1 # encoding:utf-8
2
3 from tkinter import *
4 from tkinter import messagebox
5 from tkinter import filedialog
6 import pandas as pd
7 '''
8 画图形界面,供user操作
9 界面功能:
10 1.USER选择类型:BC1,MBM
11 2.USER导入EXCEL
12 3.点击数据处理,生成处理后的excel
13 '''
14
15 class OpenMyXLS(Frame):
16 def __init__(self, master=None):
17 super().__init__(master)
18 self.master = master
19 self.pack()
20 self.openxls()
21
22 def openxls(self):
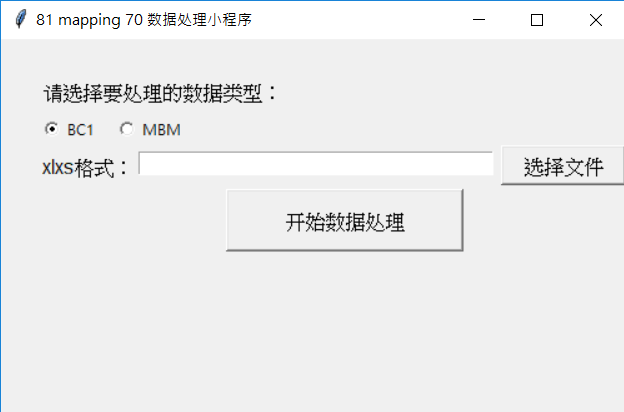
23 #创建一个标签:请选择数据处理类型
24 self.lab1 = Label(root, text="请选择要处理的数据类型:", font=("Arial", 12))
25 self.lab1.place(x=30, y=30)
26 #创建两个单选框:BC1,MLB
27
28 self.var = StringVar()
29 self.strPath = StringVar()
30 self.var.set("BC1")
31 self.radb1 = Radiobutton(root, text='BC1', value="BC1", variable=self.var, command=self.songhua)
32 self.radb1.place(x=30, y=60)
33 self.radb2 = Radiobutton(root, text='MBM', value="MBM", variable=self.var, command=self.songhua)
34 self.radb2.place(x=90, y=60)
35 #创建一个文本选择框(文本,输入框,按钮)
36 self.lab2 = Label(root, text="xlxs格式:", font=("Arial", 12))
37 self.lab2.place(x=30, y=90)
38 self.ent = Entry(root, width=40, textvariable=self.strPath)
39 self.ent.place(x=110, y=90)
40 self.bt1 = Button(root, text="选择文件", font=("Arial", 12), width=10, height=1, command=self.pathCallBack)
41 self.bt1.place(x=400, y=85)
42
43 # 选择文件夹
44 #Folderpath = filedialog.askdirectory()
45 # 选择文件
46 #Filepath = filedialog.askopenfilename()
47 # 打印文件夹路径
48 #print('Folderpath:', Folderpath)
49 # 打印文件路径
50 #print('Filepath:', Filepath)
51
52 #创建一个按钮:开始处理数据
53 self.bt2 = Button(root, text="开始数据处理", font=("Arial", 12), width=20, height=2, command=self.chuliExcel)
54 self.bt2.place(x=180, y=120)
55 #创建一个提示信息:显示处理后的文档位置
56 self.lab3 = Label(root, text="", font=("Arial", 12))
57 self.lab3.place(x=30, y=180)
58 return None
59
60 def songhua(self):
61 messagebox.showinfo("信息选择", "你想要处理的数据是:"+self.var.get())
62
63 def pathCallBack(self):
64 filePath = filedialog.askopenfilename(title="Select excel file", filetypes=(("excel files", "*.xlsx"),))
65 if (filePath != ''):
66 self.strPath.set(filePath)
67 print('Filepath:', filePath)
68
69 def chuliExcel(self):
70 if self.ent.get():
71 print(self.ent.get())
72 print(self.var.get())
73 print("开始处理EXCEL文件")
74 self.openxls1(self.ent.get(), self.var.get())
75 self.lab3.config(text="excel文件处理OK!!!",fg="green")
76 else:
77 messagebox.showerror("错误信息", "请选择文件!!!")
