正则表达式(代码java版)
重新发布于2020年09月27日,写于2016年
看了好些天的正则表达式,终于有时间来写一篇关于它的博客了。也是因为前段时间做标签处理的工作用到,用正则匹配标签规则,少写了不少代码。在有的地方使用正则表达式确实特别棒。参考博文http://blog.csdn.net/yaerfeng/article/details/28855587 ,文中提到程序员的七种基本技能,确实各种语言,系统里几乎都有对正则的支持,虽说不用精通,但也要基本运用没问题。
元字符
元字符标识在正则表达式中有特殊含义的字符,正是由它们,正则表达式才真正存在。JAVA中支持的元字符列表有:([{\^-$|}])?*+.
():正则组中使用[]:字符类中表示一个字符{}:数量范围标识\:预定义字符类中使用^$:边界标识-:字符类中表示某个范围时使用,和"[]"配合使用|:逻辑或?*+:预定义数量词^:逻辑非.:点号匹配除换行符的任意字符 (这个地方任然有点疑问)
这里要特别说明一个符号&,虽然&&在字符类中扮演着逻辑与运算,但却不在元字符行列中
检测工具
为了学习简单,写了一段测试代码做检测用,当然你也可以使用网上的检测工具,由于目前各个语言正则的引擎各有取舍,所以在线工具的检测结果不一定和代码检测结果相同(基本上没太大出入),但用于理解正则,还是很有用的。
简单案例:匹配5个连续的数字
正则表达式为[0-9]{5},先用开源中国的在线测试工具测试一下。待匹配的字符串为“自由12345飞翔”
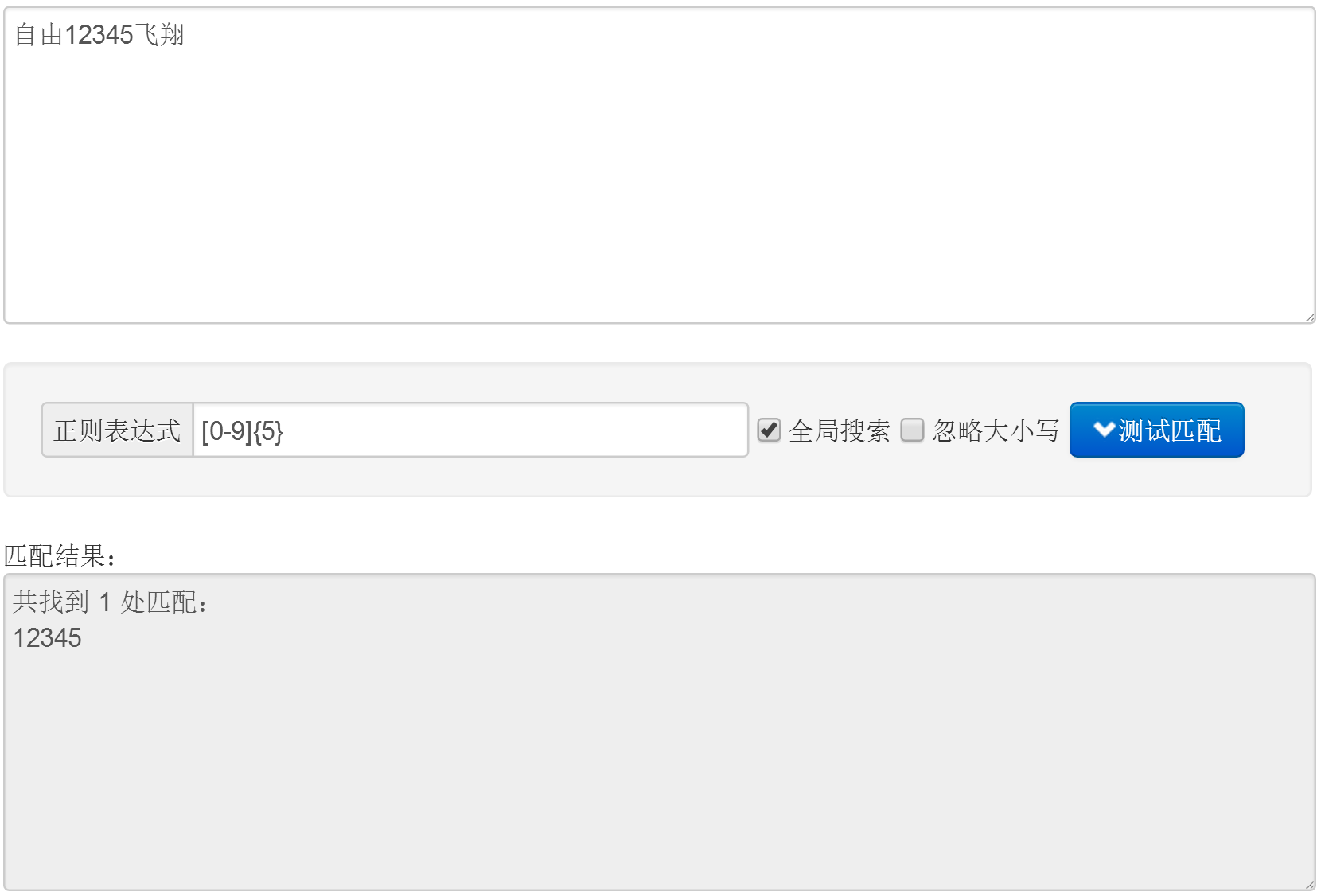
JAVA检测代码如下
/**
* 检测简单方法
* @param target //待查找匹配的字符串
* @param regex //匹配规则的正则表达式
*/
public static void simpletest(String target,String regex) {
Pattern p = Pattern.compile(regex);//java.util.regex.Pattern;
Matcher matcher = p.matcher(target);//java.util.regex.Pattern;
while (matcher.find()) {
System.out.println(matcher.group(0));
}
}
simpletest("自由12345飞翔", "[0-9]{5}");
//执行结果如下
12345
普通字符
所谓普通字符即为非元字符,上文中提到的元字符列表,即不是上面列表中的字符,就视为普通字符,普通字符为原样匹配
案例1,普通字符
simpletest("自123由飞12333翔", "123");
//执行结果如下
123
123
如上案例中,会去目标字符串"自123由飞12333翔"中查找123,由于123为普通字符,没有特殊含义,此时原样匹配,所以匹配到"自123由飞12333翔"中两组123
案例2,元字符
simpletest("自[]由飞翔", "[");
//执行结果如下
直接报错 Exception in thread "main" java.util.regex.PatternSyntaxException: Unclosed character class
如果要让元字符原样匹配,则需要用\转义元字符,JAVA中\\才表示普通字符串的\,所以为\\[
simpletest("自[]由飞翔", "\\[");
//执行结果如下
[
如上,通过转义,匹配到 “自[]由飞翔”中的元字符 [
而在线工具可以直接将字符读入,所以不用\\,\[就表示匹配字符[,如下

案例3,普通字符&
simpletest("自&&由飞翔", "&&");
//执行结果如下
&&
simpletest("自&由&飞翔", "&");
//执行结果如下
&
&
案例3可以看出,虽然&&有特殊含义,但单独用时,不用转义,和普通字符完全相同
字符类
