python -- 基础数据类型的补充/list、dict遍历删除/set的相关操作
一,基础类型的补充
补充基础数据类型的相关知识点
1. list. join() 把列表变成字符串
# list.spilt()字符串变成列表
#a.join(b) 把a插入到b中,打印结果为字符串 如果b是列表,则可以将列表转换成字符串 s = "abc" s1 = s.join("非常可乐") # 把字符串s插入到"非常可乐"中, print(s1) # 非abc常abc可abc乐(字符串类型) s = "tx".join("sb") #把"tx"插入到"sb"中, 打印结果为字符串类型 print(s) # stxb s = "_".join(["alex", "wuse", "taibai", "ritian"]) # join可以把列表变成字符串, # split()把字符串变成列表 print(s) # alex_wuse_taibai_ritian s = "sb".join(["王者荣耀", "LOL", "跑跑卡丁车"]) print(s) # 王者荣耀sbLOLsb跑跑卡丁车
2. 列表(lst)/字典(dict)不能在循环的时候删除. 因为索引会跟着改变
# 由于遍历列表过程中,每删除一个,列表发生改变,索引对应的值发生变化,所以遍历的时候删除不能完全清空列表, 字典也是一样
lst = ["我不是药神", "西游记", "西红柿首富", "天龙八部"] for el in lst: lst.remove(el) #遍历列表,删除遍历的元素 print(lst) #['西游记', '天龙八部'] 不能完全清空列表
#在遍历列表或者字典的时候,将想要删除的元素先存放在一个空列表中,然后遍历这个列表(自己创建的空列表)中存放的元素,过程中通过与原列表的对应关系进行删除 #遍历列表删除的时候,直接要把想删除的元素放在创建的空列表里,然后遍历这个列表,并删除其中元素
del_lst = [] #空列表,用于存放将要删除的内容 for el in lst: #遍历原列表 del_lst.append(el) # 记录下来要删除的内容 for el in del_lst: # 循环记录的内容(新列表) lst.remove(el) # 删除原来的内容 print(lst)
#清空列表
lst = ["我不是药神", "西游记", "西红柿首富", "天龙八部"] lst.clear() #清空列表 print(lst) #[]
#删除列表中姓周的人名
lst = ["周杰伦", "周润发", "周星星", "马化腾", "周树人"] del_lst = [] #新建一个空列表 for el in lst: #循环原列表 if el.startswith("周"): #判断原列表元素是否以"周"开头,或者写成lst[0]=="周" del_lst.append(el) #如果以周开头,则把周开头的元素放在新建列表里 for el in del_lst: #遍历新列表,获取新列表中元素 lst.remove(el) #删除原列表中元素 print(lst) #['马化腾']
3. 字典也不能直接循环删除/增加 (不能在循环的时候改变字典大小,会报错)
循环原字典,把要删除的内容记录在新建空列表中. 循环新列表. 删除对应字典中的数据,与列表一样
4. fromkeys()
不会对原来的字典产生影响. 产生新字典(神坑, 考试)
#注意:区别dic /dict, dict是字典的类名, dic是变量名 #.fromkeys是一个静态方法,可以由字典类(dict)以及字典的对象(若dic={},则dic(指向的东西)就是字典的对象)访问 #若是字典类dict(dict是一个类名),可以直接访问 #若是字典的对象访问,例如dic.fromkeys()需要在前面赋值一个变量. 如s=dic.fromkeys("woaini") #.fromkeys 会创建一个新字典,与原字典无关 a = dict.fromkeys(["jj", 'jay', 'taibai'], "sb") # 静态方法,dict是指字典的类名,直接访问,打印类型是字典 print(a) #{'jj': 'sb', 'jay': 'sb', 'taibai': 'sb'} dic = {} #给一个字典 dic.fromkeys("王健林", "思聪" ) # 无意义,由字典的对象访问,前面未赋值 print(dic) #{} 打印结果为原字典 dic = {"a":"123"} #给一个字典 s = dic.fromkeys("王健林", "思聪" ) # 返回给你一个新字典,和原字典无关 print(s) #{'王': '思聪', '健': '思聪', '林': '思聪'}
5. set集合.