78
79 '''开始处理数据'''
80 def openxls1(self, readFilePath,selectVar):
81 #1.对源数据处理,只想要对应的列数据
82 ''''''
83 '''
84 步骤:
85 1.获取所有的sheet名称
86 2.获取每个sheet的行标题
87 3.对每个sheet的行标题进行塞选出想要的行标题
88 4.对每个sheet筛选出符合的列数据
89 5.对数据删除空行,删除第一列为空的整行
90 6.写入新的excel中
91 7.缺点:数据有重复
92 '''
93 sheetNameList = self.getSheetNames(readFilePath)
94 toFilePath = '../reports/to01.xlsx'
95 self.excel01(readFilePath, toFilePath, sheetNameList)
96
97 #2.对上面有重复的数据处理:删除重复数据
98 '''
99 步骤:
100 1.获取获取所有的sheet名称
101 2.获取每个sheet对应的数据
102 3.对数据去除重复的
103 4.将数据重新写入新的excel中
104 5.缺点:sheet太多
105 '''
106 readFilePath = toFilePath
107 sheetNameList = self.getSheetNames(readFilePath)
108 toFilePath = '../reports/to02.xlsx'
109 self.qcfxls(readFilePath, sheetNameList, toFilePath)
110
111 #3.对上面数据整合在一个sheet中,包含81BOM,HSG,MLB
112 '''
113 步骤:
114 1.获取每个sheet中的数据
115 2.将每个sheet中的数据追加到一个空数组中
116 3.将数组通过concat结合在一起
117 4.写入新的excel中
118 5.缺点:HSG跟MLB在一起
119 '''
120 readFilePath = toFilePath
121 sheetNameList = self.getSheetNames(readFilePath)
122 toFilePath1 = '../reports/to03_key.xlsx'
123 toFilePath2 = '../reports/to03.xlsx'
124 self.zhengheALLsheet(readFilePath, sheetNameList, toFilePath1, toFilePath2)
125
126 #4.对上面数据只想获取想要的81BOM,HSG
127 '''
128 步骤:
129 1.获取每个sheet中的数据
130 2.根据sheet只获取想要的81BOM跟HSG数据头
131 3.根据表头获取对应列的数据
132 4.对数据删除空行
133 5.对数据删除81BOM列中有nan的行
134 6.写入到新的excel中
135 7.缺点:有重复行
136 '''
137 readFilePath = toFilePath2
138 sheetNameList = self.getSheetNames(readFilePath)
139 toFilePath = '../reports/to04.xlsx'
140 myTopName = selectVar
141 self.foundtopnamedata(readFilePath, sheetNameList, toFilePath, myTopName)
142
143 #5.对上面数据去除重复
144 '''
145 步骤:
146 1.调用去除重复函数
147 2.缺点:一个81对应多个70在一行数据中
148 '''
149 readFilePath = toFilePath
150 sheetNameList = self.getSheetNames(readFilePath)
151 toFilePath = '../reports/to05.xlsx'
152 self.qcfxls(readFilePath, sheetNameList, toFilePath)
153
154 #6.对上面数据处理,使81跟70一一对应
155 '''
156 步骤:
157 1.读取excel数据
158 2.获取excel中的行数跟列数
159 3.获取81跟70配对,组合成2维数组
160 4.将二维数据写入新excel中
161 5.缺点:有重复数据,第二列有空数据
162 '''
163 readFilePath = toFilePath
164 toFilePath = '../reports/to06.xlsx'
165 sheetNameList = self.getSheetNames(readFilePath)
166 df = pd.read_excel(readFilePath, sheet_name=sheetNameList[0])
167 hanglie = df.shape
168 hang = hanglie[0]
169 lie = hanglie[1]
170 result2 = self.get8170lists(df, hang, lie)
171 self.writerexcel(sheetNameList,toFilePath, result2)
172
173 #7.对上面数据进行处理,去除重复行
174 readFilePath = toFilePath
175 sheetNameList = self.getSheetNames(readFilePath)
176 toFilePath = '../reports/to07.xlsx'
177 self.qcfxls(readFilePath, sheetNameList, toFilePath)
178
179 #8.去除第二列有nan的整行数据
180 readFilePath = toFilePath
181 toFilePath = '../reports/to08.xlsx'
182 sheetNameList = self.getSheetNames(readFilePath)
183 df = pd.read_excel(readFilePath, sheet_name=sheetNameList[0])
184 topNames = (df.keys()).values
185 self.quchunan(topNames, sheetNameList, readFilePath, toFilePath)
186
187 '''去除第二列有为空的整行数据'''
188 def quchunan(self, topNames, sheetNameList, readFilePath, toFilePath):
189 writer = pd.ExcelWriter(toFilePath)
190 df = pd.read_excel(readFilePath, sheet_name=sheetNameList[0])
191 d = self.returnDict(topNames, df)
192 todf = pd.DataFrame(d)
193 todf = todf.dropna(subset=topNames[1])
194 todf.to_excel(writer, sheet_name=sheetNameList[0], index=False)
195 writer.save()
196 writer.close()
197 print("创建excel OK,去除了第二列为空的数据!!!")