字符类(character class),这里这个词语是个专用名词,在JAVA API 中的Pattern类中我们可以看到字符类的一个列表。一个[]中的规则叫一个字符类,一个字符类仅匹配一个字符(一个位置)
- [abc] a、b 或 c(简单类)
- [^abc] 任何字符,除了 a、b 或 c(否定)
- [a-zA-Z] a 到 z 或 A 到 Z,两头的字母包括在内(范围) 数字范围也能类似表示如[0-9]代表0到9中任意一个数字
- [a-d[m-p]] a 到 d 或 m 到 p:[a-dm-p](并集) **等同于[a-d|[m-p]] 等同与 [[a-d]|[m-p]] **
- [a-z&&[def]] d、e 或 f(交集)
- [a-z&&[^bc]] a 到 z,除了 b 和 c:[ad-z](减去) 差集
- [a-z&&[^m-p]] a 到 z,而非 m 到 p:[a-lq-z](减去)差集
案例
simpletest("abcd", "[abc]");
//执行结果如下
a
b
c
simpletest("abcd", "[^abc]");
//执行结果如下
d
simpletest("abcd", "[a-zA-Z]");
//执行结果如下
a
b
c
simpletest("an", "[a-d[m-p]]");
//执行结果如下
a
n
simpletest("abcd", "[a-z&&[def]]");
//执行结果如下
d
simpletest("abcd", "[a-z&&[^bc]]");
//执行结果如下
a
d
simpletest("an", "[a-z&&[^m-p]]");
//执行结果如下
a
现在我们清楚的看出来,一个字符类,也就是[]及中间内容代表一个范围,表示匹配一个字符,中括号中包含这个字符可能出现的所有情况,由于检测工具中使用了循环查找匹配,所以输出结果会查找到多个字符打印出来
预定义字符类
预定义字符类,是正则表达式中代表一组字符的特殊表示,由\打头,如下为JAVA API 中Pattern类的预定义字符类列表
.: 任何字符(与行结束符可能匹配也可能不匹配)
\d:数字:[0-9]
\D:非数字: [^0-9]
\s:空白字符:[ \t\n\x0B\f\r]
\S:非空白字符:[^\s]
\w:单词字符:[a-zA-Z_0-9]
\W:非单词字符:[^\w]
案例
simpletest("自由12345飞翔", "\\d{5}"); //同理,\d在JAVA中需要转义
//执行结果如下
12345
simpletest("自由12345飞翔", "\\D+"); //预定义数量词稍后再说
//执行结果如下
自由
飞翔
simpletest("自由 \t飞翔", "\\s+");
//执行结果如下
` `//此处匹配到一个空格和一个制表符
simpletest("自由 \t飞翔", "\\S+");
//执行结果如下
自由
飞翔
simpletest("自由abc飞翔", "\\w+");
//执行结果如下
abc
simpletest("自由abc飞翔", "\\W+");
//执行结果如下
自由
飞翔
数量词
默认数量词
正则匹配中字符都有要匹配的数量,如果没有加数量词,默认数量为1,匹配一个的意思
案例1
simpletest("自由12345飞翔", "\\D");
//执行结果如下
自
由
飞
翔
simpletest("自由12345飞翔", "\\D+");
//执行结果如下
自由
飞翔
如上案例中\\D代表匹配查找非数字字符,默认数量词为1,所以查找到一个非数字字符后直接打印后,便进入下次查找,结果如上第一段代码
如上案例中\\D+中引入+号预定义量词,代表匹配大于等于1次的连续非数字字符,所以匹配到自由后进入下一次查找
自定义量词
用户希望匹配几次,就给定匹配次数,我这里姑且叫它自定义量词吧。由大括号,上下限数量组成,上限数量可以缺少
{n}:恰好n个{n,}:大于等于n个{n,m}:大于等于n个,小于等于m个
注意:并没有{,m}这种写法
案例
simpletest("自由12345飞翔", "\\d{2}");
//执行结果如下
12
