AlignedReID: Surpassing Human-Level Performance in Person Re-Identification
AlignedReID: Surpassing Human-Level Performance in Person Re-Identification
Abs
本文提出一种新的AlignedReID方法,提取全局特征,并与局部特征联合学习。全局特征学习从局部特征学习中获益很大,它通过计算两组局部特征之间的最短路径来进行对齐/匹配,而不需要额外的监督。
在联合学习之后,我们只保留全局特征来计算图像之间的相似度。该方法在Market1501和CUHK03获得rank1。
Intro
传统的方法专注于低级特征,如颜色、形状和局部描述。随着深度学习的复行,CNN已经主导了这一领域,通过各种度量学习如对比损失、三元组损失、改进三元组损失、四元组损失和难三元组损失。
许多基于cnn的方法学习全局特征,而不考虑人的空间结构,这有几个主要的缺点:
- 不准确的人检测框可能会影响特诊学习
- 姿态变化或非刚体变形使度量学习困难
- 人体被遮挡的部分可能会将不相关的背景引入到学习到的特征中
- 强调全局特征中的局部差异是很重要的,特别是当我们必须区分两个外观非常相似的人时
为了解决这些缺陷,有些工作将整个身体分为几个固定的部分,没有考虑到部分之间的对齐。然而, 它仍然遭受不准确的检测框,姿态变化和遮挡。
其他工作使用姿态估计结果进行对齐,这需要额外的监督和姿态估计步骤(这往往容易出错)
在本文中,提出了一种新的方法——AlignedReID(对齐ReID),它仍然学习全局特征,但是执行学习过程中的自动零件对齐,而不需要额外的监督或明确的姿态估计。 在学习阶段,用两个分支共同学习全局特征和局部特征。在局部分支中,通过引入最短路径损耗来对齐局部部分,在推理阶段,丢弃局部分支,只提取全局特征。发现仅应用全局特征几乎与组合全局特征和局部特征一样好。换句话说,全局特征本身,借助于局部特征学习,可以在新的联合学习框架中极大地解决上述缺陷。
在度量学习设置中,我们还采用了相互学习方法,以允许两个模型互相学习更好的表示。
Related Work
度量学习
将原始图像转化成嵌入特征,计算出的距离作为他们的相似度。
主要的方法技巧:
Triplet loss 会减小正负样本对的差距。通过hard mining 为训练模型选择合适的样本是有效的。将softmax loss 和metric learning loss 结合起来加速收敛也是普遍的方法
Feature Alignments
学习的全局特征来表示行人图像,但是忽略了图像的空间局部信息
一些模型尝试将图片分为多个部分学习局部信息,但是因为没有对齐依然不能解决检测框不准确,遮挡以及姿态错位的问题
近期流行的alignments方法:
pose estimation 例如,姿势不变嵌入(PIE)将行人与标准姿势对齐,以减少姿势变化的影响
Global-LocalAlignment Descriptor (GLAD) :没有直接对齐行人,而是检测姿态关键点并且从相应的区域提取局部特征
