

结对编程
| git地址 | https://github.com/ITBuilting/mytestgit |
|---|---|
| 结对成员 | 谭镕 |
| 结对成员学号 | 201831061204 |
| Fork仓库的Github项目地址 | https://github.com/ITBuilting/mytestgit |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 2400 | 2000 |
| Development | 开发 | 800 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 150 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 50 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 120 | 100 |
| · Coding | · 具体编码 | 540 | 300 |
| · Code Review | · 代码复审 | 120 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 200 |
| Reporting | 报告 | 30 | 40 |
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 40 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计 | 30 | 60 |
| 合计 | 2320 | 1850 |
需求分析:
实现一个命令行程序,输入文件名以命令行参数传入。
则会统计input.txt中的以下几个指标
1.统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
2.统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母:A-Z,a-z
- 字母数字符号:A-Z,a-z,0-9
- 分割符:空格,非字母数字符号
3.统计文件的有效行数:任何包含非空白字符的行,都需要统计。
4.统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
5.按照字典序输出到文件txt:
- 输出的单词统一为小写格式
输出的格式为
characters: number
words: number
lines: number
: number
: number
...
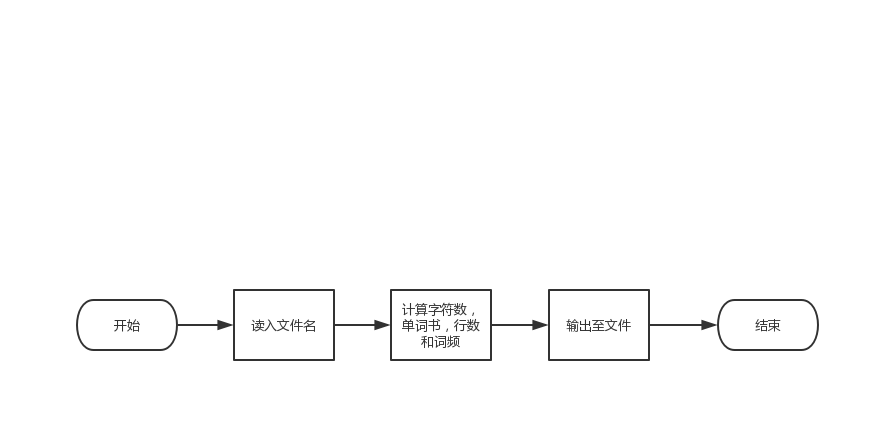
计算接口与设计实现
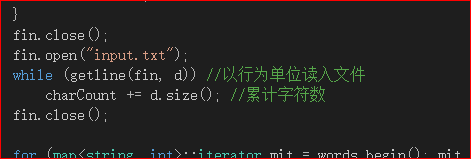
1.在思考打开文件的读取的时候,我们使用了库函数ftream和map。 ifstream来读入需要的文件,ofstream来实现结果输出进文件output.txt中,用fout和fin来实现向文件中进行写操作和从文件的内容中进行读操作。
2.使用bool isdigit函数来判断是否是个十进制数字。
3.使用map的迭代器来遍历访问这个文件里面的元素 ,我们学习并且使用了许多新函数。
具体代码:
#include "pch.h"
#include <fstream>
#include <map>
#include <string>
using namespace std;
bool isdigit(char ch)
{
return (ch >= ' '&&ch <= '9');
}
int main(void)
{
map<string, int> words; //转int类型
ifstream fin("input.txt");//要统计的文件
ofstream fout("output.txt");//结果存放在output中
//------------
string str;
int wordCount = 0;
string d;
int charCount = 0;
//------------
if (!fin || !fout)
{
exit(1);
}
while (fin.good())
{
fin >> str;
words[str]++;
}
fin.close();
fin.open("input.txt");
