爬虫分享
爬虫的原理
概念
爬虫一般指网络爬虫。网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者) --百度百科
爬虫本身是一种程序,或者说是自动化脚本,这个程序的作用呢,就是代替人,把网站上的内容获取回来。因为是程序做这个工作,所以效率大大提高。
HTTP/HTTPS协议
获取网站的内容则简历在http/https协议基础上。(把网站上内容获取回来,那我们手动去做的话,是打开浏览器,输网址然后回车,获取到网站的内容)
我们需要去了解这个过程中发生了些什么。https://www.zhihu.com/question/20513729/answer/96332435
概述:爬虫就是写程序获取网站/app的内容,这个过程的底层是一些协议
入门案例
这里我们使用python变成爬虫程序。python对爬虫是所有语言中支持最好的(这里说的其实是说他对这个网络协议的Api是最好用,最齐全的)。除了python写爬虫,排名第二的爬虫语言应该是Java,目前 市面上 主要也是这两种爬虫岗位的需求,其他语言的爬虫较少。
python
python三大擅长领域
- 爬虫
- 算法及大数据
- Web
开发准备
- python环境安装(加入path)
- IDE的使用、pycharm安装
- 安装依赖
pip install requests bs4 lxml
最简单入门案例
import requests
res=requests.get("https://www.baidu.com/",verify=True) #res类型requests.models.Response
res.encoding='utf-8'
print(res.text)
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
解析
上面我们看到我们拿到了
https://www.baidu.com的数据,挺轻松的,但我们想要的可能不是这一堆带着网页样式的数据。那我们就需要把这个网页的代码解析成我们需要的数据
把简单爬虫看作两部分
- 下载(最简单入门案例实现了下载的功能)
- 解析
常见的解析手段有 csspath,xpath,正则,jsonpath
csspath
根据css选择器来对元素进行选择,然后获取元素的内容或者属性。csspath是一种在网页document中搜索到某个dom元素的方法。css选择器参考 https://www.w3school.com.cn/cssref/css_selectors.asp
BeautifulSoup库的使用
BeautifulSoup是一个支持csspath的解析库
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,"html.parser")
title=soup.select_one("head>title").text #获取内容
description=soup.select_one('#su')['value']
更多BeautifulSoup 查看 https://www.cnblogs.com/mxjhaima/p/13756713.html
xpath
xpath是基于xml文档路径的一种搜索方式
路径表达式
/ 根节点,节点分隔符,
// 任意位置
. 当前节点
.. 父级节点
@ 属性
通配符
* 任意元素
@* 任意属性
node() 任意子节点(元素,属性,内容)
谓语
谓语是 中括号中的限定符
