
数据分析的学习之路
Python程序是大小写敏感
1.0 数据类型
整数,浮点数(小数),字符串,布尔值,空值,变量,常量(惯用大写表示常量)
内置数据类型list, 元组(tuple:一旦初始化就不能修改)
字典dict, 使用键-值(key-value)存储,具有极快的查找速度, list是可变的,就不能作为key
set, set可以看成数学意义上的无序和无重复元素的集合
Print(3/2) 结果1
Print(3.0/2) 结果1.5
Print(1.0/3) 结果0.333333333333
Python可以反复赋值,而且可以是不同类型的变量
List-> classmates=[‘Machael’,’Daisy’,’John’]
Tuple-> classmates=(‘Machael’,’Daisy’,’John’)
Dict -> d={‘Machael’:90,’ Daisy’:96,’John’:78}
1.1 切片
Python没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单
L = ['Michael','Sarah','Tracy','Bob','Jack']
>>>L[1:3]
['Sarah', 'Tracy']
L[0:3]=L[:3]
记住倒数第一个元素的索引是-1
list有len(), 追加元素到末尾append(),插入元素insert(),删除末尾元素pop()
1.2 迭代
我理解就是遍历,只不过好多都是可迭代对象,可以用来遍历
Python的for循环抽象程度要高于C的for循环,因为Python的for循环不仅可以用在list或tuple上,还可以作用在其他可迭代对象上。
list这种数据类型虽然有下标,但很多其他数据类型是没有下标的,但是,只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代
>>>d = {'a':1,'b':2,'c':3}
>>> forkeyind:
... print(key)
...acb1.3 列表生成式
是Python内置的非常简单却强大的可以用来创建list的生成式
>>>[x * xforxinrange(1,11)]
[1,4,9,16,25,36,49,64,81,100]
>>>[m + nformin'ABC'fornin'XYZ']
['AX','AY','AZ','BX','BY','BZ','CX','CY','CZ']
1.4 生成器
在Python中,这种一边循环一边计算的机制,称为生成器:generator
只要把一个列表生成式的[]改成(),就创建了一个generator
g=(x * x for x in range(1, 11))- - 只能通过上面的迭代访问
变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行
1.5 迭代器
2.0 各字符编码的区别
ASCII编码是1个字节的,只能存英文
Unicode编码通常2个字节,可以存汉字,如果仅存英文,浪费存储
UTF-8编码,可变长度英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
3.0 字符串
Chr() 字符
格式化
1)%d 整数,%f 浮点数,%s字符串
print('%.2f'%3.1415926) 结果3.14
2)format()
4.0 条件判断 if : else
age =3
ifage >=18:
print('adult')
elifage >=6:
print('teenager')
else:
print('kid')
5.0 循环
for...in循环,依次把list或tuple中的每个元素迭代出来
sum =0
forxin[1,2,3,4,5,6,7,8,9,10]:
sum = sum + xprint(sum)
sum =0
n =99
whilen >0:
sum = sum + nn = n -2
print(sum)
continue的作用是提前结束本轮循环,并直接开始下一轮循环。
break的作用是提前结束循环。
6.0 函数
正常的函数和变量名是公开的(public)
类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途
类似_xxx和__xxx这样的函数或变量就是非公开的(private)
内置函数https://docs.python.org/2.7/library/functions.html
6.1 位置参数x
https://docs.python.org/2.7/library/functions.html#abs
def my_abs(x):
if x >= 0:
return x
else:
return –x
6.2 默认参数
def power(x, n=2):
s =1
whilen >0:
n = n -1
s = s * xreturns
power(5)=power(5,2) power(5,3)
6.3 可变参数
允许你传入0个或任意个参数
def calc(*numbers):
sum =0
forninnumbers:
sum = sum + n * nreturnsum
calc(1,2,4,5)
6.4 关键字参数
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict
def person(name, age, **kw):
print('name:', name,'age:', age,'other:', kw)
person('Adam',45, gender='M', job='Engineer')
6.5 命名关键字参数
6.6 参数组合
def f2(a, b, c=0, *, d, **kw):
