
https://www.jb51.net/article/179139.htm
#coding=utf-8 import requests import re import socket import json from bs4 import BeautifulSoup socket.setdefaulttimeout(20) headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'} r=requests.get("https://search.51job.com/list/020000,000000,0000,00,9,99,%25E6%25B5%258B%25E8%25AF%2595,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=", headers=headers) soup=BeautifulSoup(r.text,'html.parser') for tag in soup.find_all('span',{'class':'jname_at'}): print(tag.get_text())
get获取网页信息后有几种方式查找页面元素值
第一种:通过BeautifulSoup格式化内容,然后通过其find_all方法查找某个元素的值,类型:<class 'bs4.element.ResultSet'>
第二种:通过re正则表达式匹配,正则表达式获取后的类型是list
findtxt=re.findall(r'\{\"top_ads[\s\S]*招聘\"\}',t)
txt=json.dumps(findtxt)#将list转换成josn
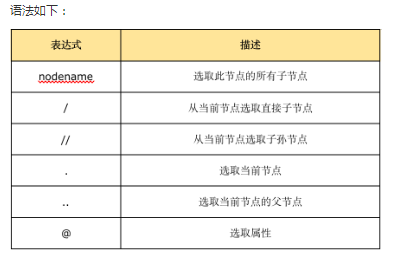
第三种:from lxml import etree 通过etree格式化后xpath匹配,有的时候抓取的内容并不一定就是json格式的,所以直接resp.json()就会报错,需要查找后读取
txt=etree.HTML(resp.text())
result=txt.xpath('//script[@type="text/javascript"]')#获取标签script,type属性是text/javascript的元素
e=json.loads(result[2].text[28:])#转换后是dict类型 (读取查找到的第三个script标签的值,并作截取)
#用json转换有时存在非双引号的问题,推荐使用ast.literal_eval函数
print(e['engine_search_result'][0]['company_name'])#读取字典嵌套列表内容
错误:
ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号