198
199 '''将二维数据写入excel中'''
200 def writerexcel(self, sheetNameList, toFilePath, result2):
201 writer = pd.ExcelWriter(toFilePath)
202 df = pd.DataFrame(result2)
203 df.to_excel(writer, sheet_name=sheetNameList[0], index=False)
204 writer.save()
205 writer.close()
206
207 '''获取81跟70配对,组合成2维数组'''
208 def get8170lists(self, df, hang, lie):
209 n = 0
210 m = 1
211 h_list = []
212 h_lists = []
213 while n < hang:
214 while m < lie:
215 valueij = df.values[n, 0]
216 h_list.append(valueij)
217
218 valueij = df.values[n, m]
219 h_list.append(valueij)
220
221 h_lists.append(h_list)
222 h_list = []
223 m += 1
224 n += 1
225 m = 1
226 return h_lists
227
228 '''根据sheet名称获取对应列名的数据,写入新的excel中'''
229 def foundtopnamedata(self, readFilePath, sheetNameList, toFilePath, myTopName):
230 sheetName = sheetNameList[0]
231 print(sheetName)
232 df = pd.read_excel(readFilePath, sheet_name=sheetName)
233 topNames = (df.keys()).values
234 if myTopName=="BC1":
235 print("获取HSG与81的配对")
236 findArr = self.returnFiindHSG(topNames)
237 elif myTopName=="MBM":
238 print("获取MLB与81的配对")
239 findArr = self.returnFiindMLB(topNames)
240 else:
241 findArr = []
242
243 if findArr:
244 print("获取对应列的所有数据")
245 d = self.returnDict(findArr, df)
246 todf = pd.DataFrame(d)
247 self.dfWriteexcel(todf, toFilePath, findArr, myTopName)
248 else:
249 print("没有找到想要的列表头")
250
251 '''数据写入excel'''
252 def dfWriteexcel(self, todf, toFilePath, findArr, sheetName):
253 writer = pd.ExcelWriter(toFilePath)
254 print("删除空行")
255 todf = todf.dropna(how='all')
256 print("删除81BOM列中有nan的行")
257 todf = todf.dropna(subset=findArr[0])
258 todf.to_excel(writer, sheet_name=sheetName, index=False)
259 writer.save()
260 writer.close()
261 print("创建excel OK,一个sheet,只有想要的81BOM,HSG列或81BOM,MLB列!!!")
262
263 '''整合所有sheet放在第一个sheet中'''
264 def zhengheALLsheet(self, readFilePath, sheetNameList, toFilePath1, toFilePath2):
265 writer1 = pd.ExcelWriter(toFilePath1)
266 writer2 = pd.ExcelWriter(toFilePath2)
267
268 k = 0
269 frames = []
270 while k < len(sheetNameList):
271 sheetName = sheetNameList[k]
272 print(sheetName)
273 df = pd.read_excel(readFilePath, sheet_name=sheetName)
274 # print(df1)
275 frames.append(df)
276 k += 1
277 print(frames)
278
279 result1 = pd.concat(frames, keys=sheetNameList)
280 result1.to_excel(writer1, sheet_name="allhsgmlb")
281 writer1.save()
282 writer1.close()
283
284 result2 = pd.concat(frames)
285 result2.to_excel(writer2, sheet_name="allhsgmlb", index=False)
286 writer2.save()
287 writer2.close()
288 print("数据整合到一个sheet中成功!")
