则, 消息中也包括一组键值对( headers 属性), 当这些键值对有一对, 或全部匹配时, 消息被投送到对应队列.
Fanout Exchange
Fanout Exchange 消息广播的模式,不管路由键或者是路由模式,会把消息发给绑定给它的全部队列,如果配置了routing_key会被忽略。
简单应用
<dependency> <groupId>com.rabbitmq</groupId> <artifactId>amqp-client</artifactId> <version>3.6.5</version> </dependency>
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("127.0.0.1");
factory.setPort(5672);
factory.setUsername("guest");
factory.setPassword("guest");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare("mxz", false, false, false, null);
http://localhost:15672/#/queues 已经创建了一个队列
发送消息
//第一个参数便是指定交换机的名字 第二个参数是路由键 相当于队列的名字 每一个被创建的队列都会被自动的绑定到默认交换机上,并且路由键就是队列的名字
channel.basicPublish("", "mxz", null, "I am mxz".getBytes());

从channel 中读取 ;第二个参数表示是否自动确认消息的接收情况
channel.basicConsume("mxz", new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println(new String(body, "UTF-8"));
}
});
synchronized (this){
// 因为以上接收消息的方法是异步的(非阻塞),当采用单元测试方式执行该方法时,程序会在打印消息前结束,因此使用wait来防止程序提前终止。若使用main方法执行,则不需要担心该问题。
wait();
}
此时查看Queue已经空了
- 一条消息只会被一个消费者接收;
- 消息是平均分配给消费者的;
- 消费者只有在处理完某条消息后,才会收到下一条消息。
- 事实上,RabbitMQ会循环地(一个接一个地)发送消息给消费者,这种分配消息的方式被称为round-robin(轮询)
消息确认
由于worker(消费者)执行任务需要一定的时间(以上用sleep模拟),要是某个worker在运行过程中挂掉,那分配给它的任务岂不是丢失了(永远不可能被执行了)。为解决这个问题,RabbitMQ提供了消息确认机制,即worker需要主动的去确认消息已经接收了,RabbitMQ才认为消息被“真正地接收了”,
// send的代码不用变,只需改变basicConsume的第二个参数为false,表示不要自动确认 channel.basicConsume("hello", false, new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { System.out.println(new String(body, "UTF-8")); try { // 这里把时间加长了一点便于测试 Thread.sleep(8000); } catch (InterruptedException e) { e.printStackTrace(); }finally { // 这里手动地确定 channel.basicAck(envelope.getDeliveryTag(), false); } } });
消息没有被确认而被重新归还到Ready中
消息持久化
RabbitMQ一旦关闭 队列就没了
可以先从 Connection 对象中拿到一个 Channel 信道对象,然后再可以通过该对象设置 消息持久化
// 将第二个参数设为true,表示声明一个需要持久化的队列。 // 需要注意的是,若你已经定义了一个非持久的,同名字的队列,要么将其先删除(不然会报错),要么换一个名字。 channel.queueDeclare("hello", true, false, false, null);
// 修改了第三个参数,这是表明消息需要持久化 channel.basicPublish("", "mxz", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());
Publish/Subscribe fanout类型
先创建一个fanout类型的交换机。
//第一个参数是交换机的名称;第二个参数是交换机的类型。
channel.exchangeDeclare("notice", "fanout");
channel.basicPublish( "notice", "", null, message.getBytes());
对于消费者,我们需要为每一个消费者创建一个独立的队列,然后将队列绑定到刚才指定的交换机上即可:
// 该方法会创建一个名称随机的临时队列 String queueName = channel.queueDeclare().getQueue(); // 将队列绑定到指定的交换机("notice")上 第三个参数routingkey channel.queueBind(queueName, "notice", "");
Routing 声明
channel.exchangeDeclare("notice2", "direct");
消费者
channel.exchangeDeclare("notice2", "direct");
String queueName = channel.queueDeclare().getQueue();
// queue name, exchange , routing key
channel.queueBind(queueName, "notice2", "n");
在Topics模型中,我们“升级”了routing key,它可以由多个关键词组成,词与词之间由点号(.)隔开。特别地,规定*表示任意的一个词;#号表示任意的0个或多个词。
springboot集成RabbitMQ
1. pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2. 配置文件
spring.application.name=spirng-boot-rabbitmq spring.rabbitmq.host=192.168.0.86 spring.rabbitmq.port=5672 spring.rabbitmq.username=admin spring.rabbitmq.password=123456
3.队列配置
@Configuration public class RabbitConfig { @Bean public Queue Queue() { return new Queue("hello"); } }
4.发送者
public class HelloSender { @Autowired private AmqpTemplate rabbitTemplate; public void send() { String context = "hello " + new Date(); System.out.println("Sender : " + context); this.rabbitTemplate.convertAndSend("hello", user); } }
5.接收者
@Component @RabbitListener(queues = "hello") public class HelloReceiver { @RabbitHandler public void process(User user) { System.out.println("Receiver : " + user); } }
Topic Exchange
@Configuration public class TopicRabbitConfig { final static String message = "topic.message"; final static String messages = "topic.messages"; @Bean public Queue queueMessage() { return new Queue(TopicRabbitConfig.message); } @Bean public Queue queueMessages() { return new Queue(TopicRabbitConfig.messages); } @Bean TopicExchange exchange() { return new TopicExchange("exchange"); } @Bean Binding bindingExchangeMessage(Queue queueMessage, TopicExchange exchange) { return BindingBuilder.bind(queueMessage).to(exchange).with("topic.message"); } @Bean Binding bindingExchangeMessages(Queue queueMessages, TopicExchange exchange) { return BindingBuilder.bind(queueMessages).to(exchange).with("topic.#"); } }
topic 和 direct 类似, 只是匹配上支持了”模式”, 在”点分”的 routing_key 形式中, 可以使用两个通配符:
*表示一个词.#表示零个或多个词.