SpindleNet:使用了region proposed network (RPN) 产生一些身体区域,在不同阶段,逐渐联合response maps from 临近的身体部位
以上方法的共性:需要额外的pose annotation,pose estimation会带来相应的error
Mutual Learning
相互学习
DarkRank:通过交叉样本相似度来提升模型压缩和加速
AlignedReID:将Mutual Learning用于Metric Learning环境
Re-Ranking
获得图像特征后,多数人用L2 Euclidean distance 来计算相似度
进行了一个额外的re-ranking改善reid性能
还有采用含有kreciprocal encoding 的re-ranking method
该方法结合了原始距离和Jaccard距离
AlignedReID
在AlignedReID中,我们生成一个全局特征作为输入图像的最终距离,并使用L2距离作为相似度度量。但在学习阶段,全局特征与局部特征是联合学习的。
对于每一张图像,我们使用一个CNN(例如Resnet50),提取一个\(C\times H \times W\)特征图(作为最后一个卷积层的输出C为通道号,\(H\times W\)为空间大小,如FIgure2中的\(2048\times7\times7\))
提取全局特征:
在特征图上直接进行全局池化得到全局特征
提取局部特征:
首先进行水平池化(即水平方向的全局池化),为每一行提取一个局部特征,然后利用\(1\times1\)卷积将通道数从C降为c。这样,每个局部特征代表人的图像水平部分。
因此,一个人的图像由一个全局特征和H个局部特征表示。
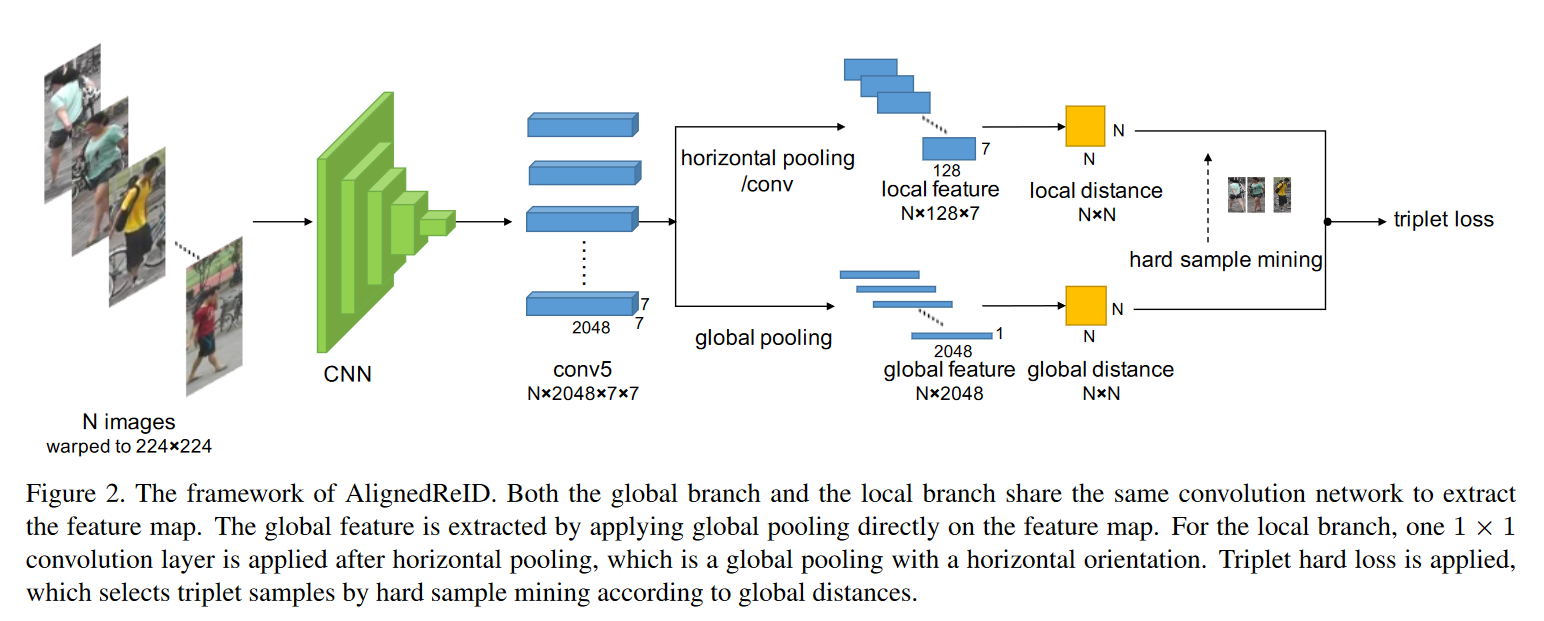
两个人的距离是其全局距离和局部距离的总和。全局距离就是全局特征的L2距离。对于局部距离,我们从上到下动态匹配局部部分,以找到总距离最小的局部特征部分。这是基于一个简单的假设,即对于同一个人的两幅图像,第一幅图像中某一身体部位的局部特征与另一幅图像中语义上对应的身体部位更加相似。
给定两张图片的局部特征\(F = \left \{ f_1, \dots, f_H\right \}\) 和 \(G = \left \{ g_1, \dots, g_H\right \}\) ,先用公式:
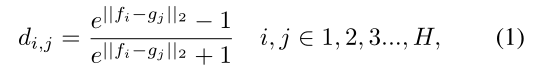
来定义\(d_{i, j}\)
其中\(d_{i,j}\)表示第一个图像的第i个垂直部分与第二个头像的第j个垂直部分之间的距离。基于这些距离形成一个距离矩阵D,其中(i, j)元素为\(d_{i, j}\),我们将两幅图像之间的local distance为矩阵D中从(1, 1)到(H,H)的最短距离总和,计算公式如下:
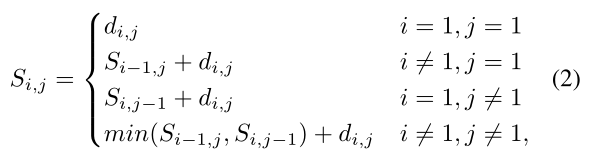
右边的黑色箭头表示对应距离矩阵中的最短路径,左边黑线表示两幅图像之间的对应对齐。
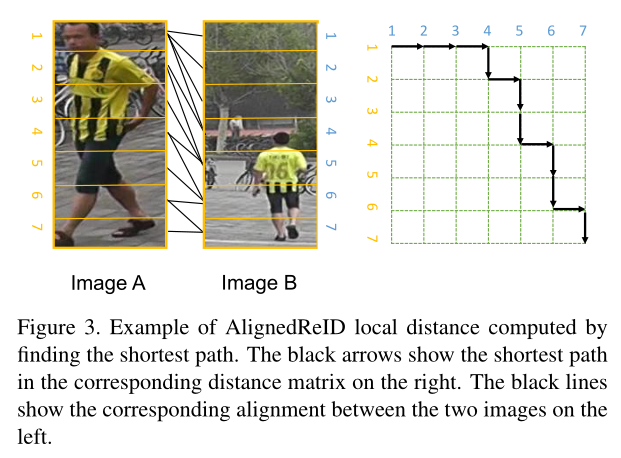
如图所示,这条最短路径上有一些边是冗余的,原因是:局部信息不仅要自我匹配,也要考虑到整个人对齐的进程,为了使匹配能够从头到脚按顺序进行,那么有一些冗余的匹配是必须的。另外,通过设计局部距离函数,这些冗余匹配在整个最短路径中的长度贡献很小。
