合成数据平台:释放结构化数据的生成式 AI 的力量
推荐:使用NSDT场景编辑器快速助你搭建可二次编辑的3D应用场景
创建机器学习或深度学习模型非常简单。如今,有不同的工具和平台不仅可以自动化创建模型的整个过程,甚至可以帮助您为特定数据集选择最佳模型。
通过创建模型解决问题所需的基本内容之一是包含描述您尝试解决的问题的所有必需属性的数据集。因此,假设我们正在查看描述患者糖尿病病史的数据集。将有特定的列是年龄、性别、葡萄糖水平等重要属性。在预测一个人是否患有糖尿病方面起着至关重要的作用。为了建立一个糖尿病预测模型,我们可以找到多个公开可用的数据集。但是,在解决数据不容易获得或高度不平衡的问题时,我们可能会面临困难。
什么是合成数据?
当数据访问受到隐私合规性的限制或需要增强原始数据以适应特定目的时,深度学习算法生成的合成数据通常用于替换原始数据。合成数据通过重新创建统计属性来模拟真实数据。一旦对真实数据进行了训练,合成数据生成器就可以创建任意数量的数据,这些数据与真实数据的模式、分布和依赖关系非常相似。这不仅有助于生成类似的数据,还有助于对数据引入某些约束,例如新的分布。.让我们探讨一些合成数据可以发挥重要作用的用例。
- 生成机密数据:银行、保险、医疗保健甚至电信领域的数据可能非常敏感。接触这些数据通常需要每个项目的特殊权限,合成数据生成可以解锁这些数据资产,并用于创建功能、了解用户行为、测试模型和探索新想法。
- 重新平衡数据: 使用合成数据生成器可以有效且轻松地重新平衡高度不平衡的数据。比朴素的上采样效果更好,并且在高度不平衡的情况下,如欺诈模式,它可以优于更复杂的方法,如 SMOTE。
- 插补缺失的数据点: 当您处理数据时,NUL 值是生活中烦人的一部分。用有意义的合成数据点填充这些空白可以使阅读样本成为一种信息更丰富的练习。
合成数据是如何生成的?
生成式 AI 模型在合成数据生成中至关重要,因为它们是在原始数据集上显式训练的,并且可以复制其特征和统计属性。生成式 AI 模型,例如生成对抗网络 (GAN) 或变分自动编码器 (VAE),可以理解基础数据并生成现实且具有代表性的合成实例。
