
基本爬虫架构:实现豆瓣爬虫
一、架构原理及运行流程
1.1 架构图解

1.2 模块分析
- 爬虫调度器:爬虫调度器只要负责统筹其他四个模块的协调工作。
- URL 管理器:负责管理 URL 链接,维护已经爬取的 URL 集合和未爬取的 URL 集合,提供获取新 URL 链接接口。
- HTML 下载器:用于从 URL 管理器中获取未爬取的 URL 链接并下载 HTML 网页。
- HTML 解析器:用于从 HTML 下载器中获取已经下载的 HTML 网页,并从中解析出新的 URL 交给 URL 管理器,解析出有效数据交给数据存储器。
- 数据存储器:用于将 HTML 解析器解析出来的数据通过文件或者数据库形式存储起来。
1.3 运行流程

二、URL 管理器
2.1 实现原理
URL 管理器主要包括两个变量,一个是已爬取 URL 的集合,另一个是未爬取 URL 的集合。采用 Python 中的 set 类型,主要是使用 set 的去重复功能, 防止链接重复爬取,因为爬取链接重复时容易造成死循环。链接去重复在 Python 爬虫开发中是必备的功能,解决方案主要有三种:1)内存去重 2)关系数据库去重 3)缓存数据库去重。大型成熟的爬虫基本上采用缓存数据库去重的方案,尽可能避免内存大小的限制,又比关系型数据库去重性能高很多。由于基础爬虫的爬取数量较小,因此我们使用 Python 中 set 这个内存去重方式。
URL 管理器除了具有两个 URL 集合,还需要提供以下接口,由于配合其他模块使用,接口如下:
- 判断是否有待取的 URL, 方法定义为 has_new_url()。
- 添加新的 URL 到未爬取集合中, 方法定义为 add_new_url(url),add_new_urls(urls)。
- 获取一个未爬取的 URL,方法定义为 get_new_url()。
- 获取未爬取 URL 集合的大小,方法定义为 new_url_size()。
- 获取已经爬取的 URL 集合的大小,方法定义为 old_url_size()。
2.2 代码如下
1 class UrlManager:
2 def __init__(self):
3 self.new_urls = set() # 未爬取 url 集合
4 self.old_urls = set() # 已爬取 url 集合
5
6 def has_new_url(self):
7 """
8 判断是否有未爬取的 url
9 :return: bool
10 """
11 return self.new_urls_size() != 0
12
13 def get_new_url(self):
14 """
15 返回一个未爬取的 url
16 :return: str
17 """
18 new_url = self.new_urls.pop()
19 self.old_urls.add(new_url)
20 return new_url
21
22 def add_new_url(self, url):
23 """
24 添加一个新的 url
25 :param url: 单个 url
26 :return: None
27 """
28 if url is None:
29 return None
30 if (url not in self.new_urls) and (url not in self.old_urls):
31 self.new_urls.add(url)
32
33 def add_new_urls(self, urls):
34 """
35 添加多个新的url
36 :param urls: 多个 url
37 :return: None
38 """
39 if urls is None:
40 return None
41 for url in urls:
42 self.add_new_url(url)
43
44 def new_urls_size(self):
45 """
46 返回未爬过的 url 集合的大小
47 :return: int
48 """
49 return len(self.new_urls)
50
51 def old_urls_size(self):
52 """
53 返回已爬过的 url 集合的大小
54 :return: int
55 """
56 return len(self.old_urls)
三、HTML 下载器
3.1 实现原理
HTML 下载器用来下载网页,这时候需要注意网页的编码,以保证下载的网页没有乱码。下载器需要用到 Requests 模块,里面只需要实现一个接口即可:download(url)。
3.2 代码如下
1 import requests
2
3
4 class HtmlDownloader:
5 def download(self, url):
6 """
7 下载 html 页面源码
8 :param url: url
9 :return: str / None
10 """
11 if not url:
12 return None
13
14 headers = {
15 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:63.0) Gecko/20100101 Firefox/63.0',
16 }
17 r = requests.get(url, headers=headers)
18 if r.status_code == 200:
19 r.encoding = 'utf-8'
20 return r.text
21 else:
22 return None
四、HTML 解析器
4.1 实现原理
HTML 解析器使用 Xpath 规则进行 HTML 解析,需要解析的部分主要有书名、评分和评分人数。


