查找
date: 2018-11-18 11:13:09
updated: 2018-11-18 11:13:09
查找
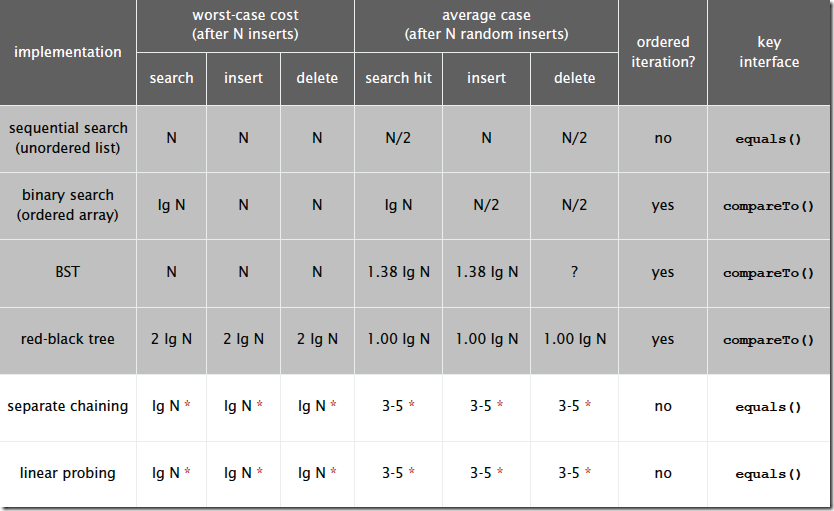
1. 顺序查找(线性查找)
时间复杂度为O(n)
说明:适合于存储结构为顺序存储或链式存储的线性表
2. 折半查找(二分查找)
时间复杂度为O(logn)
说明:折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,折半查找能得到不错的效率。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。
3. 插值查找(折半查找的优化)
时间复杂度O(log(logn))
折半查找这种查找方式,不是自适应的(也就是说是傻瓜式的)。二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
通过类比,我们可以将查找的点改进为如下:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low)
也就是将上述的比例参数1/2改进为自适应的,根据关键字在整个有序表中所处的位置,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
4. 树表查找
4.1 二叉树查找算法
复杂度分析:插入和查找时间复杂度O(logn),但在最坏的情况下【比如一棵斜线形状的树,查找最后一个节点】有O(n)的时间复杂度
基本思想:二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree)或者是一棵空树,或者是具有下列性质的二叉树:
1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2)若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3)任意节点的左、右子树也分别为二叉查找树。
二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。
基于二叉查找树进行优化,进而可以得到其他的树表查找算法,如平衡树、红黑树等高效算法。
4.2 平衡查找树之2-3查找树
2-3查找树定义:和二叉树不一样,2-3树运行每个节点保存1个或者两个的值。对于普通的2节点(2-node),他保存1个key和左右两个节点。对应3节点(3-node),保存两个Key,2-3查找树的定义如下:
1)要么为空,要么:
2)对于2节点,该节点保存一个key及对应value,以及两个指向左右节点的节点,左节点也是一个2-3节点,所有的值都比key要小,右节点也是一个2-3节点,所有的值比key要大。
3)对于3节点,该节点保存两个key及对应value,以及三个指向左中右的节点。左节点也是一个2-3节点,所有的值均比两个key中的最小的key还要小;中间节点也是一个2-3节点,中间节点的key值在两个跟节点key值之间;右节点也是一个2-3节点,节点的所有key值比两个key中的最大的key还要大。
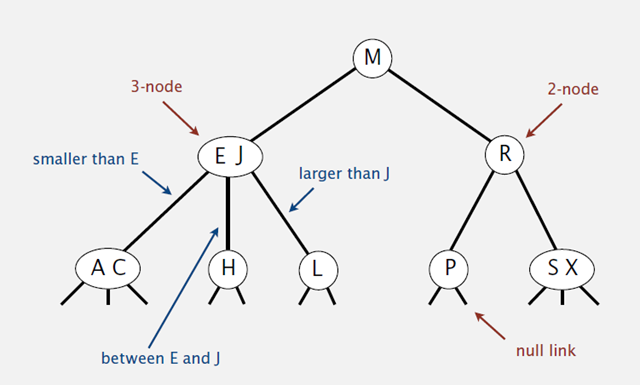
2-3查找树的性质:
1)如果中序遍历2-3查找树,就可以得到排好序的序列;
