
人工智能的未来:探索下一代生成模型
推荐:使用NSDT场景编辑器助你快速搭建可编辑的3D应用场景
生成式 AI 目前能够做什么,以及探索下一波生成式 AI 模型需要克服的当前挑战?作者 Nisha Arya, KDnuggets on May 22, 2023 in 人工智能脸书唽LinkedIn红迪网电子邮件共享

如果你跟上科技世界的步伐,你就会知道生成式人工智能是最热门的话题。我们听到了很多关于ChatGPT,DALL-E等等的消息。
最近生成式人工智能的突破将极大地改变我们继续处理内容创建的方式以及人工智能工具在所有领域的增长率。Grand View Research在其人工智能市场规模,份额和趋势分析报告中指出:
“136 年全球人工智能市场规模为 55.2022 亿美元,预计从 37 年到 3 年将以 2023.2030% 的复合年增长率增长。”
越来越多的来自不同部门或背景的组织正在寻求通过使用生成式人工智能来提高技能。
什么是生成式 AI?
生成式 AI 是用于创建新的独特内容的算法,例如文本、音频、代码、图像等。随着人工智能的发展,生成式人工智能有可能接管各个行业,帮助他们完成人们认为曾经不可能完成的任务。
生成人工智能已经在创造可以模仿梵高等艺术家的艺术。时尚行业有可能使用生成式人工智能为他们的下一个系列创造新的设计。室内设计师可以使用生成式人工智能在几天内建造他们的梦想家园,而不是几周和几个月。
生成式人工智能是相当新的,是一项正在进行的工作,仍然需要时间来完善自己。但是,像ChatGPT这样的应用程序已经设定了很高的标准,我们应该期待在未来几年看到更多创新的应用程序发布。
生成式 AI 的作用
如前所述,生成式AI目前可以做什么没有具体的限制,它仍在进行中。但是,截至今天,我们可以将其分为 3 个部分:
- 制作新内容/信息:
这可以包括为您的墙创建新博客、视频教程或一些花哨的新艺术。然而,它也可以帮助开发一种新药。
- 替换重复性任务:
生成式人工智能可以接管员工繁琐和重复的任务,例如电子邮件、演示摘要、编码和其他类型的操作。
- 定制数据:
生成式 AI 可以为特定的客户体验创建内容,这可以用作数据来确保成功、投资回报率、营销技术和客户参与度。利用消费者的行为模式,公司将能够区分有效的策略和方法。
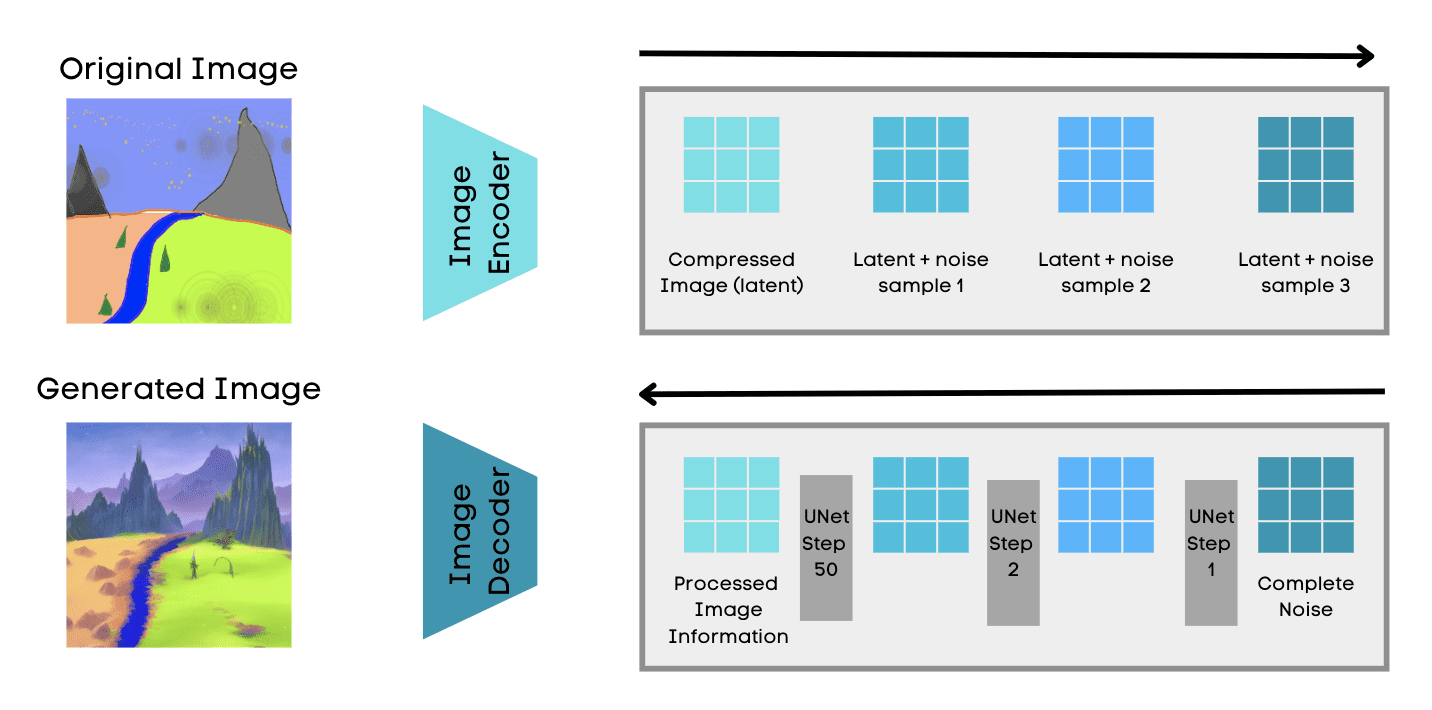
下面是最流行的生成 AI 模型类型之一 - 扩散模型的示例。
扩散模型
扩散模型旨在通过将数据集映射到低维潜在空间来学习数据集的底层结构。潜在扩散模型是一种深度生成神经网络,由慕尼黑LMU和Runway的CompVis小组开发。
