python -- 编码/基本数据类型/字符串的操作
一.字符编码
1.ASCII码: 8位, 28=256个码位,最前一位始终是0, 最早计算机编码,由美国人创建的,包含了英文字母(大写/小写),数字,标点符号,特殊字符,还包含$%^@#...
2.GBK (国标码) 16位 2个字节
3.unicode 万国码 usc-2 16位 2字节
usc-4 32位 4字节
4.UTF-8 :英文 8bit 1byte 00000000
欧洲 16bit 2byte 00000000 00000000
中文 24bit 3byte 00000000 00000000 00000000
二.基本数据类型的概述

1.int
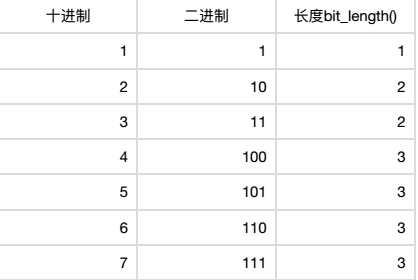
#bit_length() 计算整数在内存中占用的二进制码的长度 a = 3 # 1+1= 10 +1 = 11 print(a.bit_length()) # 二进制长度,11长度为2

2.布尔值(bool)
取值只有True,False # 空的东西都是False, 非空的东西都是True
# 字符串转换成数字 s = "128" i = int(s) print(type(i)) #结果是<class 'int '>
# bool类型转换成数字 True: 1 False:0 b = False c = int(b) print(c)
# int转换成bool 零: False 非零: True a = 0 b = bool(a) print(b)
s = "" # "" 空字符串表示False, 非空字符串表示:True if s: print("哈哈") else: print("呵呵") #结果是:呵呵
m = None # 空 连空气都不如. 真空, False if m : print("a") else: print("b") #b
3,字符串(str)
把字符连成串,用',",''',"""引起来的内容被称为字符串.
1)索引,也就是下标,从0开始
#索引 s = "我爱周杰伦" print(s[0]) #获取第0个,也就是"我" print(s[1]) #"爱" print(s[2]) print(s[3]) print(s[4]) print(s[-1]) #获取最后一个,倒着数,也就是"伦" print(s[-2]) #"杰" print(s[-3]) print(s[-4])
2)切片,利用下标截取部分字符串 的内容
通过索引获取到的内容. 还是一个字符串,切片可以对字符串进行截取
语法: s[起始位置: 结束位置]
特点: 顾头不顾腚
切片 s = "alex和wusir经常在一起" s1 = s[5:10] print(s1) #"wusir" s3 = s[5:] # 默认到结尾 s4 = s[:10] # 从头开始 s5 = s[:] # 从头到尾都切出来 s6 = s[-2:] # 从-2 切到结尾 默认从左往右切
3)步长,正负号分别表示从左往右数,从右往左数;大小表示每几个取一次
语法: s[起始位置: 结束位置: 步长]


三.格式化输出
S = "我叫{},今年{}岁了,我喜欢{}".format("sylar",18,"周杰伦")
S = "我叫{0},今年{1}岁了,我喜欢{2}".format("sylar",18,"周杰伦")
S = "我叫{name},今年{age}岁了,我喜欢{hobby}".format(name,age,hobby)
四.字符串的相关操作 (字符串是不可变的,任何操作对原字符串不会有任何影响)
1.大小写转来转去
s1.capitalize() #首字母换成大写
s1.lower() #全部转换成小写
s1.upper() #全部转换成大写
s1.swapcase() #大小写互换,大写换成小写,小写换成大写
s1.casefold() #全部转换为小写
s1.title() #被特殊字符或者汉字隔开的单词首字母大写
2.切来切去
s1.center(10,"*") #把字符串拉长为10位,不够的位数用*补全
s1.strip() #将字符串前后的空格去掉
s1.lstrip() #去掉左边空格
s1.rstrip() #去掉右边空格
s1.strip("abc") #去掉左右开头指定的元素.
s1.replace("old","new") #使用new替换old
s1.replace("old","new",2) #使用new替换前2个old
lst= s1.split("A") 将s1进行切割,用A切割,消耗掉的是A,并将切割好的字符串放入列表lst中
lst= s1.split("A",2) 将s1进行切割,,用A切割,消耗掉的是A,并将切割好的字符串放入列表lst中, 但是只对前面2个进行切割
3.查找
s1.startswith("abc") #判断是否以abc开头
s1.endswith("语言") #判断是否以"语言"结尾.
s1.count("a") #计算a在字符串中出现的此数
s1.find("a") #查找a出现的位置 找到==>返回位置 找不到===>返回-1
s1.index("a") #查找a出现的位置 找到===> 返回位置 找不到 ==> 程序报错!!!
4.条件判断
s1.isalnum() #判断是否字母和数字组成
s1.isalpha() #判断是否由字母组成
s1.isdigit() #判断是否由数字组成,不包含小数点
s1.isnumeric() #判断是否由数字组成,并且还识别中文的数字
s1.isupper() #判断是否是大写字母
s1.islower() #判断是否是小写字母
s1.isdigit() #判断是否是数字
5.迭代
for循环来遍历(获取)字符串中的每一个字符
可迭代对象:可以一个一个往外取值的对象
for循环,语法:
for 变量 in 可迭代对象:
循环体
while循环遍历
# count = 0
# while count < len(s):
# print(s[count])
# count = count + 1