simpletest("自由12345飞翔", "\\d{2,}");
//执行结果如下
12345
simpletest("自由12345飞翔", "\\d{2,4}");
//执行结果如下
1234
simpletest("自由12345飞翔", "\\d{,7}");
//执行结果如下
报错 Exception in thread "main" java.util.regex.PatternSyntaxException: Illegal repetition near index 1
从上面案例中我们已经看出,量词只形容最近字符的数量,大括号中可以指定具体字符的具体数量或者范围。
预定义量词
预定义量词是正则中用?,+,* 三个符号表示特定意思的量词
?:一次或者零次+:一次或者多次*:零次或者零次以上
案例1
simpletest("自由12345飞翔", "\\d?");
//执行结果如下
//空行
//空行
1
2
3
4
5
//空行
//空行
这里要特别解释一下两个空行的产生,正则引擎去自由12345飞翔查找\\d?时,逐个字符从左到右查找,由于?表示一个或者零个,所以第一个字符匹配成功得到0个数字,也就是一个空字符,所以打印出来,而后面匹配到1个数字“1”打印出来,在匹配到1个数字“2”打印出来、、
案例2
simpletest("自由12345飞翔", "\\d+");
//执行结果如下
12345
这里匹配至少一个数字,直接匹配到5个数字“12345”输出
案例3
simpletest("自由12345飞翔", "\\d*");
//执行结果如下
//空行
//空行
12345
//空行
//空行
这里出现空行的原因和案例1中相同,因为\d*代表0次或者0次以上
边界标识符
如下为JAVA API 中Pattern类的边界标识符列表
^ :行的开头
$ :行的结尾
\b :单词边界
\B :非单词边界
\A :输入的开头
\G :上一个匹配的结尾
\Z :输入的结尾,仅用于最后的结束符(如果有的话)
\z :输入的结尾
目前并没完全弄明白所有边界标识符的用法,抱歉,仅演示几个。
案例1
simpletest("自由12345飞翔", "^\\d+");
simpletest("12345飞翔", "^\\d+");
//执行结果如下
12345
^\\d+查找行开头紧跟1次或多次数字,显然自由12345飞翔匹配失败,因为12345并非行首,而12345飞翔匹配成功得到12345
案例2
simpletest("自由12345飞翔", "^\\d+$");
simpletest("12345飞翔", "^\\d+$");
simpletest("自由12345", "^\\d+$");
simpletest("12345", "^\\d+$");
//执行结果如下
12345
当\\d+前面加上行首边界,后面加上行尾边界后,该正则只能匹配到一串纯数字,且数量满足+量词
案列3
simpletest("自由12345飞翔", "\\b\\d+");
//执行结果如下
//啥也没有
simpletest("自由 12345飞翔", "\\b\\d+");
//执行结果如下
12345
simpletest("自由12345 飞翔", "\\d+\\b");
//执行结果如下
12345
simpletest("12345", "\\d+\\b");
//执行结果如下
12345
simpletest("12345", "\\b\\d+");
//执行结果如下
12345
从案例3中我们可以看出所谓的\b单词边界就是指空格或者行首行位(或许还有其他,反正匹配到一个连续的词的结束或者开始位置)
案例4
simpletest("自由12345飞翔", "\\B\\d+");
//执行结果如下
12345
simpletest("自由 12345飞翔", "\\B\\d+");
//执行结果如下
2345
\B为非单词边界,和\b恰好相反,但案例4中效果却和案例3中不是相反,不能匹配到12345,因为前面有空格,但2345前面是1,是非单词边界,所以匹配成功
正则组