- @EnableRabbit:@EnableRabbit 和 @configuration 注解在一个类中结合使用,如果该类能够返回一个 RabbitListenerContainerFactory 类型的 bean,那么就相当于能够把该终端(消费端)和 RabbitMQ 进行连接。Ps:(生成端不是通过 RabbitListenerContainerFactory 来和 RabbitMQ 连接,而是通过 RabbitTemplate )
- @RabbitListener:当对应的队列中有消息的时候,该注解修饰下的方法会被执行。
- @RabbitHandler:接收者可以监听多个队列,不同的队列消息的类型可能不同,该注解可以使得不同的消息让不同方法来响应。
自定义代码配置connectionfactory
@Bean ConnectionFactory connectionFactory() { CachingConnectionFactory connectionFactory = new CachingConnectionFactory(host, port); connectionFactory.setUsername(userName); connectionFactory.setPassword(password); connectionFactory.setVirtualHost(vhost); return connectionFactory; }
@Bean(name="myTemplate") RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) { RabbitTemplate template = new RabbitTemplate(connectionFactory); template.setMessageConverter(integrationEventMessageConverter()); template.setExchange(exchangeName); return template; }
在该代码中,new RabbitTemplate(connectionFactory); 设置了生产端连接到RabbitMQ,template.setMessageConverter(integrationEventMessageConverter()); 设置了 生产端发送给交换机的消息是以什么格式的,在 integrationEventMessageConverter() 代码中:
public MessageConverter integrationEventMessageConverter() { Jackson2JsonMessageConverter messageConverter = new Jackson2JsonMessageConverter(); return messageConverter; }
对于消费端,我们可以只创建 SimpleRabbitListenerContainerFactory,它能够帮我们生成 RabbitListenerContainer,然后我们再使用 @RabbitListener 指定接收者收到信息时处理的方法。
@Bean(name="myListenContainer") public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory() { SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory(); factory.setMessageConverter(integrationEventMessageConverter()); factory.setConnectionFactory(connectionFactory()); return factory; }
生产者或者消费者断线重连
这里 Spring 有自动重连机制。
ACK 确认机制
每个Consumer可能需要一段时间才能处理完收到的数据。如果在这个过程中,Consumer出错了,异常退出了,而数据还没有处理完成,那么 非常不幸,这段数据就丢失了。因为我们采用no-ack的方式进行确认,也就是说,每次Consumer接到数据后,而不管是否处理完 成,RabbitMQ Server会立即把这个Message标记为完成,然后从queue中删除了。
如果一个Consumer异常退出了,它处理的数据能够被另外的Consumer处理,这样数据在这种情况下就不会丢失了(注意是这种情况下)。
为了保证数据不被丢失,RabbitMQ支持消息确认机制,即acknowledgments。为了保证数据能被正确处理而不仅仅是被Consumer收到,那么我们不能采用no-ack。而应该是在处理完数据后发送ack。
在处理数据后发送的ack,就是告诉RabbitMQ数据已经被接收,处理完成,RabbitMQ可以去安全的删除它了。
如果Consumer退出了但是没有发送ack,那么RabbitMQ就会把这个Message发送到下一个Consumer。这样就保证了在Consumer异常退出的情况下数据也不会丢失。
尝试不使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号