//a[n] n为大于零的整数,代表子元素排在第n个位置的<a>元素
//a[last()] last() 代表子元素排在最后个位置的<a>元素
//a[last()-] 和上面同理,代表倒数第二个
//a[position()<3] 位置序号小于3,也就是前两个,这里我们可以看出xpath中的序列是从1开始
//a[@href] 拥有href的<a>元素
//a[@href='www.baidu.com'] href属性值为'www.baidu.com'的<a>元素
//book[@price>2] price值大于2的<book>元素
函数
contains(string1,string2)
【在xpath插件中演示xpath规则】
【谷歌浏览器中copy xpath】
python中使用xpath
from lxml import etree
html = etree.HTML(res.text)
print(html.xpath("//a/text()")) #获取内容
print(html.xpath("//a/@href")) #获取内容
#html = etree.XML(res.text) XML解析html可能会报错
更多xpath讲解 https://www.cnblogs.com/mxjhaima/p/13775844.html
jsonpath
有时候我们获取到的内容是json。jsonpath是用于解析json的一种规则,主要是java爬虫中使用,python中的json路径访问是非常容易的,所以一般也不需要使用jsonpath来解析数据。有兴趣的可以看一下 https://github.com/json-path/JsonPath
https://goessner.net/articles/JsonPath
正则表达式
很多时候,我们获取到的数据并不是像这个网页那样规则,有的内容可能是普通的文本(没有标签),这时候无法再使用csspath和xpath
- 元字符
- 普通字符
- 字符类
- 预定义字符类
- 数量词
- 边界标识符
- 正则组
- 贪婪匹配和非贪婪匹配
- 先行断言、后行断言 https://blog.csdn.net/u012047933/article/details/38365541
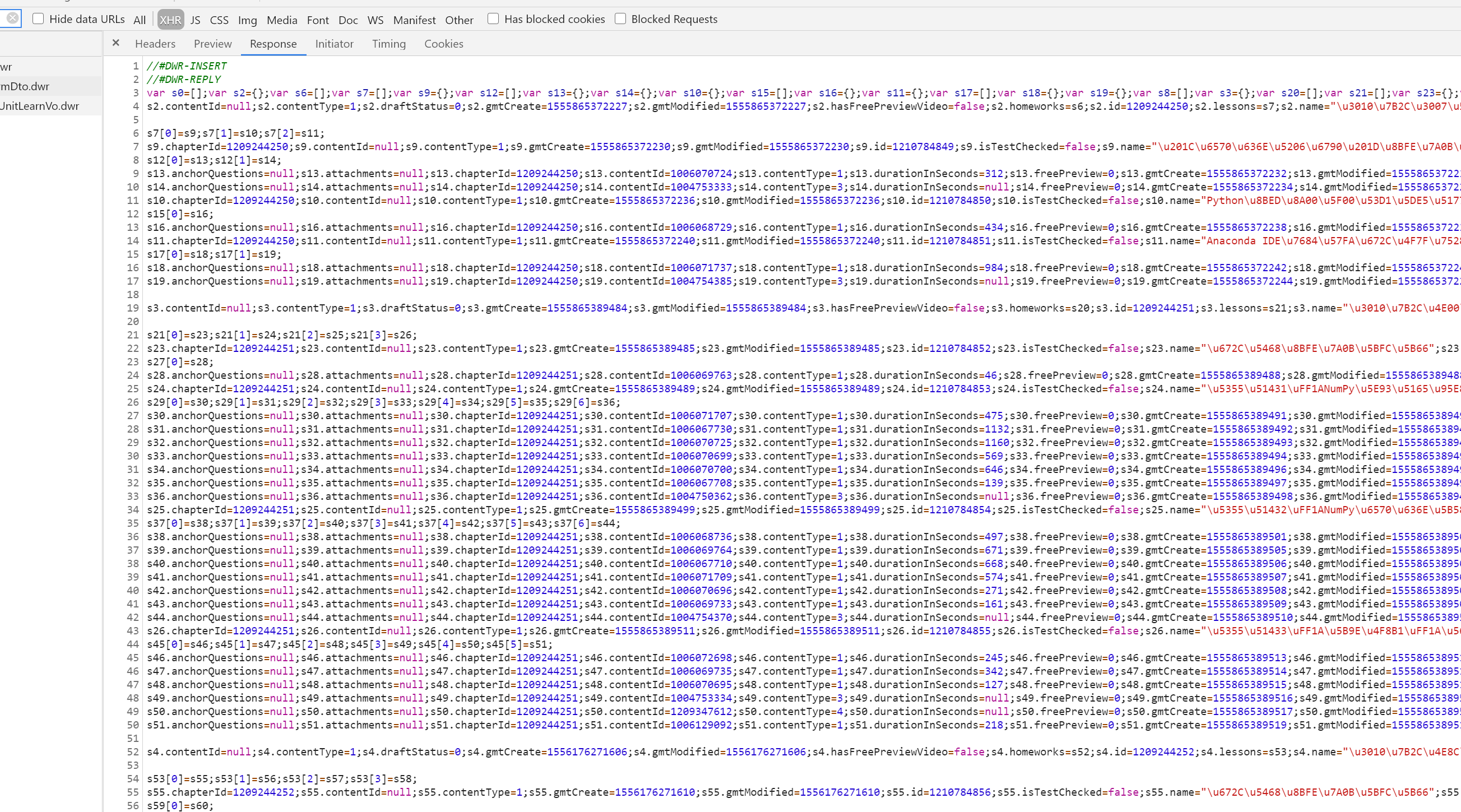
lids=re.findall("s\d*?\.attachments=.*?;s\d*?\.chapterId=(.*?);.*?\.contentType=(\d*?);.*?\.id=(\d*?);.*?lessonId=(\d*?);.*?name=\"(.*?)\";",page_content,re.M| re.S)
cpts=re.findall("\.id=(\d*?);s\d*?\.lessons=s\d*?;s\d*?\.name=\"(.*?)\";",page_content,re.M| re.S)
sections=re.findall("s\d.*?chapterId=\d*?;s\d*?\.contentId.*?;s\d*?\.id=(\d*?);s\d*?\.isTestChecked=false;s\d*?\.name=\"(.*?)\";",page_content,re.M| re.S)
数据存储
当我们把数据解析到之后,格式化的数据还在内存中,再使用存储相关的模块把数据存储到指定的数据库中
至此我们的爬虫教程就结束了、恭喜你
想一想为什么这个程序叫爬虫,为什么它不叫臭虫呢?
