
【Demo 1】基于object_detection API的行人检测 2:数据制作
项目文件结构
因为目录太多又太杂,而且数据格式对路径有要求,先把文件目录放出来。(博主目录结构并不规范)
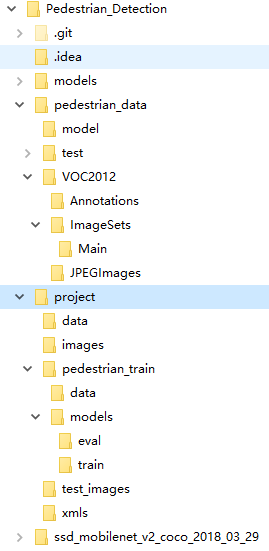
1、根目录下的models为克隆下来的项目。2、pedestrian_data目录下的路径以及文件夹名称必须相同,是VOC2012数据格式要求。3、project中data是视频数据,images是测试的图片数据、test_images为测试图片数据集,pedestrian_train文件夹为训练目录。
使用公开数据制作训练数据集
数据下载
视频数据下载:http://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009 bbenfold_headpose/Datasets/TownCentreXVID.avi
标注数据下载:http://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009 bbenfold_headpose/Datasets/TownCentre-groundtruth.top
官网(http://www.robots.ox.ac.uk/ActiveVision/index.html)
使用OpenCV生成图片数据
import cv2 as cv import os def video2ims(src, train_path="images", test_path="test_images", factor=2): os.mkdir(train_path) os.mkdir(test_path) frame = 0 cap = cv.VideoCapture(src) counts = int(cap.get(cv.CAP_PROP_FRAME_COUNT)) w = int(cap.get(cv.CAP_PROP_FRAME_WIDTH)) h = int(cap.get(cv.CAP_PROP_FRAME_HEIGHT)) print("number of frames : %d"%counts) while True: ret, im = cap.read() if ret is True: if frame < 3600: # 前3600帧作为训练数据 path = train_path else: path = test_path im = cv.resize(im, (w//factor, h//factor)) # 压缩分辨率 cv.imwrite(os.path.join(path, str(frame)+".jpg"), im) frame += 1 else: break cap.release() if __name__ == "__main__": video2ims("Your TownCentreXVID.avi path")
把生成的图片拷贝到./pedestrian_data/OC2012/JPEGImages 目录下,图片大小为960*540。
制作Pasacal VOC2012数据集格式
利用标注信息文件TownCentre-groundtruth.top生成对应xml文件(注意文件路径)
import os import pandas as pd if __name__ == '__main__': GT = pd.read_csv('D:/Study/dl/Pedestrian_Detection/TownCentre-groundtruth.top', header=None) indent = lambda x, y: ''.join([' ' for _ in range(y)]) + x factor = 2 train_size = 3600 os.mkdir('xmls') name = 'pedestrian' width, height = 1920 // factor, 1080 // factor for frame_number in range(train_size): Frame = GT.loc[GT[1] == frame_number] x1 = list(Frame[8]) y1 = list(Frame[11]) x2 = list(Frame[10]) y2 = list(Frame[9]) points = [[(round(x1_), round(y1_)), (round(x2_), round(y2_))] for x1_, y1_, x2_, y2_ in zip(x1, y1, x2, y2)] with open(os.path.join('xmls', str(frame_number) + '.xml'), 'w') as file: file.write('<annotation>\n') file.write(indent('<folder>voc2012</folder>\n', 1)) file.write(indent('<filename>' + str(frame_number) + '.jpg' + '</filename>\n', 1)) file.write(indent('<path>D:/Study/dl/Pedestrian_Detection/pedestrian_data/VOC2012/JPEGImages/' + str(frame_number) + '.jpg' + '</path>\n', 1)) file.write(indent('<size>\n', 1)) file.write(indent('<width>' + str(width) + '</width>\n', 2)) file.write(indent('<height>' + str(height) + '</height>\n', 2)) file.write(indent('<depth>3</depth>\n', 2)) file.write(indent('</size>\n', 1)) for point in points: top_left = point[0] bottom_right = point[1] if top_left[0] > bottom_right[0]: xmax, xmin = top_left[0] // factor, bottom_right[0] // factor else: xmin, xmax = top_left[0] // factor, bottom_right[0] // factor if top_left[1] > bottom_right[1]: ymax, ymin = top_left[1] // factor, bottom_right[1] // factor else: ymin, ymax = top_left[1] // factor, bottom_right[1] // factor file.write(indent('<object>\n', 1)) file.write(indent('<name>' + name + '</name>\n', 2)) file.write(indent('<pose>Unspecified</pose>\n', 2)) file.write(indent('<truncated>' + str(0) + '</truncated>\n', 2)) file.write(indent('<difficult>' + str(0) + '</difficult>\n', 2)) file.write(indent('<bndbox>\n', 2)) file.write(indent('<xmin>' + str(xmin) + '</xmin>\n', 3)) file.write(indent('<ymin>' + str(ymin) + '</ymin>\n', 3)) file.write(indent('<xmax>' + str(xmax) + '</xmax>\n', 3)) file.write(indent('<ymax>' + str(ymax) + '</ymax>\n', 3)) file.write(indent('</bndbox>\n', 2)) file.write(indent('</object>\n', 1)) file.write('</annotation>\n') print('File:', frame_number, end='\r')
生成的xml文件全部复制到 ./pedestrian_data/OC2012/Annotations 目录下。
xml文件中标注的信息有:图片名称,目标,大小,通道数,目标所在位置,样本难易。
生成图片描述文件
用txt文件对图片进行描述,生成代码如下:
import os def generate_classes_text(): print("start to generate classes text...") m_text = open("D:/Study/dl/Pedestrian_Detection/pedestrian_data/trainval.txt", 'w') for i in range(3600): m_text.write(str(i) + " 1 \n") m_text.close() if __name__ == '__main__': generate_classes_text()
生成的文件为:

第一列为图片编号,对应JPEGImages目录下的图片;第二列为1,表示存在行人数据。
这一份txt拷贝成两份,改名为pedestrian_train.txt和pedestrian_val.txt,放在./pedestrian_data/VOC2012/ImageSets/Main目录下。如果下一步生成record中报错,说缺少文件aeroplane_train.txt可以把这两个文件名中的pedestrian改成aeroplane。(理论上应该不会错,但我的时候就给我报错!)
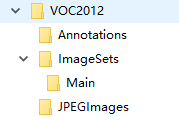
这样Pasacal VOC2012数据格式就准备完成了,目录结构是这样的:
生成 TF record
生成label_map.pbtxt文件,在txt中直接输入如下内容,并把后缀改成pbtxt即可。然后把label_map.pbtxt放在目录./Pedestrian_Detection/project/pedestrian_train/data下。
item { id: 1 name: 'pedestrian' }
在命令行窗口下的(dl) D:\Study\dl\Pedestrian_Detection\models\research>执行:
python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=D:\Study\dl\Pedestrian_Detection\project\pedestrian_train\data\label_map.pbtxt --data_dir=D:\Study\dl\Pedestrian_Detection\pedestrian_data --year=VOC2012 --set=train --output_path=D:\Study\dl\Pedestrian_Detection\pascal_train.record
和
python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=D:\Study\dl\Pedestrian_Detection\project\pedestrian_train\data\label_map.pbtxt --data_dir=D:\Study\dl\Pedestrian_Detection\pedestrian_data --year=VOC2012 --set=val --output_path=D:\Study\dl\Pedestrian_Detection\pascal_val.record
生成两份record文件。pascal_train.record和pascal_val.record
然后把这两份文件copy到目录:/Pedestrian_Detection/project/pedestrian_train/data下。这两个文件大小都为574M,千万要检查,不要把生成失败的record文件放入目录中。(这个错在后面训练的时候搞了我一下午!!!)
数据集准备完毕,record也准备完毕,下一篇将进行模型训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号