有许多开源和闭源合成数据生成器,有些比其他的更好。在评估合成数据生成器的性能时,重要的是要考虑两个方面:准确性和隐私性。准确性需要很高,而不会使合成数据过度拟合原始数据,并且需要以不危及数据主体隐私的方式处理原始数据中存在的极值。一些合成数据生成器提供自动隐私和准确性检查 - 最好先从这些开始。大多数情况下,AI的合成数据生成器免费提供此服务 - 任何人都可以仅使用电子邮件地址设置帐户。
合成数据的优势
根据定义,合成数据不是个人数据。因此,它不受GDPR和类似隐私法的约束,允许数据科学家自由探索数据集的合成版本。合成数据也是在不破坏模式和相关性的情况下匿名行为数据的最佳工具之一。这两种品质使其在使用个人数据的所有情况下都特别有用 - 从简单的分析到训练复杂的机器学习模型。
但是,隐私并不是唯一的用例。合成数据生成还可用于以下用例:
- 数据增强:这有助于通过多样化训练数据来提高模型性能。
- 数据插补:用有意义的合成数据填充缺失的数据点。
- 数据共享:甚至可以在组织之外安全地共享。考虑研究合作或用真实数据演示产品。
- 再平衡:解决阶级失衡问题。
- 缩减采样:创建看起来与原始数据集相同且含义相同的海量数据集的较小版本。可用于初始数据探索,减少计算成本和时间。
最流行的合成数据生成工具
为了生成合成数据,我们可能会使用市场上可用的不同工具。让我们探索其中的一些工具并了解它们的工作原理。
- 主要是AI:MOST AI是创建结构化合成数据的先驱领导者。它使任何人都可以生成高质量、类似生产的合成数据,用于分析、AI/ML 开发和数据探索。.数据团队可以使用它来创建、修改和共享数据集,以克服使用真实、匿名或虚拟数据的道德和实际挑战。
- SDV: 最流行的开源 Python 库,用于合成数据生成。不是最复杂的工具,但当高精度不是硬性要求时,它可以完成更简单的用例。
- YData: 如果您想尝试在Azure或AWS市场上生成合成数据,YData的生成器可在两个平台上使用,提供符合GDPR的方式来为AI和机器学习模型生成数据。
有关合成数据工具和公司的完整列表,以下是包含合成数据类型的精选列表。
现在,当我们讨论了使用这些上述工具和库进行合成数据生成的优缺点时,现在让我们看看如何使用 Mostly AI,它是市场上最好的工具之一,易于使用。