while (getline(fin, d)) //以行为单位读入文件
charCount += d.size(); //累计字符数
fin.close();
for (map<string, int>::iterator mit = words.begin(); mit != words.end(); ++mit)
{
if (!isdigit((mit->first)[0]))
{
fout << "<" << mit->first << ">" << ": " << mit->second << endl;
++wordCount;
}
}
fout << "wordTotal: " << wordCount << endl; // 文件输出单词个数
fout << "charTotal: " << charCount << endl; //文件输出字符个数
fout.close();
return 0;
}
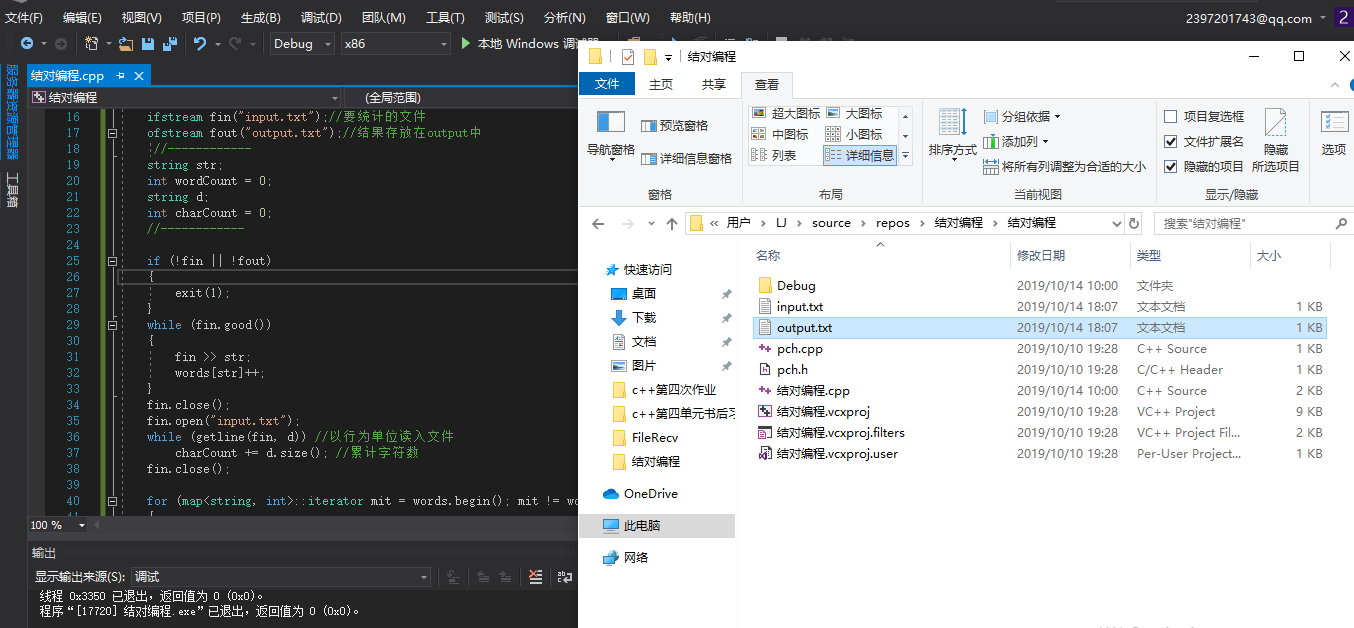
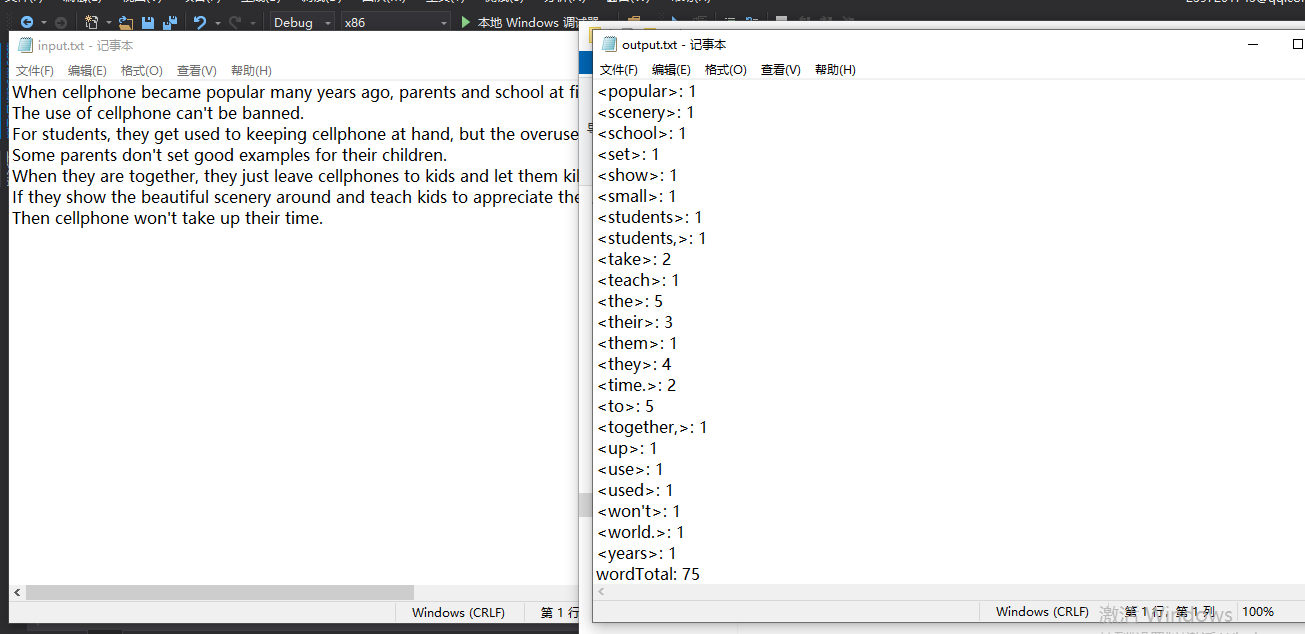
运行截图:
代码复审和改进过程:
每写一部分代码就会相应的进行一定的审查,在过程中有很多不明白的地方,就会一起查阅知识,很多知识也是我的结对伙伴教给我的。最后通过讨论我们对读入字符代码实现部分进行了改进:统一使用系统库的有关文件的函数,对代码量达到了控制,简便明了。
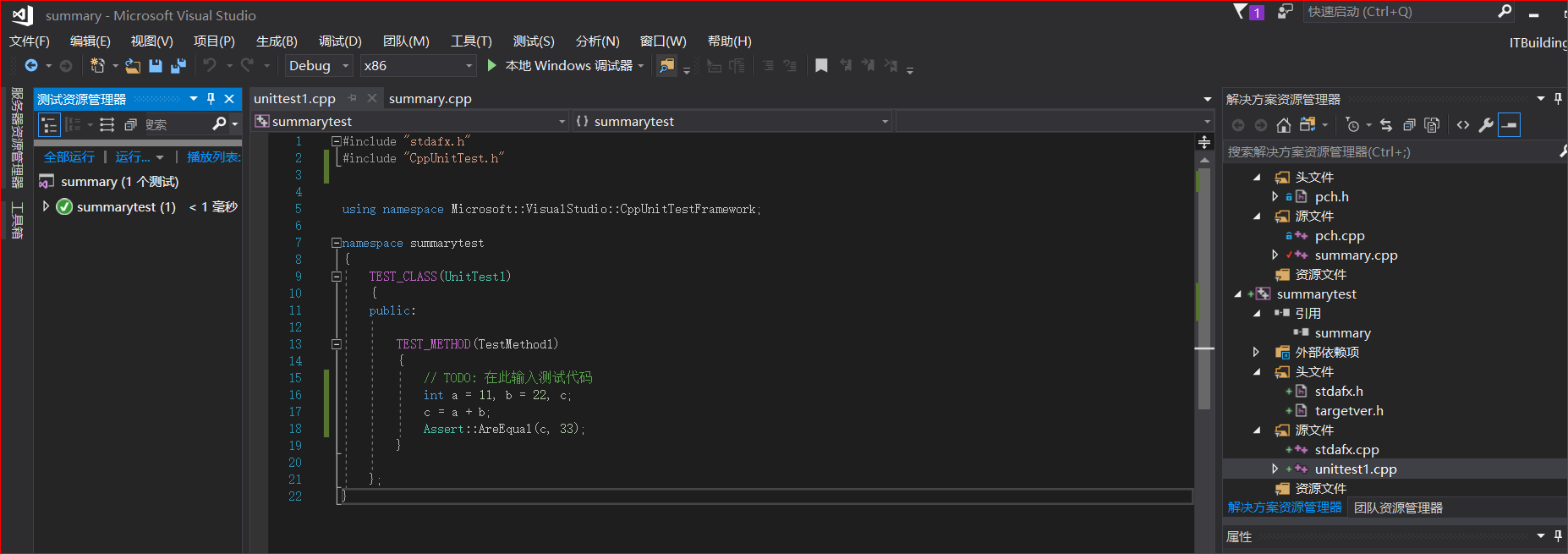
计算模块部分单元测试展示
计算模块部分异常处理说明
我们一直在遇到问题,也相应的一直在网上查找,我们由于第二次作业完成情况不是很良好,所以在git提交上浪费了很多时间。

描述结对的过程

心路历程与收获
整个作业对于我来说难度还是很大的,遇到了很多问题,但是幸好我的小伙伴很优秀。也很感谢我的结对小伙伴从头到尾的帮助。虽然整个作业过程还是有一点艰辛的,但是也开心从中学到了一些东西,比如文件读取等,还了解了许多函数,还有关于map的许许多多的东西,以后还是要多向大佬学习,一点一点的积累知识,嘿嘿。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号