刚刚我们只抓取了一个网页的内容,如果我们要像百度一样,采集所有的网站的内容,那应该怎么做呢?
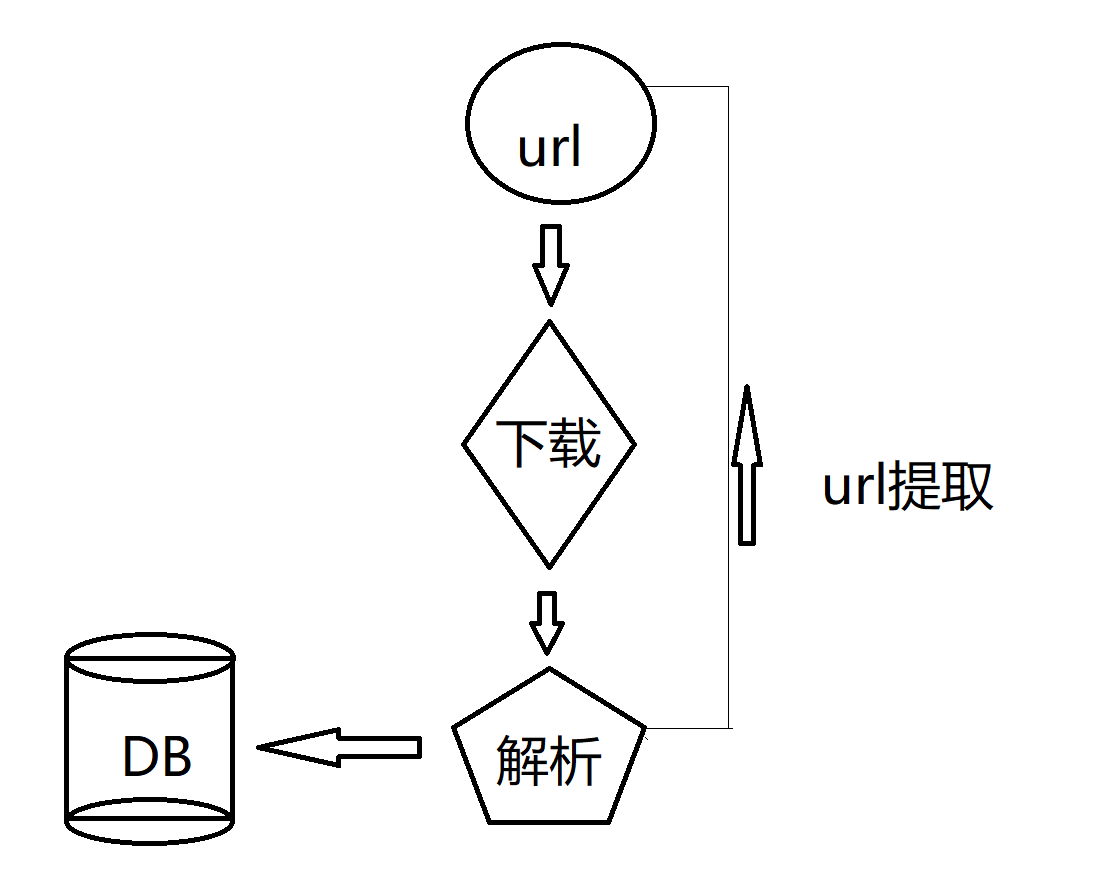
通常我们会把爬取到的url,再次放入url集合里面,然后就能从这个网址爬到下一个网址上去了,爬虫大概形象的形容了这样一个过程
反爬
robots协议
对于网站来说,很多时候并不喜欢爬虫来抓取自己网站上的内容。有的时候我们的网站是希望被搜索引擎爬到的(可以被用户收到,有专门做seo的岗位),而另外有的内容,我们拒绝让搜索引擎爬到。robots协议是规定允许哪些网址被爬,哪些不被爬的
https://www.taobao.com/robots.txt
https://www.jd.com/robots.txt
http介绍
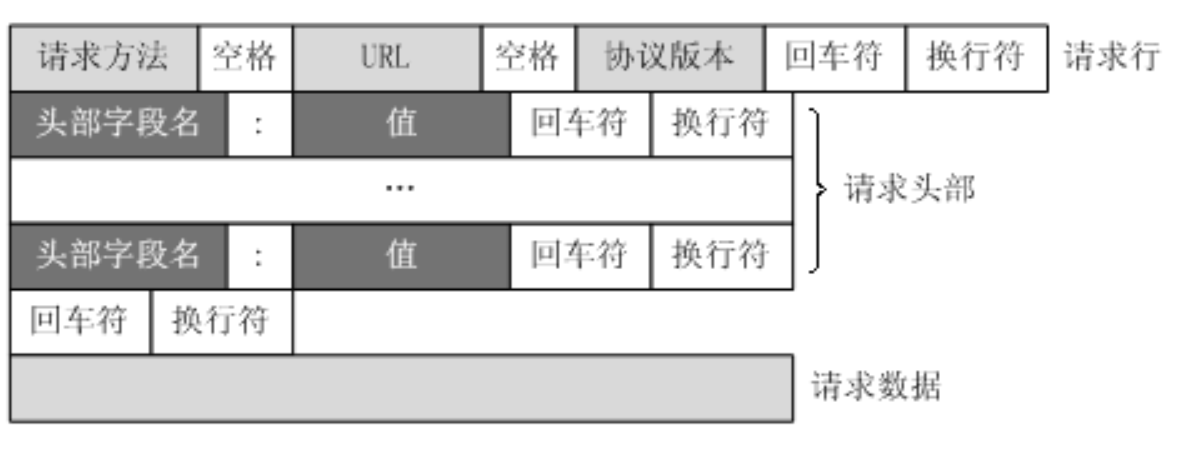
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
请求行、请求头部、空行、请求数据
四个部分组成,下图给出了请求报文的一般格式。
headers = {
"Host": "www.chinesemooc.org",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Origin": "http://www.chinesemooc.org",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Referer": "http://www.chinesemooc.org/kvideo.php?do=search",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9"
}
抓包工具
- chrome调试工具
- fidder、charles
js加密参数