289
290 '''去除重复的数据'''
291 def qcfxls(self, readFilePath, sheetNameList, toFilePath):
292 writer = pd.ExcelWriter(toFilePath)
293 # 读取excel中的数据
294 j = 0
295 while j < len(sheetNameList):
296 sheetName = sheetNameList[j]
297 data = pd.DataFrame(pd.read_excel(readFilePath, sheetName))
298 # 查看去除重复行的数据
299 no_re_row = data.drop_duplicates()
300 print(no_re_row)
301 # 将去除重复行的数据输出到excel表中
302 no_re_row.to_excel(writer, sheet_name=sheetName, index=False)
303 j += 1
304 writer.save()
305 writer.close()
306 print("去除重复数据OK")
307
308 '''第一次处理excel,获取想要的81BOM,HSG,MLB,数据有重复,去除了空行跟第一列为空的整行数据'''
309 def excel01(self, readFilePath, toFilePath, sheetNameList):
310 k = 0
311 writer = pd.ExcelWriter(toFilePath)
312 while k < len(sheetNameList):
313 sheetName = sheetNameList[k]
314 print(sheetName)
315 df = pd.read_excel(readFilePath, sheet_name=sheetName)
316 print("获取表头")
317 topNames = (df.keys()).values
318 print(topNames)
319 print("查找是否有81BOM,HSG,MLB列")
320 findArr = self.returnFiindAll(topNames)
321 print("整合后的表头数据")
322 print(findArr)
323
324 if findArr:
325 print("获取对应列的所有数据")
326 d = self.returnDict(findArr, df)
327 todf = pd.DataFrame(d)
328 print("删除空行")
329 todf = todf.dropna(how='all')
330 print("删除该列中有nan的行")
331 todf = todf.dropna(subset=findArr[0])
332 todf.to_excel(writer, sheet_name=sheetName, index=False)
333 else:
334 print("没有找到想要的列表头")
335 k += 1
336 writer.save()
337 writer.close()
338 print("创建excel OK,该excel只留下81BOM,HSG,MLB数据,有重复!!!")
339 return None
340
341 '''去取字符串左右空格'''
342 def qukongge(self, lieDatas):
343 allData_strip = []
344 for allData in lieDatas:
345 if isinstance(allData, str):
346 # print(allData.strip())
347 allData_strip.append(allData.strip())
348 else:
349 # print(allData)
350 allData_strip.append(allData)
351 return allData_strip
352
353 '''返回插入EXCEL数据的字典形式'''
354 def returnDict(self, findArr, df):
355 i = 0
356 d = {}
357 while i < len(findArr):
358 allData1 = df.loc[:, findArr[i]].values
359 allData1a = self.qukongge(allData1)
360 d[findArr[i]] = allData1a
361 i += 1
362 return d
363
364 '''返回符合要求的MLB表头'''
365 def returnFiindMLB(self, topNames):
366 MLB = '70 MLB Bin'
367 findArr = []
368 for topName in topNames:
369 if topName == '81BOM':
370 findArr.append(topName)
371 print(findArr)
372 if MLB in topName:
373 findArr.append(topName)
374 print(findArr)
375 return findArr
376
377 '''返回符合要求的HSG表头'''
378 def returnFiindHSG(self, topNames):
379 HSG = '70 HSG Bin'
380 findArr = []
381 for topName in topNames:
382 if topName == '81BOM':
383 findArr.append(topName)
384 print(findArr)
385 if HSG in topName:
386 findArr.append(topName)
387 print(findArr)
388 return findArr
389
390 '''返回符合要求的81BOM,HSG,MLB表头'''
391 def returnFiindAll(self, topNames):
392 findArr = []
393 for topName in topNames:
394 if topName == '81BOM':
395 findArr.append(topName)
396 print(findArr)
397 if '70 HSG Bin' in topName:
398 findArr.append(topName)
399 print(findArr)
400 if '70 MLB Bin' in topName:
401 findArr.append(topName)
402 print(findArr)
403 return findArr
404
405 '''获取excel中所有的sheet名称'''
406 def getSheetNames(self, readFilePath, sheetName=None):
407 df = pd.read_excel(readFilePath, sheet_name=sheetName)
408 sheetNameList = list(df)
409 return sheetNameList
410
411 if __name__ == '__main__':
412 root = Tk()
413 root.geometry("500x300+200+300")
414 root.title("81 mapping 70 数据处理小程序")
415 app = OpenMyXLS(master=root)
416 root.mainloop()