不重复, 无序.(可以用来去重)
用{}把内部元素括起来
集合本身可变,但内部元素不可变,内部元素为int,str,tuple...,
集合中不能装集合,因为集合可变,集合内元素不可变
s = set() #set() 空集合 dic = dict() # {} 空字典 ss = str() # 空字符 i = int() # 0 空整型 lst = list() #[] 空列表 print(s,dic,ss,i,lst)
#集合是不重复的,集合用{}把元素括起来,集合set本身是可以改变的,但内部元素是不可变的
s = {"王者荣耀", "英雄联盟", "王者荣耀", 123, True, True} print(s) #{123, True, '英雄联盟', '王者荣耀'} 集合中的元素不可重复,默认执行去重操作 s = {123, {1,2,3}} print(s) ## 不合法,报错,集合中的元素是可哈希的,不可变的
#用集合对列表进行去重
lst = ["张强", "李强", "王磊", "刘伟", "张伟", "张伟", "刘洋", "刘洋"] s = set(lst) # 去重复 print(s) #{'刘洋', '王磊', '张伟', '张强', '李强', '刘伟'} # 类型变回来 set=>list lst = list(s) print(lst) #['刘洋', '王磊', '张伟', '张强', '李强', '刘伟']
# 冻结了的set集合. 可哈希的. 不可变 # 集合内部不能装集合,因为集合可以改变,但内部元素不能改变 # 集合内部可以装冻结了的集合
s = frozenset([1, 3, 6, 6, 9, 8]) # 可以去重复. 也是set集合 print(s) #frozenset({1, 3, 6, 8, 9}) 冻结了的集合也是集合,可去重 ss = {"a", s} print(ss) #{frozenset({1, 3, 6, 8, 9}), 'a'} ss集合内部可以装冻结了的s集合
6. 类型转换
想转换成什么.就用什么括起来