有的请求,我们使用抓包工具,可以发现它的请求是由特殊参数的是通过前端的某一些加密算法生成的,1、前端启调方法很隐蔽,2、加密具体使用的方法复杂,导致参数无法在短时间破解
模拟浏览器
更多的时候破解反爬需要耗费大量的时间,再不太追求性能的条件下,我们可以试用模拟浏览器。Selenium webdriver
【展示模拟浏览器】
代理ip
爬虫访问网站的时候,都会暴露自己的ip,单个ip访问频繁,就会反爬禁用
app抓取
-
代理工具抓取接口连接,访问接口,就能获取到app的数据
-
接口参数被包装并加密,此时需要逆向app
app逆向是目前比较复杂的技术。主要的思路是,通过对app的代码反编译,获取到加密参数的方法,再自己实现方法来生成加密参数,从而重新组装http请求。除了重构加密方法之外,也可以用hook。
加固与破壳,有的时候反编译后发现app的代码是其他公司的包名,比如com.tencent.,这个app不是腾讯的,为啥却是腾讯的包名呢?因为该app使用了腾讯的加固技术,通常各大应用市场都会提供加固技术。使用加固技术后,代码被反编译出来,并不能找到真正的逻辑代码,和app入口。破壳技术是爬虫对加固技术的解决办法,具体到不同的加固技术,使用不同的破壳方案,这里需要能阅读一些c语言,类汇编的代码。
模拟手机操作app去采集数据,目前应用最广的是appium,uiautomator2,(本来这两个技术都是做app自动化测试用的)

群控解决方案

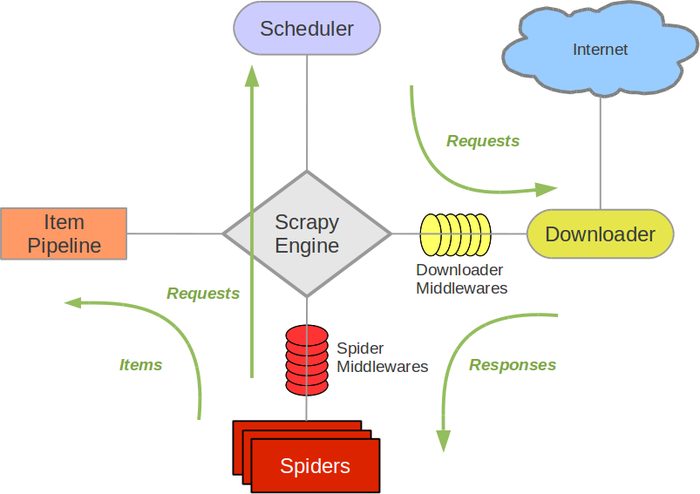
爬虫框架Scrapy
多线程,异步请求
Scrapy使用了Twisted(其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
分布式爬虫
种子url,单纯的多进程不能解决爬取效率,只能导致重复采集。那通常这时候我们可以使用redis队列做url统一存储。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号