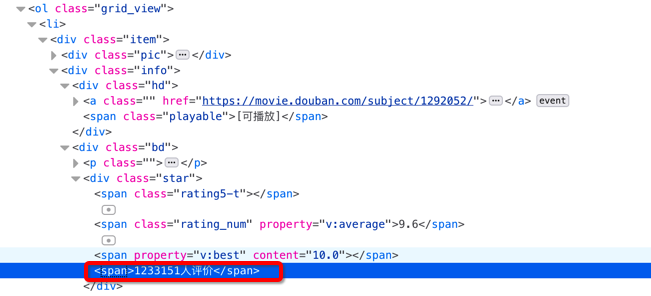
4.2 代码如下
1 from lxml.html import etree
2 import re
3
4 class HtmlParser:
5 def parser(self, page_url, html_text):
6 """
7 解析页面新的 url 链接和数据
8 :param page_url: url
9 :param html_text: 页面内容
10 :return: tuple / None
11 """
12 if not page_url and not html_text:
13 return None
14 new_urls = self._get_new_urls(page_url, html_text)
15 new_data = self._get_new_data(html_text)
16
17 return new_urls, new_data
18
19 def _get_new_urls(self, page_url, html_text):
20 """
21 返回解析后的 url 集合
22 :param page_url: url
23 :param html_text: 页面内容
24 :return: set
25 """
26 new_urls = set()
27 links = re.compile(r'\?start=\d+').findall(html_text)
28 for link in links:
29 new_urls.add(page_url.split('?')[0] + link)
30 return new_urls
31
32 def _get_new_data(self, html_text):
33 """
34 返回解析后的数据列表
35 :param html_text: 页面内容
36 :return: list
37 """
38 datas = []
39 for html in etree.HTML(html_text).xpath('//ol[@class="grid_view"]/li'):
40 name = html.xpath('./div/div[@class="info"]/div[@class="hd"]/a/span[1]/text()')[0]
41 score = html.xpath('./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[2]/text()')[0]
42 person_num = html.xpath('./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[4]/text()')[0].strip('人评价')
43 datas.append([name, score, person_num])
44 return datas
五、数据存储器
5.1 实现原理
数据存储器主要包括两个方法:store_data(data)用于将解析出来的数据存储到内存中,output_csv()用于将存储的数据输出为指定的文件格式,我们使用的是将数据输出为 csv 格式。
5.2 代码如下
1 import csv
2
3 class DataOutput:
4 def __init__(self):
5 self.file = open('数据.csv', 'w')
6 self.csv_file = csv.writer(self.file)
7 self.csv_file.writerow(['书名', '评分', '评分人数'])
8
9 def output_csv(self, data):
10 """
11 将数据写入 csv 文件
12 :param data: 数据
13 :return: None
14 """
15 self.csv_file.writerow(data)
16
17 def close_file(self):
18 """
19 关闭文件链接
20 :return: None
21 """
22 self.file.close()
六、爬虫调度器
6.1 实现原理
爬虫调度器首先要做的是初始化各个模块,然后通过 crawl(start_url) 方法传入入口 URL,方法内部实现按照运行流程控制各个模块的工作。
6.2 代码如下
1 from UrlManager import UrlManager
2 from HtmlDownloader import HtmlDownloader
3 from HtmlParser import HtmlParser
4 from DataOutput import DataOutput
5
6
7 class SpiderManager:
8 def __init__(self):
9 self.manager = UrlManager()
10 self.downloader = HtmlDownloader()
11 self.parser = HtmlParser()
12 self.output = DataOutput()
13
14 def crawl(self, start_url):
15 """
16 负责调度其他爬虫模块
17 :param start_url: 起始 url
18 :return: None
19 """
20 self.manager.add_new_url(start_url)
21 while self.manager.has_new_url():
22 try:
23 new_url = self.manager.get_new_url()
24 html = self.downloader.download(new_url)
25 new_urls, new_datas = self.parser.parser(start_url, html)
26 self.manager.add_new_urls(new_urls)
27 for data in new_datas:
28 self.output.output_csv(data)
29 except Exception:
30 print('爬取失败')
31 self.output.close_file()
32
33
34 if __name__ == '__main__':
35 sm = SpiderManager()
36 sm.crawl('https://movie.douban.com/top250?start=0')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号