str=>int str=int()
int=>str int=str()
...
二,深浅拷贝
1. 直接赋值.
不会产生新对象,两个变量指向同一个对象. 对一个变量操作,对象改变,则另一个变量的对象也默认改变
# 左边=右边 赋值运算 左边表示变量,右边表示对象(数据),变量引用对象的内存地址,借此来指向对象(获取数据)
lst1 = ["金毛狮王", "紫衫龙王", "白眉鹰王", "青衣服王"] lst2 = lst1 # 列表, 进行赋值操作. 实际上是引用内存地址的赋值. 内存中此时只有一个列表(对象). 两个变量指向一个列表(对象) lst2.append("杨做事") # 对其中的一个变量进行操作. 其指向的列表(对象)发生改变,由于两个变量指向同一个对象,所以两个变量都跟着变 print(lst2) #['金毛狮王', '紫衫龙王', '白眉鹰王', '青衣服往', '杨做事'] print(lst1) # #['金毛狮王', '紫衫龙王', '白眉鹰王', '青衣服往', '杨做事'] print(id(lst1),id(lst2)) #565919359688 565919359688 内存地址一致

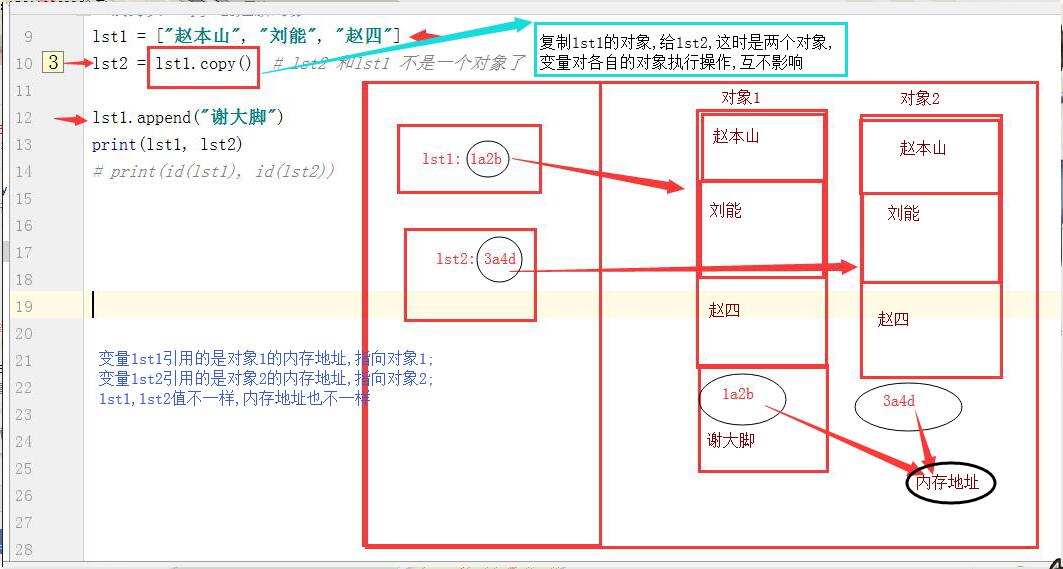
2. 浅拷贝: 创建新对象.只拷贝第一层内容. copy()
# 浅拷贝 copy 创建新对象,各自变量对应各自对象,互不影响
lst1 = ["赵本山", "刘能", "赵四"] lst2 = lst1.copy() # lst2 和lst1 不是一个对象了 # lst2 = lst1[:] # 切片也会产生新的对象 lst1.append("谢大脚") print(lst1, lst2) #['赵本山', '刘能', '赵四', '谢大脚'] ['赵本山', '刘能', '赵四'] print(id(lst1), id(lst2)) #571084776264 571084776136 内存地址不一样
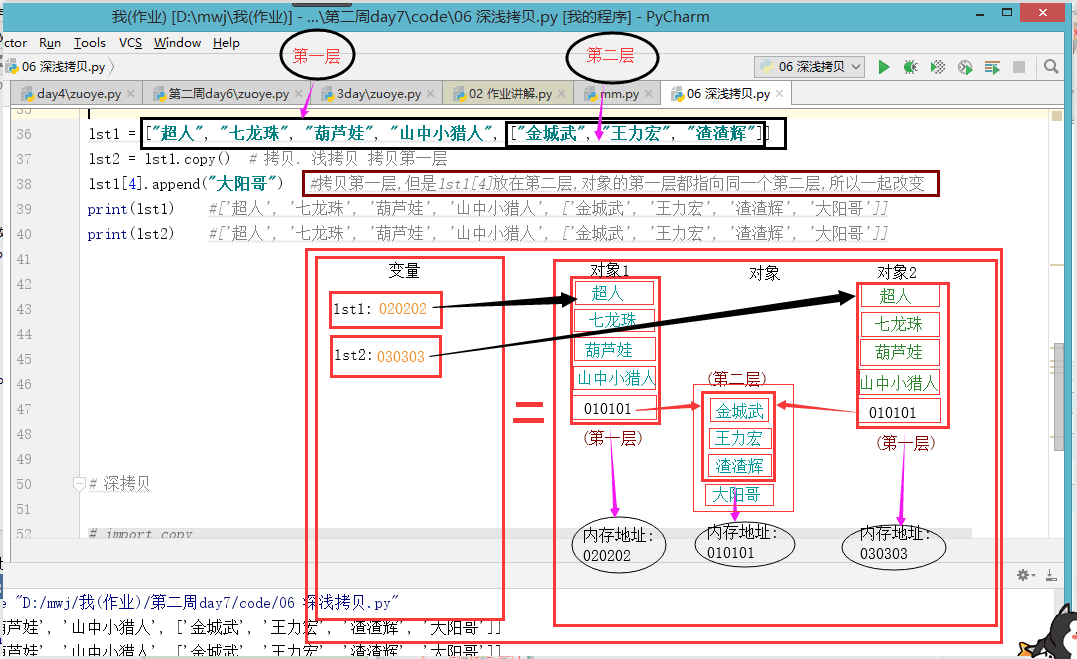