MOSTLY AI 是一个合成数据创建平台,可帮助企业为机器学习、高级分析、软件测试和数据共享等多种用例生成高质量、受隐私保护的合成数据。它使用专有的 AI 算法生成合成数据,该算法学习原始数据的统计方面,例如相关性、分布和属性。这使得 MOST AI 能够生成在统计上代表实际数据的合成数据,同时保护数据主体的隐私。
它的合成数据不仅是私有的,而且使用简单,可以在几分钟内完成。该平台具有易于使用的界面,由生成式AI提供支持,使组织能够输入现有数据,选择合适的输出格式,并在几秒钟内生成合成数据。对于需要保护其数据隐私同时仍将其用于许多目标的组织来说,其合成数据是一种有益的工具。该技术使用简单,可快速创建高质量、具有统计代表性的合成数据。
来自 MOST AI 的合成数据以多种格式提供,包括 CSV、JSON 和 XML。它可以与多个软件程序一起使用,包括SAS,R和Python。此外,MOST AI提供了许多工具和服务,例如数据生成器,数据资源管理器和数据共享平台,以帮助组织使用合成数据。
让我们探索如何使用 MOST AI 平台。我们可以首先访问下面的链接并创建一个帐户。
主要是AI:合成数据生成和知识中心 - 主要是AI
创建帐户后,我们可以看到主页,我们可以在其中从与数据生成相关的不同选项中进行选择。
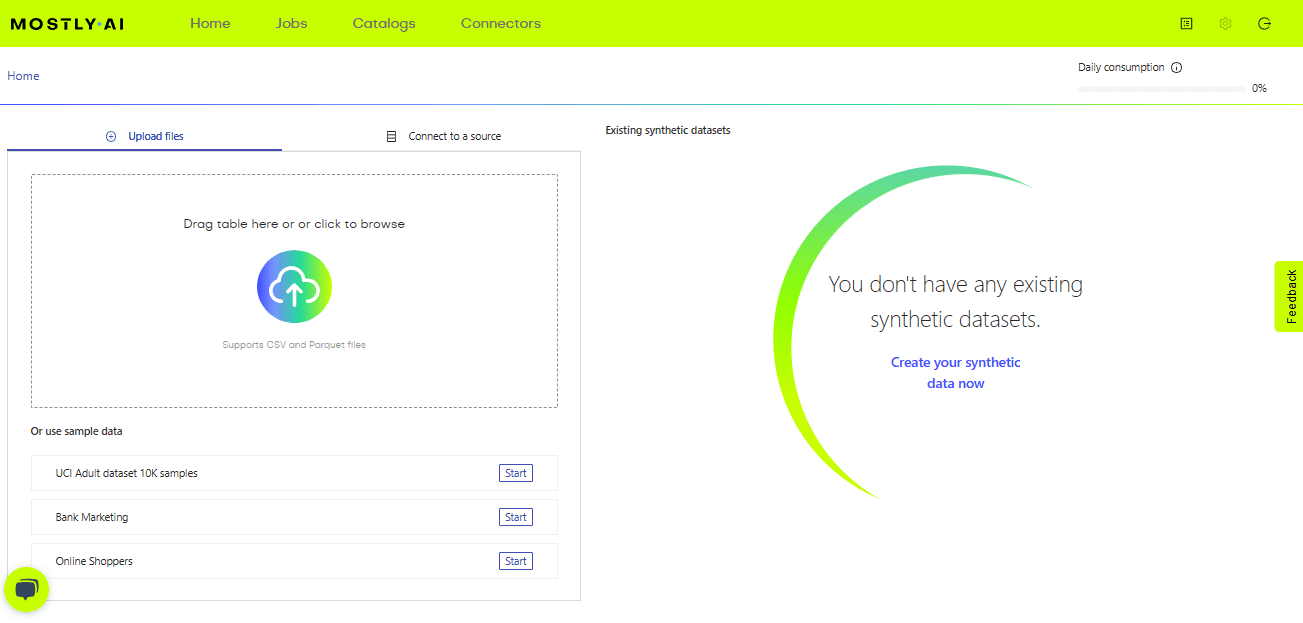
正如您在主页上图中看到的那样,我们可以上传要为其生成合成数据的原始数据集,或者只是为了尝试一下,我们可以使用示例数据。我们可以根据您的要求上传数据。
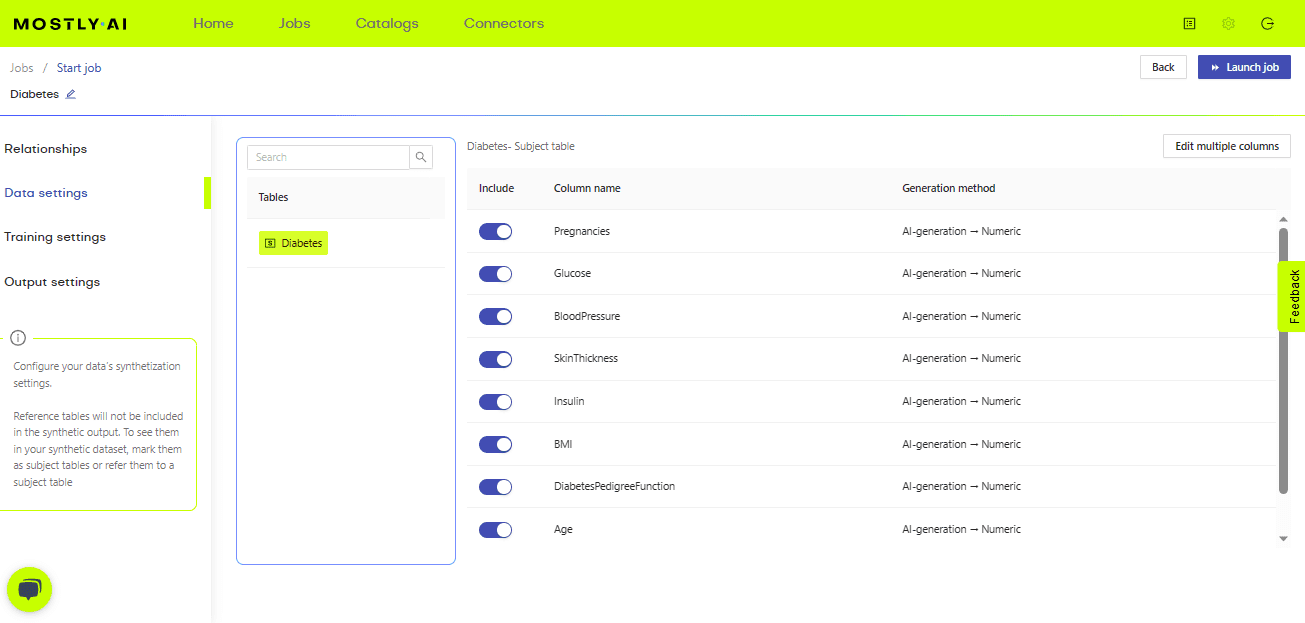
如上图所示,上传数据后,我们可以根据需要生成的列进行更改,还可以设置与数据、训练和输出相关的不同设置。
根据要求设置所有这些属性后,我们需要单击启动作业按钮来生成数据,它将实时生成。在 MOST AI 上,我们每天可以免费生成 100K 行数据。
这就是您可以使用 MOST AI 通过根据需要实时设置数据属性来生成合成数据的方式。根据您尝试解决的问题,可以有多个用例。继续尝试使用数据集,并在响应部分告诉我们您认为该平台的有用性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号