print('a =', a,'b =', b,'c =', c,'d =', d,'kw =', kw)
>>>f2(1,2, d=99, ext=None)
a =1b =2c =0d =99kw = {'ext':None}
递归函数--如果一个函数在内部调用自身本身,这个函数就是递归函数
def fact(n):
ifn==1:
return1
returnn * fact(n -1)
尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
range()函数,可以生成一个整数序列
>>>list(range(5))
[0, 1, 2, 3, 4]
enumerate函数可以把一个list变成索引-元素对
6.7 高阶函数
一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数
def add(x, y, f):
return f(x) + f(y)
>>>add(-5,6,abs)
#abs是求绝对值的,结果为11
map() ,reduce(),filter()接收一个函数和一个序列作为参数
sorted()排序
>>> def f(x):
...returnx * x
...>>>r = map(f, [1,2,3,4,5,6,7,8,9]) #函数,序列。然后序列中的值按照函数进行计算
>>> list(r)
[1,4,9,16,25,36,49,64,81]
6.8 返回函数
6.9 匿名函数
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
6.10 偏函数
简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单
>>>int('1000000', base=2)
64
#--原意就是将1000000转换成2进制
>>> import functools
>>>int2 = functools.partial(int, base=2)
函数对象有一个__name__属性,可以拿到函数的名字
7.0 模块
一个.py文件就称之为一个模块(Module)
Python又引入了按目录来组织模块的方法,称为包(Package)。每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ ='Michael Liao'
import sys
def test():
args = sys.argviflen(args)==1:
print('Hello, world!')
eliflen(args)==2:
print('Hello, %s!'% args[1])
else:
print('Too many arguments!')
if__name__=='__main__':
test()第1行和第2行是标准注释,第1行注释可以让这个hello.py文件直接在Unix/Linux/Mac上运行,第2行注释表示.py文件本身使用标准UTF-8编码;
第4行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第6行使用__author__变量把作者写进去
当我们在命令行运行hello模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
8.0 面向对象
classStudent(object):
def __init__(self, name, score):
self.name = name self.score = scoreclass后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类
注意到__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身
通过定义一个特殊的__init__方法,在创建实例的时候,就把name,score等属性绑上去
注意:特殊方法“__init__”前后分别有两个下划线!!!
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self
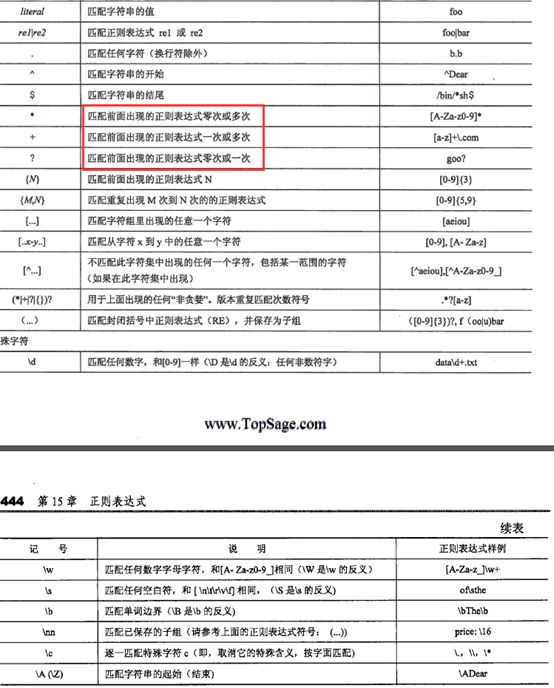
9.0 正则表达式
http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html
|
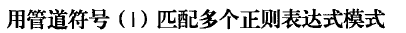
.

^ $


[]

-

?

{M,N}

()

re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
Eg:

10.0 小技巧
Python允许用'''...'''的格式表示多行内容
>>> print('''line1
... line2
... line3''')
line1
line2
line3
大小写敏感
Python还允许用r''表示''内部的字符串默认不转义
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
>>>t = (1,)
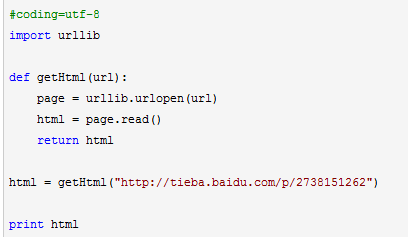
Import urllib Urllib 模块提供了读取web页面数据的接口
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据
urllib.urlretrieve()方法,直接将远程数据下载到本地
Eg: 爬虫技术
Python本身没有任何机制阻止你干坏事,一切全靠自觉。?????????

 浙公网安备 33010602011771号
浙公网安备 33010602011771号