1)Part model能够对目标特征进行细粒度刻画,是非常必要的
2)最短路径包含非相关特征(如part1<->part1),这非但不会对结果造成影响,而且还会对维护垂直方向对齐的次序起着至关重要的作用。
即 路径规划本身隐含了自上而下的顺序。
注:非相关特征距离d比较大,其梯度接近于0,因此对于最短路径的贡献是比较小的。
全局距离和局部距离共同定义了学习阶段两幅图像之间的相似度,我们选择TriHard Loss作为度量学习损失。对每个样本,根据全局距离,选择相同恒等式中最不相似的和不同恒等式中最相似的,得到一个三元组。对于三元组,损失分别根据全局距离和不同余量的局部距离计算。使用全局距离来挖掘硬样本的原因有两个方面的考虑。首先,全局距离的计算速度远远快于局部距离的计算速度。其次,我们观察到使用两种距离挖掘硬样本没有显著差异。
值得注意的是,在推断阶段,我们使用全局特征来计算两个人图像的相似度(之所以这么做是因为我们意外的发现全局特征本身几乎与组合特征一样好)
原因可能是:
- 特征图联合学习比只学习全局特征更好,因为我们在学习阶段已经利用了人的形象的先验结构
- 在局部特征匹配的帮助下,全局特征可以将更多的注意力放在人的身体上,而不是过度贴合背景
Mutual Learning for Metric Learning
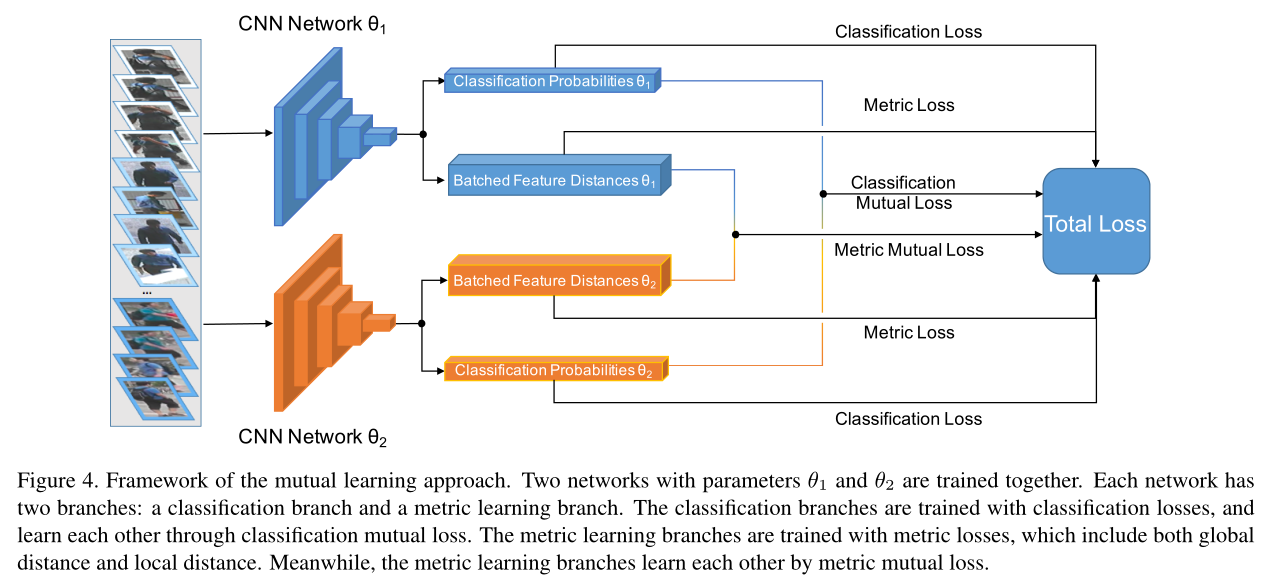
为什么使用Mutual learning
为了增强模型的效果。前人很多都采用了distillation的方法来训练teacher-student网络。本文作者提出:
1)同时训练一组student models,让它们相互学习;
2)采用了损失函数的联合体,即:
metric loss:由global local distance共同产生
metric mutual loss:由global distance决定
classification loss:
classification mutual loss:由KL divergence for classification决定
如何理解mutual learning approach的结构图
输入一个batch的image,尺寸为(N,w,h,c),经过两个不同initialized CNN网络提取到global features后,各自得到两个输出结果,分别为:一个是关于classification probabilities的tensor或者matrix;另一个是一个NxN的matrix,它是由N张图之间的global feature distance构建的matrix里的每一个值。
根据上面的四个matrices,可以构建4个loss。其中classification mutual loss帮助实现两个模型在classification 上的相互学习;metric mutual loss帮助实现两个模型在metric learning(相似性)上的相互学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号