至此前面,基本上把正则表达式简单运用讲完,现在我们来引入一个词正则组,正则组是用()把一组字符当做一个整体,可以通过方法将这个组匹配到的字符单独取出,同样可以通过下标引用之前匹配到的该组的字符
简单应用
案例
@Test
public void grouptest( ){
String regex="\\d(\\d+)(\\D+)";
String target="520LiLing";
Pattern p = Pattern.compile(regex);
Matcher matcher = p.matcher(target);
while (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.group(2));
System.out.println(matcher.group(3));
}
}
//执行结果如下
520LiLing
20
LiLing
Exception in thread "main" java.lang.IndexOutOfBoundsException: No group 3
从简单案例中可以看出()中匹配到的数字可以用matcher.group(1)方法取出,1代表第一组,案例中第一组为(\d+),第二组为(\D+),第三组没找到,报错。而matcher.group(1)代表整个正则表达式匹配到的内容。
复杂组序
JAVA API 中Pattern类中有关于正则组顺序的介绍,当遇到复杂的正则组时,怎么来确定组的序号。
((A)(B(C)))表示一个正则表达式,A,B,C分别代表随意一个表达式
- group(1):
((A)(B(C))) - group(2):
(A) - group(3):
(B(C)) - group(4):
(C)
从上面的列表说明不难总结出一个规律,将正则表达式从左到右读过来,依次遇到()中的左括号(依次编号,先遇到哪一组的左括号先编号
案例
@Test
public void grouptest( ){
String regex="((\\d)(\\d+(\\D+)))";
String target="520LiLing";
Pattern p = Pattern.compile(regex);
Matcher matcher = p.matcher(target);
while (matcher.find()) {
System.out.println(matcher.group(1));
System.out.println(matcher.group(2));
System.out.println(matcher.group(3));
System.out.println(matcher.group(4));
}
}
//执行结果如下
520LiLing
5
20LiLing
LiLing
案例和上文说明完全一致,1组为((\\d)(\\d+(\\D+))),2组为(\\d),3组为(\\d+(\\D+)),4组为(\\D+)
捕获组
前面已经讲过关于正则组的编号,以及引用,但这样的作用似乎还不够强大。捕获组,就是将之前的正则组通过\组序号捕获,如\1(任然需要转义\\1),再次利用。(解释起来太费劲,看案例吧)
@Test
public void grouptest( ){
String regex="(\\d+).+\\1";
String target="520Li320Ling";
Pattern p = Pattern.compile(regex);
Matcher matcher = p.matcher(target);
while (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
}
}
//执行结果如下
20Li320
20
上面案例中,正则表达式(\\d+).+\\1 的意思就是先查找到数字标记为组1,然后跟着任意字符,跟着\\1表示捕获和组1一模一样的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号