# 只拷贝第一层,但是第一层都指向同一个第二层,第二层改变,大家都改变
lst1 = ["超人", "七龙珠", "葫芦娃", "山中小猎人", ["金城武", "王力宏", "渣渣辉"]] lst2 = lst1.copy() # 拷贝. 浅拷贝 拷贝第一层 lst1[4].append("大阳哥") #拷贝第一层,但是lst1[4]放在第二层,对象的第一层都指向同一个第二层,所以一起改变 print(lst1) #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']] print(lst2) #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']] print(id(lst1),id(lst2)) #648994431688 648995194696 内存地址不一样
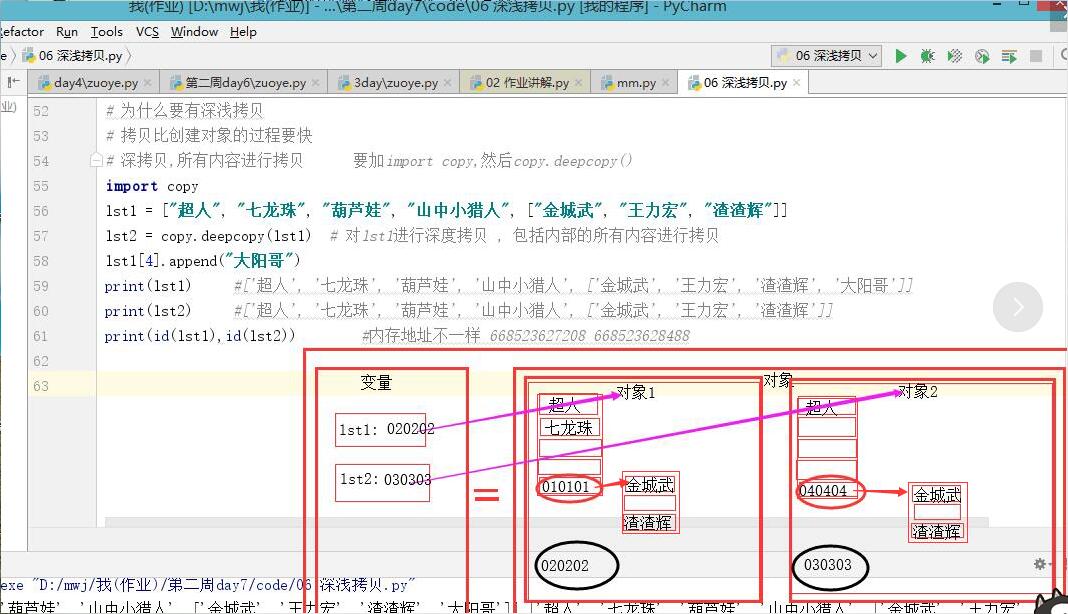
3. 深度拷贝: 对象中的所有内容都会被拷贝一份,常见出全新的对象
import copy
copy.deepcopy()
# 为什么要有深浅拷贝 # 拷贝比创建对象的过程要快 # 深拷贝,所有内容进行拷贝 要加import copy,然后copy.deepcopy()
import copy lst1 = ["超人", "七龙珠", "葫芦娃", "山中小猎人", ["金城武", "王力宏", "渣渣辉"]] lst2 = copy.deepcopy(lst1) # 对lst1进行深度拷贝 , 包括内部的所有内容进行拷贝 lst1[4].append("大阳哥") print(lst1) #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']] print(lst2) #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉']] print(id(lst1),id(lst2)) #内存地址不一样 668523627208 668523628488