2)在一个完全平衡的2-3查找树中,根节点到每一个为空节点的距离都相同。(这也是平衡树中“平衡”一词的概念,根节点到叶节点的最长距离对应于查找算法的最坏情况,而平衡树中根节点到叶节点的距离都一样,最坏情况也具有对数复杂度。)
性质2)如下图所示:
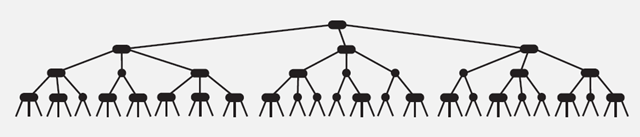
复杂度分析:
2-3树的查找效率与树的高度是息息相关的。
在最坏的情况下,也就是所有的节点都是2-node节点,查找效率为lgN
在最好的情况下,所有的节点都是3-node节点,查找效率为log3N约等于0.631lgN
距离来说,对于1百万个节点的2-3树,树的高度为12-20之间,对于10亿个节点的2-3树,树的高度为18-30之间。
对于插入来说,只需要常数次操作即可完成,因为他只需要修改与该节点关联的节点即可,不需要检查其他节点,所以效率和查找类似。
4.3 平衡查找树之红黑树
2-3查找树能保证在插入元素之后能保持树的平衡状态,最坏情况下即所有的子节点都是2-node,树的高度为lgn,从而保证了最坏情况下的时间复杂度。但是2-3树实现起来比较复杂,于是就有了一种简单实现2-3树的数据结构,即红黑树(Red-Black Tree)。
基本思想:
红黑树的思想就是对2-3查找树进行编码,尤其是对2-3查找树中的3-nodes节点添加额外的信息。红黑树中将节点之间的链接分为两种不同类型,红色链接,他用来链接两个2-nodes节点来表示一个3-nodes节点。黑色链接用来链接普通的2-3节点。特别的,使用红色链接的两个2-nodes来表示一个3-nodes节点,并且向左倾斜,即一个2-node是另一个2-node的左子节点。这种做法的好处是查找的时候不用做任何修改,和普通的二叉查找树相同。
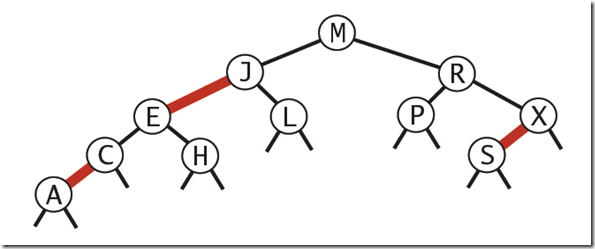
红黑树的定义:
红黑树是一种具有红色和黑色链接的平衡查找树,同时满足:
1)红色节点向左倾斜
2)一个节点不可能有两个红色链接
整个树完全黑色平衡,即从根节点到所以叶子结点的路径上,黑色链接的个数都相同。
下图可以看到红黑树其实是2-3树的另外一种表现形式:如果我们将红色的连线水平绘制,那么他链接的两个2-node节点就是2-3树中的一个3-node节点了。
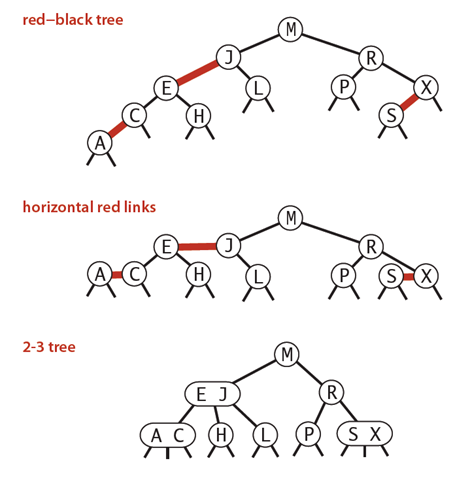
红黑树的性质:整个树完全黑色平衡,即从根节点到所以叶子结点的路径上,黑色链接的个数都相同(2-3树的第2)性质,从根节点到叶子节点的距离都相等)。
复杂度分析:最坏的情况就是,红黑树中除了最左侧路径全部是由3-node节点组成,即红黑相间的路径长度是全黑路径长度的2倍。
下图是一个典型的红黑树,从中可以看到最长的路径(红黑相间的路径)是最短路径的2倍:
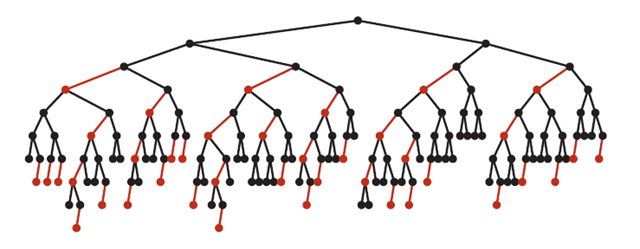
红黑树的平均高度大约为logn。
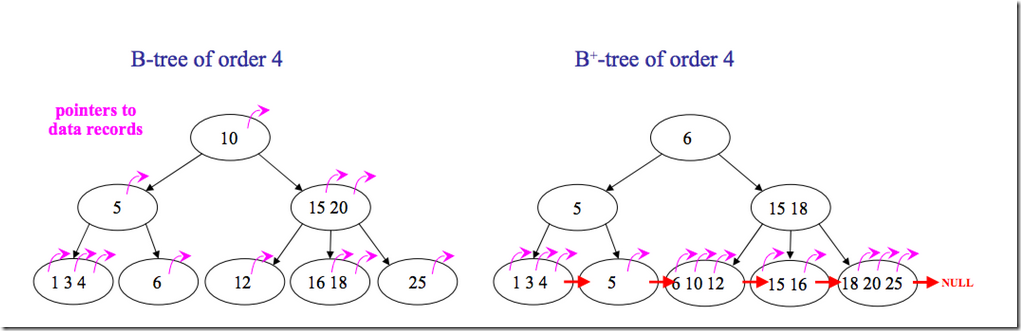
4.4 B树和B+树(B Tree/B+ Tree)
平衡查找树中的2-3树以及其实现红黑树。2-3树种,一个节点最多有2个key,而红黑树则使用染色的方式来标识这两个key。
维基百科对B树的定义为“在计算机科学中,B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。
B树定义:
B树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
1)根节点至少有两个子节点
2)每个节点有M-1个key,并且以升序排列
3)位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
4)其它节点至少有M/2个子节点
下图是一个M=4 阶的B树:
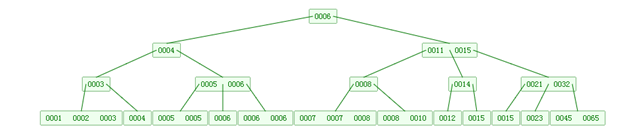
可以看到B树是2-3树的一种扩展,他允许一个节点有多于2个的元素。B树的插入及平衡化操作和2-3树很相似,这里就不介绍了。下面是往B树中依次插入
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
的演示动画:

B+树定义:
B+树是对B树的一种变形树,它与B树的差异在于:
有k个子结点的结点必然有k个关键码;
非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
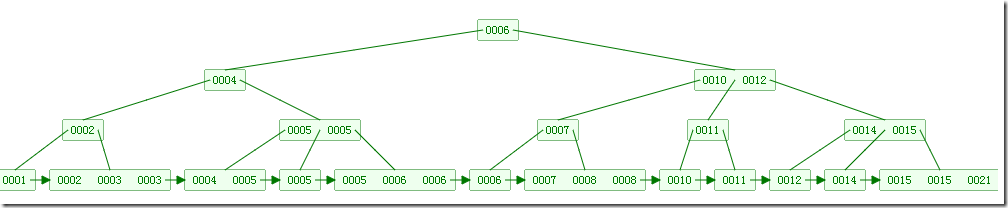
如下图,是一个B+树:
下图是B+树的插入动画:

B和B+树的区别在于,B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
B+ 树的优点在于:
1)由于B+树在内部节点上不好含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子几点上关联的数据也具有更好的缓存命中率。
2)B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
但是B树也有优点,其优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
下面是B 树和B+树的区别图:
5. 分块查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法。
算法思想:将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……
算法流程:
step1 先选取各块中的最大关键字构成一个索引表;
step2 查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;
然后,在已确定的块中用顺序法进行查找。
6. 哈希查找
哈希表的两大特点:"直接定址"与"解决冲突"。
哈希函数的规则是:通过某种转换关系,使关键字适度的分散到指定大小的的顺序结构中,越分散,则以后查找的时间复杂度越小,空间复杂度越高。
算法思想:哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
算法流程:
1)用给定的哈希函数构造哈希表;
2)根据选择的冲突处理方法解决地址冲突;
常见的解决冲突的方法:拉链法和线性探测法。
3)在哈希表的基础上执行哈希查找。
哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。哈希表使用了适度的时间和空间来在这两个极端之间找到了平衡。只需要调整哈希函数算法即可在时间和空间上做出取舍。
复杂度分析:
单纯论查找复杂度:对于无冲突的Hash表而言,查找复杂度为O(1)(注意,在查找之前我们需要构建相应的Hash表)。