扩散过程是当您慢慢地向压缩的潜在表示添加或扩散噪声,并生成一个只是噪声的图像时。然而,扩散模型朝相反的方向发展,并执行相反的扩散过程。噪点以受控方式逐渐从图像中减少,因此图像慢慢看起来与原始图像相似。
生成式 AI 的用例
生成式人工智能已被不同部门的许多组织广泛采用。它使他们能够采用这些工具来帮助微调他们当前的流程和方法,并更有效地提升它们。例如:
媒体
如果是创建新文章、要放在网站上的新图像或很酷的视频。生成式人工智能已经席卷了媒体行业,使他们能够以更快的速度制作高效的内容并降低成本。个性化内容使组织能够将其客户参与度提升到一个新的水平,从而提供更有效的客户保留策略。
金融
AI 工具,例如用于 KYC 和 AML 流程的智能文档处理 (IDP)。然而,生成式人工智能使金融机构能够通过发现消费者支出的新模式和确定潜在问题来进一步进行客户分析。
医疗
生成式 AI 可以帮助处理 X 射线和 CT 扫描等图像,以提供更准确的可视化效果、更好地定义图像并以更快的速度检测诊断。例如,通过GAN(生成对抗网络)使用插图到照片转换等工具,使医疗保健专业人员能够更深入地了解患者当前的医疗状态。
生成式 AI 的治理挑战
有什么好事,都会变坏,对吧?生成式人工智能的兴起导致了政府如何能够控制生成式人工智能工具的使用。
一段时间以来,人工智能领域一直开放给组织做他们想做的事。然而,有人进来并围绕人工智能制定固定的法规只是时间问题。许多人担心对生成式人工智能模型的监督,以及它将如何影响社会经济,以及知识产权和侵犯隐私等其他问题。
生成式人工智能目前在治理方面面临的主要挑战是:
- 数据隐私 - 生成式 AI 模型需要大量数据才能成功导出准确的输出。由于敏感信息可能被滥用,数据隐私是所有人工智能公司和工具都面临的挑战。
- 所有权 - 由生成式人工智能创建的任何内容或信息的知识产权仍然是一个公开的讨论。有些人可能会说内容是独一无二的,而另一些人可能会说文本生成的内容是从各种互联网来源转述的。
- 质量 - 随着大量数据被输入生成式 AI 模型,首要关注点是调查数据的质量,然后调查已生成输出的准确性。医学等领域是高度关注的领域,因为处理错误信息可能会产生很大的影响。
- 偏差 - 当我们研究数据质量时,我们还需要评估训练数据中可能存在的偏差。这可能会导致歧视性输出,导致人工智能在许多人眼中令人反感。
结论
生成式人工智能在被所有人积极接受之前还有很多工作要做。这些人工智能模型需要更好地理解来自不同文化背景的人类语言。对我们来说,与某人交谈时的常识对我们来说是很自然的,但是,对于人工智能系统来说,这并不常见。他们努力适应不同的环境,因为他们被编程为接受事实信息的培训。
看看生成式人工智能在未来将扮演什么角色将是一件有趣的事情。我们必须拭目以待。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号