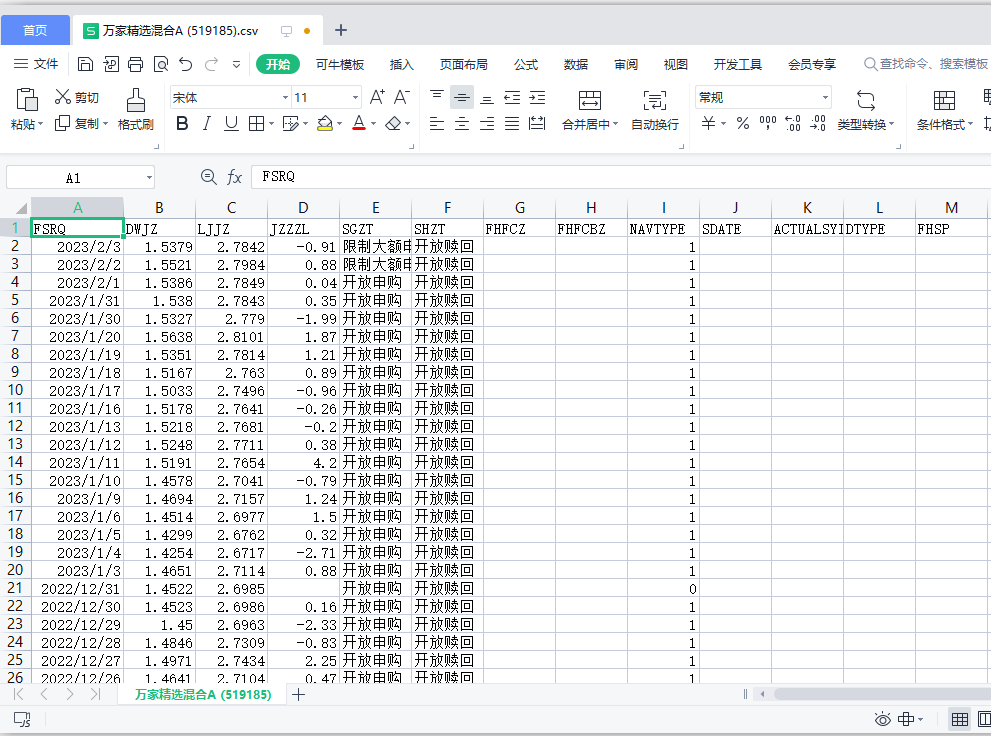
17.爬取天天基金中万家精选混合A (519185)的净值数据
1 # 爬虫 2 # 该项目是爬取天天基金网某只基金的净值数据 3 4 # 1.引入包 5 # 网络请求 6 import json 7 8 import requests 9 # 正则 10 import re 11 # 数据分析工具 12 import pandas as pd 13 14 # 定义一个空的列表,存放每一页的数据 15 df_list = [] 16 # for循环用来获取不同页码的数据,这里循环10次 17 for index in range(1, 10): 18 # 2.请求的url地址或者接口,页面数使用花括号占位 19 url = "http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18306600264369919882_1675428357095&fundCode=519185&pageIndex={}&pageSize=20&startDate=&endDate=&_=1675428744359".format(index) 20 21 # 3.请求所需要的请求头内容 22 headers = { 23 "Host":"api.fund.eastmoney.com", 24 # 防盗链 确定访问来路是否非法 25 "Referer":"http://fundf10.eastmoney.com/", 26 # 身份验证,模拟浏览器发出 27 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76" 28 } 29 30 # 4.发送请求 31 resp = requests.get(url, headers=headers) 32 33 # 5.打印获取的数据 34 data = resp.text 35 print(data) 36 37 38 # 6.通过正则表达式获取只想要的数据 39 data = re.findall("\((.*?)\)", data) 40 print(data) 41 42 # 7.将数据转换成json格式 43 data = json.loads(data[0])["Data"]["LSJZList"] 44 print(data) 45 46 # 8.使用pandas格式化数据 47 df = pd.DataFrame(data) 48 # print(df) 49 50 # 9.将每一页数据添加到列表中 51 df_list.append(df) 52 53 # 10.打印列表中的所有数据 54 # print(df_list) 55 56 # 11.合并列表中的数据 57 df_data = pd.concat(df_list) 58 print(df_data) 59 60 # 12.将数据保存到csv中,行号不保存 61 df_data.to_csv("万家精选混合A (519185).csv",index=False)
csv保存后的样子: