.Net面试题
.Net面试题
1.简述private、protected、publie、 internal修饰符的访间权限。
答:
private:私有的,只能在类的内部才可以访问。
protected:保护成员,只能在类的内部和被继承的类中可以访问。
publie:公共的,任何人都可以访问,没有访问限制。
internal:在同一命名空间下可以访问。
2.C#中的委托是什么?事件是不是一种委托?
答:
委托可以把一个方法当作参数代入到另一个方法。
委托像C++里面的函数指针,但是相比函数指针它是安全的。
是,事件是一种特殊的委托。(事件不是委托,不过由于事件的性质决定了处理它的程序逻辑能访问的参数,因此,在C#中处理事件的逻辑都包装为 委托。)
5.MVC与WebApi的区别
答:
MVC主要用于建栈。
WebApi主要用于构建Http服务。
6.为什么,.Net Core可以跨频台?
答:
在.NetCore时代,IIS发生了巨大的变化。这个变化就是IIS只利用其中的ASPNetCoreModule模块转发HTTP请求,而所有的请求处理和响应,都是在Kestrel这个内置服务器中完成的。
而Kestrel服务器是跟随我们程序一起打包的。我们的程序,在Linux或mac平台上有专门的运行时,所有我们的程序都能在其他的平台上面运行。
答:
存储过程是一组予编译的SQL语句
它的优点:
1.允许模块化程序设计,就是说只需要创建一次过程,以后在程序中就可以调用该过程任意次。
2.允许更快执行,如果某操作需要执行大量SQL语句或重复执行,存储过程比SQL语句执行的要快。
3.减少网络流量,例如一个需要数百行的SQL代码的操作有一条执行语句完成,不需要在网络中发送数百行代码。
4.更好的安全机制,对于没有权限执行存储过程的用户,也可授权他们执行存储过程。
关于存储过程详情:https://www.cnblogs.com/mvpbest/p/13221507.html
10.JavaScript的模板?
答:
Vue、Angular、Js、React、Jquery。
11.new 关键字用法
答:
(1)new 运算符 用于创建对象和调用构造函数。
(2)new 修饰符 用于向基类成员隐藏继承成员。
答.
1使用QueryString,如.…?id=1;response.Redirect()..…
2.使用Session变量
3.使用Server.Transfer
4.使用Application
5.使用Cache
6使用HttpContext的Item属性
7.使用文件
8.使用数据库
9.使用Cookie
即:DateBase First(数据库优先)、Model First(模型优先)和Code First(代码优先)。
当然,如果把Code First模式的两种具体方式独立出来,那就是四种了。
Code First(New DataBase):在代码中定义类和映射关系并通过mode生成数据库,使用迁移技术更新数据库。
Code First(Existing DataBase):在代码中定义类和映射关系,给逆向工程提供工具。
Model First:在设计器中创建Model,并用Model生成数据库。所有的类由Model自动生成。
DateBase First:在设计器中逆向生成Model,并有Model自动生成所有的类。
15.什么是跨域,怎么解决?
答:
跨域,指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制。
解决办法有1、JSONP:2、代理:3、PHP端修改header(XHR2方式)
关于跨域想深入了解可以:https://blog.csdn.net/lambert310/article/details/51683775
16.MVC有几种缓存?
答:
1、Control缓存
2、Action缓存
3、使用配置文件进行缓存配置
4、缓存依赖
地址:https://www.cnblogs.com/xiaomowang/p/6626712.html
17.MVC的几种传值方式
答:
1.ViewData
2.ViewBag
3.TempData
4.Model
18.面试比较常见的算法
1.冒泡:https://www.cnblogs.com/mvpbest/p/13221570.html
2.递归:https://www.cnblogs.com/mvpbest/p/13816934.html
3.二叉数:https://www.cnblogs.com/mvpbest/p/13272039.html
19.C#.NET里面抽象类和接口有什么区别
相同点:
(1)都可以被继承
(2)都不能被实例化
(3)都可以包含方法声明
(4)派生类必须实现未实现的方法
区别:
(1)抽象基类可以定义字段、属性、方法实现。接口只能定义属性、索引器、事件、和方法声明,不能包含字段。
(2)抽象类是一个不完整的类,需要进一步细化,而接口是一个行为规范。微软的自定义接口总是后带able字段,证明其是表述一类“我能做。。。
(3)接口可以被多重实现,抽象类只能被单一继承
(4)抽象类更多的是定义在一系列紧密相关的类间,而接口大多数是关系疏松但都实现某一功能的类中(5)抽象类是从一系列相关对象中抽象出来的概念,因此反映的是事物的内部共性;接口是为了满足外部调用而定义的一个功能约定,因此反映的是事物的外部特性(6)接口基本上不具备继承的任何具体特点,它仅仅承诺了能够调用的方法
(7)接口可以用于支持回调,而继承并不具备这个特点
(8)抽象类实现的具体方法默认为虚的,但实现接口的类中的接口方法却默认为非虚的,当然您也可以声明为虚的(9)如果抽象类实现接口,则可以把接口中方法映射到抽象类中作为抽象方法而不必实现,而在抽象类的子类中实现接口中方法
20.获取EF生成的SQL语句
string sqlString=(db as System.Data.Objects.ObjectQuery).ToTraceString();//获取sql语句,ds为查询结果
21.NET CORE 存在三大生命周期
AddTransient:瞬时模式:每次请求,都获取一个新的实例。即使同一个请求获取多次也会是不同的实例
例如:Controller添加一个IUser 的依赖,在Action中,IUser的实例是不同的。
使用方式:services.AddTransient<IOperationTransient, Operation>();
AddScoped(作用域):每次请求,都获取一个新的实例。同一个请求获取多次会得到相同的实例
例如:上例中,同一个Action中,实例是相同的。
使用方式:services.AddScoped<IMyDependency, MyDependency>();
AddSingleton:单例模式:每次都获取同一个实例
使用方式:services.AddSingleton<ISchedulerFactory, StdSchedulerFactory>(); //注册ISchedulerFactory的实例
也可以直接注入一个类,例如helper类:services.AddTransient<ExportHelper>();
22.WEBAPI传值方式
get,post,put,delete,
23.SQLservice中的分页
1.第一种:ROW_NUMBER() OVER()方式
把表中的所有数据都按照一个ROW_NUMBER进行排序,然后查询ROW_NUMBER 10 到20之间的前十条记录。
2.第二种方式:OFFSET FETCH NEXT方式(SQL2012以上的版本才支持:推荐使用 )
使用OFFSET是SQLServer2012新具有的分页功能,主要功能是从第x条数据开始共取y数据。但是其必须根再Order By后面使用,相比前三种方式更加方便。
3.-第三种方式:--TOP NOT IN方式 (适应于数据库2012以下的版本)
先搜出id在1-15之间的数据,紧接着搜出id不在1-15之间的数据,最后将搜出的结果取前十条。
4。第四种方式:用存储过程的方式进行分页
23.SQLservice中的去重
1.使用DISTINCT关键字
2.使用ROW_NUMBER() OVER(PARTITION BY 字段1 ORDER BY 字段2 DESC) rows=1方式
3.使用group by方式去重复
4.使用临时表关联查询去重复
24.依赖注入是什么?
依赖注入简称 DI,依赖注入就是将依赖对象通过某种方式(通常是接口)注入到被依赖对象中,由于是通过接口实现这种关系,所以依赖者和被依赖者没有直接关系,实现了解耦合。
常用的依赖注入由两种方式,构造器注入和属性注入 (其本质都是通过在依赖类中实现接口,通过接口将被依赖类注入到依赖类中。)
25.依赖注入和控制反转IOC的区别
控制反转不是一种具体技术,而是一种思想。在传统创建对象的思想中,由程序员直接创建对象。而在控制反转思想中,程序员不直接创建对象,而是描述创建它们的方式,在代码中不直接与对象和服务连接,但在配置文件中描述哪一个组件需要哪一项服务,由容器根据配置文件创建对象。
依赖注入是实现了控制反转思想的一种技术。
26.事件与委托的区别
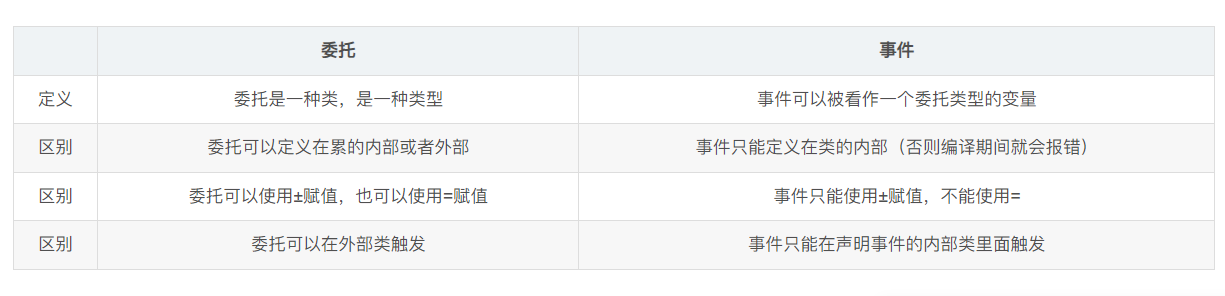
总结来说: 事件比委托更加安全
27.C#常见的设计模式有哪些?
使用c#实现23种常见的设计模式。设计模式通常分为三个主要类别:1、创建型模式 2、结构型模式 3、行为型模式。



设计模式是在软件设计中解决常见问题的一套经过验证的解决方案。它们并不是完成任务的具体代码,而是描述了在特定情况下如何解决问题的策略。设计模式通常被分为三大类:创建型、结构型和行为型。1. 创建型模式:关注的是对象的创建机制,试图创建对象的过程能够满足一定的需求。
• 单例模式(Singleton):确保一个类只有一个实例,并提供一个全局访问点。
• 工厂方法模式(Factory Method):定义一个用于创建对象的接口,让子类决定实例化哪一个类。
• 抽象工厂模式(Abstract Factory):提供一个接口,用于创建相关或依赖对象的家族,而无需指定它们具体的类。
• 建造者模式(Builder):将一个复杂对象的构建与其表示分离,使得同样的构建过程可以创建不同的表示。
• 原型模式(Prototype):通过复制已有实例来创建新对象,而不是通过构造函数创建。
• 结构型模式:关注的是如何组合类或对象构成更大的结构。
• 适配器模式(Adapter):将一个类的接口转换成客户希望的另一个接口。
• 桥接模式(Bridge):将抽象部分与它的实现部分分离,使它们都可以独立变化。
• 组合模式(Composite):将对象组合成树形结构以表示“部分-整体”的层次结构。
• 装饰器模式(Decorator):动态地给一个对象添加一些额外的职责,提供一种替代继承的灵活方案。
• 外观模式(Facade):为子系统中的一组接口提供一个一致的界面,定义了一个高层接口,这个接口使得这一子系统更加容易使用。
• 享元模式(Flyweight):运用共享技术有效地支持大量细粒度的对象。
• 代理模式(Proxy):为其他对象提供一个代理以控制对这个对象的访问。
• 行为型模式:关注的是对象之间的职责分配。
• 策略模式(Strategy):定义一系列算法,把它们一个个封装起来,并且使它们可相互替换。
• 模板方法模式(Template Method):定义一个操作中的算法骨架,而将一些步骤延迟到子类中。
• 观察者模式(Observer):定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
• 命令模式(Command):将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。• 迭代器模式(Iterator):提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示。
• 中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。
• 备忘录模式(Memento):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样以后就可将该对象恢复到原先保存的状态。
• 解释器模式(Interpreter):给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
• 责任链模式(Chain of Responsibility):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。每种模式都有其适用的场景和优势,理解并恰当地应用这些模式可以提高代码的复用性、灵活性和维护性。
28、C#与.Net的区别
一个是一种语言一个是一种开发平台
29、什么是面向对象(OO)
面向对象是种具有对象概念的程序编程的典范,也是一种程序开发的抽象方针。
面向对象(Object-Oriented,简称 OO)是C#的一个核心特性,它基于以下几个基本原则:
1. 封装(Encapsulation):指的是将数据(属性)和操作这些数据的方法(行为)封装在一起,形成一个类(Class)。这样可以隐藏对象的内部实现细节,只通过公共接口与外部交互。
2. 继承(Inheritance):允许创建一个新类(子类)继承另一个类(基类)的特性和行为,子类可以复用基类的代码并扩展新的功能。这有助于减少代码重复,提高代码可维护性。
3. 多态(Polymorphism):指一个接口可以有多种不同的实现方式。在C#中,可以通过方法重写(Override)、抽象类(Abstract Class)和接口(Interface)来实现多态。多态使得代码更加灵活和可扩展。
30.RabbitMQ
是一款非常流行且成熟的开源消息中间件,它基于高级消息队列协议(AMQP)构建,主要用于在分布式系统中实现异步消息传递。
常用于需要解耦、异步处理、流量削峰、分布式事务协调等场景
31、Core 里有哪些缓存
1、MemoryCache:这是.NET Core中最常用的缓存机制之一,它提供了内存中的键值对存储。允许应用程序将数据缓存在本地内存中,从而减少对数据库或其他外部数据源的访问,提高应用的响应速度。
2、Distributed Cache:当应用程序部署在多个实例上时,使用分布式缓存可以保证缓存的一致性和可用性。.NET Core支持几种分布式缓存,包括但不限于Redis、SQL Server和NCache。
3、Output Caching:这种缓存机制主要用于Web应用程序,尤其是那些使用ASP.NET Core MVC或Blazor的项目。输出缓存可以存储页面的渲染结果,这样对于相同的请求,服务器可以直接返回缓存的HTML,而无需重新执行页面渲染逻辑。
4、Response Caching:类似于输出缓存,但更专注于HTTP响应。通过使用属性或中间件,可以控制HTTP响应的缓存行为,包括客户端缓存和服务器端缓存。
5、Entity Framework Core Query Caching:是一个流行的ORM框架,它提供了一种查询缓存机制,可以缓存数据库查询的结果。这有助于减少数据库的读取操作,提高数据密集型应用的性能。
6、API Rate Limiting:虽然严格意义上不是缓存,但在.NET Core中,可以使用诸如“Polly”这样的库来实现API的速率限制。这可以通过缓存请求计数来实现,防止过度使用API资源。
32、消息队列
是一种应用程序间通信(IPC)的方式,它允许进程之间通过消息进行异步通信。在消息队列系统中,发送者(生产者)将消息发送到一个队列,而接收者(消费者)则从这个队列中取出消息进行处理。
它主要应用于解决系统间通信和数据传输的复杂性,尤其在分布式系统中
优点:1. 异步通信;发送者无需等待接收者完成处理就可以继续执行其他任务,这有助于提高系统的响应速度和吞吐量。
2. 解耦;发送者和接收者不需要直接交互,它们只需要知道队列的位置即可,这样即使一方暂时不可用,系统仍然可以正常运行。
3、负载均衡;多个消费者可以从同一个队列中取数据,这有助于分散负载,提高系统的并行处理能力。
4. 可靠性;5. 扩展性;
6. 错误处理:如果某个消费者无法处理消息,该消息可以被重新放入队列,或者转发给另一个消费者处理。
33、C#有哪些过滤器
1. 授权过滤器 (IAuthorizationFilter)• 用于控制对某个动作或资源的访问权限。如果授权失败,过滤器可以阻止进一步的执行,并返回相应的HTTP状态码。
• 资源过滤器 (IResourceFilter)• 在模型绑定之前和之后运行,通常用于缓存或预处理资源相关的逻辑。
• 操作过滤器 (IActionFilter)• 在动作方法执行之前和之后运行。可以用来进行预处理检查或清理工作。
• 结果过滤器 (IResultFilter)• 在动作的结果执行之前和之后运行。可以用来修改或装饰返回的结果。
• 异常过滤器 (IExceptionFilter)• 处理控制器或动作中引发的异常。可以用来记录异常,或者返回一个友好的错误页面或JSON响应。在.NET Core中,过滤器的概念有所扩展,包括但不限于上述类型,还支持更细粒度的控制,例如:• OnActionExecuting 和 OnActionExecuted 方法,用于在动作执行前后。• OnResultExecuting 和 OnResultExecuted 方法,用于在结果执行前后。• OnException 方法,用于处理异常。
此外,还有一些其他类型的过滤器,如:• 模型验证过滤器 (IModelValidator)• 用于验证模型数据。• 日志记录过滤器• 用于记录请求和响应的信息。• 性能监控过滤器• 用于监测请求的执行时间和资源消耗。• 缓存过滤器• 用于缓存响应,减少数据库查询。这些过滤器可以通过实现相应的接口并应用到控制器或动作上来使用。它们增强了应用程序的功能性和可维护性,允许开发者在不修改核心业务逻辑的情况下添加横切关注点。
34、什么是Redis
是一种开源的、高性能的键值存储系统,它提供了数据结构服务器的功能。Redis与其他数据库的区别在于它主要在内存中存储数据,这使得Redis能够提供非常快速的数据访问速度。
它是基于C语言开发的一套内存数据库。是基于单线程模型设计。
使用场景例如:1、临时数据;2、高频热点数据;3、常量数据;4、计数器应用;
35、DDD
领域驱动设计(Domain-Driven Design,简称DDD)软件开发方法,专注于理解和建模复杂的业务领域,以促进更好的软件设计和架构。
• 描述一下战略设计和战术设计的区别。
• 战略设计关注于业务领域的识别和划分,而战术设计则更侧重于具体的模型和设计模式的实现。
• 什么是限界上下文?
• 限界上下文是DDD中一个重要的概念,用于定义和约束业务领域模型的边界,避免模型之间的冲突和混乱。
• 谈谈你对聚合的理解。
• 聚合是DDD中的一个核心概念,指的是业务领域中不可分割的一组对象,它们作为一个整体被一致地操作。
• 如何处理跨限界上下文的通信?
• 这个问题探讨的是当业务逻辑跨越多个限界上下文时,如何协调和同步数据和行为。
• 解释什么是领域事件。
• 领域事件是DDD中的一种机制,用于在不同限界上下文之间传递信息,通常表示领域内的某种变化或重要状态。
• 什么是无处不在的语言?
• 无处不在的语言是指在项目中所有参与者(包括业务专家和技术团队)之间共享的词汇和术语,以确保沟通的一致性和准确性。
• DDD和微服务的关系是什么?
• DDD为微服务的设计提供了指导原则,每个微服务可以被视为一个限界上下文,拥有自己的领域模型和数据。
• 你如何确保DDD模型的正确性?
• 这个问题可能涉及模型验证、测试策略、持续集成和持续交付等方面。
• DDD在大型项目中是如何落地的?
• 实践DDD需要良好的组织结构、沟通机制和持续的重构。团队应该围绕业务领域组织,并保持模型与业务的紧密联系。
36、AOP全称Aspect Oriented Programming,即面向切面编程
现代软件开发中的一种编程范式,主要用于解决横切关注点(cross-cutting concerns)问题。在传统的面向对象编程中,诸如日志记录、权限检查、事务管理等横切关注点常常散布在各个模块中,导致代码的重复和耦合度高。AOP通过提供一种机制,可以在不修改原有业务逻辑代码的情况下,将这些横切关注点集中处理,从而提高代码的可维护性和可读性。
AOP的核心概念包括
1. 切面(Aspect):封装了横切关注点的模块,例如日志记录切面、事务管理切面等。
2. 连接点(Joinpoint):程序执行过程中的某个特定点,例如方法调用、异常抛出等,切面会在这些点上被激活。
3. 通知(Advice):切面在特定连接点上执行的动作,如前置通知、后置通知、环绕通知等。
4. 切入点(Pointcut):定义了哪些连接点将执行通知的规则或表达式。
5. 目标对象(Target Object):被一个或多个切面所通知的对象。
6. 代理(Proxy):AOP框架创建的对象,用来实现切面的织入,可以是JDK动态代理或CGLIB代理。
AOP常用于企业级应用中,如Spring框架就提供了强大的AOP支持,使得开发者可以轻松地添加横切关注点,而无需改变原有的业务逻辑代码结构。
37、EF面试题
EF支持的开发模式有哪些?
1、code first 2、database first 3、model first
解释 EF 中的 Lazy Loading 和 Eager Loading 的区别。
2、Lazy Loading 指的是在访问导航属性时,EF 会延迟加载关联实体。Eager Loading 则是指在查询数据时,通过 Include() 或 ThenInclude() 方法预先加载关联实体。Lazy Loading 可以减少数据量,但可能导致 N+1 查询问题,而 Eager Loading 可以在一次查询中获取所有相关数据,但会增加数据传输量
3、如何在 EF 中执行原生 SQL 查询?
可以使用 FromSqlRaw() 或 FromSqlInterpolated() 方法在 EF 中执行原生 SQL
4、如何处理几十万的并发问题
答:用存储过程或事务。取得最大标识的时候同时更新..注意主键不是自增量方式这种方法并发的时候是不会有重复主键的..取得最大标识
要有一个存储过程来获取.
5、堆和栈的区别?
答: 栈:由编译器自动分配、释放。在函数体中定义的变量通常在栈上。
值类型
堆:一般由程序员分配释放。用new、malloc等分配内存函数分配得到的就是在堆上。引用类型
6.向服务器发送请求有几种方式?
get,post。get一般为链接方式,post一般为按钮方式
7、什么是反射和映射?
反射:动态获取程序集信息;
映射:通常指的是将一个数据结构中的元素与另一个数据结构中的元素关联起来的过程;
当你需要在对象模型(类和对象)和关系型数据库(表格)之间进行数据转换时,对象关系映射(如Entity Framework或SqlSugar)就被广泛使用。ORM允许你用面向对象的方式来处理数据库,无需直接编写SQL语句,从而简化了数据访问和管理。
8.ADO.net中常用的对象有哪些?分别描述一下。
答:Connection 数据库连接对象
Command 数据库命令
DataReader 数据读取器
DataSet 数据集
8、重写与重载
重写:
要求:(三大同)参数相同,方法名相同,返回值相同
关键字:基类函数用virtual修饰,派生类用override修饰
注意:不能重写非虚方法或静态方法
重载:
要求:在同一作用域,可以存在相同的函数名,不同参数列表的函数,这组函数称为重载函数
9、软件开发过程一般有几个阶段?每个阶段的作用?
答:需求分析,架构设计,代码编写,QA(测试),部署
10、EF有哪些状态
1、 Unchanged(未改变/持久态)
2、Modified(已修改)
3、Deleted(已删除)
4、Added(新增)
5. Detached(游离态)
为了效率让他不跟踪可以用.AsNoTracking()方法
38、什么是延迟执行(Deferred Execution)和立即执行(Immediate Execution)?在LINQ中如何区分它们?
延迟执行是指LINQ查询在遍历结果之前不会立即执行,而是在实际需要时才会执行查询。立即执行是指LINQ查询会立即执行,返回实际结果。在LINQ中,使用deferred关键字可以区分两者
39、LINQ的优势
LINQ的优势:讨论使用LINQ的主要优点,如提供比SQL更精确的数据集查询方式,以及与ADO.NET相比提供的额外功能。
两种主要的查询方式,分别是查询表达式语法(Query Expression Syntax)和方法语法(Method Syntax)。
40、多线程与异步面试
1、描述线程与进程的区别?
线程和进程都是操作系统级别的概念,用于管理计算机程序的执行。进程是应用程序的执行实例,它包括程序的代码和数据,以及系统分配给进程的资源(如内存)。线程是进程内的一个执行路径,它是CPU调度的基本单位。进程之间通常不共享代码和数据空间,而同一进程内的不同线程共享代码和数据空间。
2、后台线程和前台线程的区别?
前台线程是应用程序继续运行所必需的。当所有前台线程都完成时,应用程序将正常结束。后台线程则不会阻止应用程序的结束。如果应用程序中没有活动的前台线程,应用程序将终止,无论后台线程是否仍在运行。
3、多线程和异步有什么关系和区别?
多线程和异步编程都是为了提高应用程序的性能和响应能力。多线程涉及同时执行多个任务,而异步编程允许一个任务在等待I/O操作完成时不占用CPU时间。多线程通常涉及操作系统级别的并发执行,而异步编程更多是在单个线程内实现非阻塞操作。
4、说常用的锁,lock是一种什么样的锁?
锁定机制对于管理多线程中一起访问的资源以避免竞争条件和死锁非常重要。可以使用锁定机制如lock、Monitor、Mutex和Semaphore来实现。这些机制用于确保在任何时候只有一个线程可以访问共享资源,从而防止数据不一致
lock关键字在C#中用于实现同步块,确保一个代码块在任何时候只被一个线程执行。这是一种简单的互斥锁,用于防止多个线程同时访问共享资源,从而避免数据竞争和不一致的状态。
5、异步编程?
在.NET中,异步编程通常使用async和await关键字来实现。这些关键字用于I/O绑定操作,如文件访问、数据库查询和网络通信,以防止主线程阻塞。异步编程在Web应用程序开发中特别有用,因为它可以在执行同步I/O操作时保持应用程序的响应性
41、处理高并发
.Core:1、负载均衡 2、使用队列 3、代码优化4、数据库优化5、异常处理6、限流熔断7、监控与日志
sqlsugar:1、乐观锁2、分布式锁3、读写分离4、限流排队5、事务隔离级别6、索引优化
42、值类型和引用类型的区别
值类型(Value types):
-
直接存储数据。
-
存储在堆栈(Stack)上,分配速度快。
-
常见的值类型包括基本数据类型(int, float, double等),枚举(enum),结构(struct)。
引用类型(Reference types):
-
存储数据的引用(内存地址),而实际数据存储在托管堆(Managed Heap)中。
-
存储在托管堆上,分配速度较慢。
-
常见的引用类型包括类(class),接口(interface),数组(array),委托(delegate)。
值类型和引用类型的主要区别在于它们在内存中的存储方式不同:值类型的值直接存储在栈上,而引用类型的值存储在堆上,并在栈上保留一个引用。
43、异步返回什么类型
异步方法通常会返回Task(无返回值的情况)或Task<T>(有返回值的情况)。其中Task<T>是Task的子类。
44、JWT的三个组成部分
为头部(Header)、载荷(Payload)和签名(Signature)。
-
头部(Header):这部分通常包含两部分信息,即令牌的类型(JWT)和使用的签名算法。例如,一个简单的头部可以是:
{ "alg": "HS256", "typ": "JWT" }。这表示使用HS256算法进行签名,并且类型是JWT。 -
载荷(Payload):这部分包含了实际的声明信息,这些信息可以是公开的(public claims)或私有的(private claims)。公开声明是标准的,而私有声明则是根据JWT的生产者和消费者之间的协议定义的。例如,
{ "sub": "1234567890", "name": "John Doe", "admin": true }。这些信息在JWT中扮演着传递用户信息或数据的关键角色。 -
签名(Signature):签名部分用于验证消息在发送过程中没有被更改。它通过获取编码的头部、编码的载荷、秘钥以及头部中指定的算法进行创建。签名的存在确保了JWT的完整性和发送者的身份验证。
45、在.NET Core框架中,中间件(Middleware)
是指一系列可以处理HTTP请求和响应的软件组件,它们构成了请求处理管道的一部分。当一个HTTP请求到达.NET Core应用时,它会依次通过一系列预定义的中间件,每个中间件都有机会处理请求或响应,然后将控制权传递给下一个中间件,或者直接终止请求的处理。
1. 处理管道:中间件被安排在一个处理管道中,请求按照管道中中间件的顺序依次被处理。
2. 装饰器模式:中间件通常遵循装饰器设计模式,这意味着每个中间件都可以包装下一个中间件,以便在请求/响应流中添加、修改或拦截行为。
3. 横切关注点:中间件是用来处理横切关注点的理想场所,比如日志记录、性能监控、错误处理、身份验证、授权、压缩、静态文件服务等。
4. 动态配置:中间件可以在应用启动时通过
5. 可插拔性:中间件是可插拔的,你可以轻松地添加、移除或更改中间件的顺序,以适应应用的需求。
6. 内置与自定义:.NET Core提供了许多内置的中间件,如身份验证、错误处理、静态文件服务等,同时也支持开发自定义中间件来满足特定需求。
总之,中间件是.NET Core应用架构中一个非常灵活且强大的部分,它允许开发者以模块化的方式添加功能,而不必改变核心的应用逻辑。
46、ClickHouse 列式存储数据库(DBMS)
由C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报表。
47、多线程、单线程
多线程不支持高并发(MySQL·、tomcat),单线程支持高并发(redis、nginx)
mysql操作磁盘的redis是操作内存
多线程运用场景:文件处理、网络请求、用户界面交互、用于耗时长的场景。
48、Nginx
nginx类似与中介或代理;主要职责是处理网络请求和响应而不是做复杂的逻辑处理。
项目网关:简单理解就过滤客户端请求;意义:为了保护系统。
反向代理:使用nginx代理服务端。
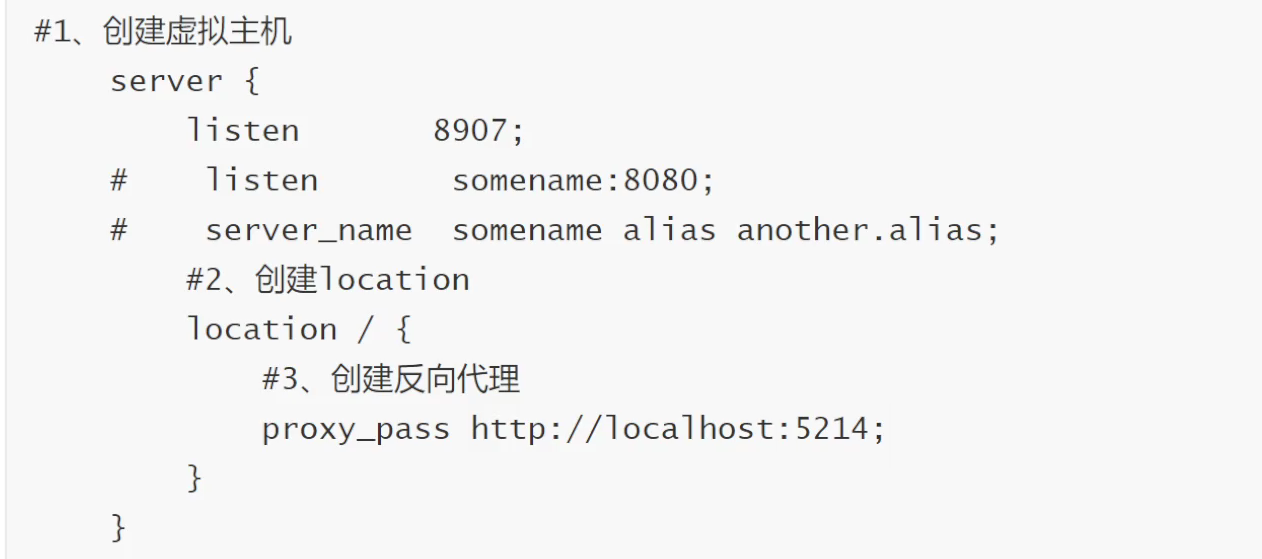
nginx负载均衡含义:客户端请求均分到后端多个实例上。意义:实现系统高并发。

nginx限流:含义:客户端的请求限制进入服务器。
意义:保住系统稳定。1、在server同目录下;2、在server 的location里


49、进程与线程
进程是计算机中运行的一个应用程序,线程是进程的最小单元,一个线程可能是由一个线程或者多个线程组成
50、代理(Proxy)
是一种中介服务,它代表客户端去获取网络信息或服务。代理服务器接收客户端的请求,再转发给目标服务器,然后将从目标服务器得到的响应返回给客户端。代理服务可以用于多种目的,包括但不限于安全性、隐私保护、性能优化、内容过滤等。正向代理(Forward Proxy)和反向代理(Reverse Proxy)是两种主要的代理类型,它们的主要区别在于代理的方向和客户端是否需要知道代理的存在:
1. 正向代理:• 定义: 正向代理位于客户端和真实服务器之间,客户端通过正向代理访问服务器。
• 用途: 它通常用于帮助客户端突破网络限制,比如访问互联网时的防火墙,或者用于缓存和加速内容的传输。
• 设置: 使用正向代理时,客户端需要配置代理服务器的地址和端口。
• 例子: 企业内部员工通过公司的正向代理服务器访问外部网站。
• 反向代理:• 定义: 反向代理位于客户端和真实服务器之间,但对客户端来说,它看起来就像是真实服务器。
• 用途: 主要用于负载均衡、安全性和性能优化,比如通过缓存来减少对后端服务器的直接请求。
• 设置: 使用反向代理时,客户端无需做任何特殊配置,因为它看起来就像是直接连接到真实服务器。
• 例子: CDN(Content Delivery Network)网络使用反向代理来缓存和分发静态内容,提高访问速度。总结来说,正向代理更多地关注客户端的需求和网络访问策略,而反向代理则侧重于服务器端的管理和优化。
51、自定义中间件
自定义中间件是软件开发中的一种机制,尤其是在Web开发框架中,如Django、Flask、Express等,用于在请求处理的各个阶段插入自定义的行为。它允许开发者在请求到达目标处理函数之前或响应发送给客户端之后执行一些操作。自定义中间件可以用于多种用途,包括但不限于:
52、有哪些索引
1. 普通索引:这是最基本的索引类型,它可以帮助加速数据检索,但没有其他限制,例如唯一性或非空性。
2. 唯一索引:这种索引保证了索引列的值是唯一的,但允许有空值的存在。
3. 主键索引:这是一种特殊的唯一索引,通常作为表的主键,确保每一行数据的唯一性,并且不允许有空值。
4. 组合索引(复合索引):在一个表的多个列上创建的索引,可以同时加速涉及这些列的查询。这种索引遵循最左前缀原则,即查询中必须包括索引中最左边的列才能使用该索引。
5. 全文索引:专门用于搜索文本中的关键词,适用于大型文本字段的搜索。
6. 位图索引:在数据集较小且列值较少的情况下使用,用位图表示索引,非常节省空间,但在更新频繁的场景下效率不高。7. 哈希索引:基于哈希算法,用于等值查询,对于简单的等式查询非常高效,但不支持范围查询。
8. 空间索引(R-tree索引):用于处理地理空间数据,如地图应用中的坐标点。
9. 函数索引:基于表达式或函数的结果创建的索引,而非直接基于列值。
10. 覆盖索引:包含了查询语句中所有需要的列的索引,这意味着数据库不需要回表查找,直接从索引中获取数据,提高了查询性能。
11. 聚簇索引:数据行的物理顺序与键值的逻辑(索引)顺序相同,InnoDB引擎的主键索引就是聚簇索引的一个例子。每种索引类型都有其适用的场景和局限性,在选择索引类型时,应考虑数据的特性、查询模式以及系统的整体性能需求。
52、数据库优化
优先级:架构优化>硬件优化>DB优化>SQL优化

53、ASP.Net Core 几个重要的中间件
1、重定向中间件:app.UseHtppsRedirection(); 将所有http请求重新定向到https请求。
2、静态文件中间件:app.UseStartFiles();对于静态资源放在wwroot下,想要正常访问必须要启用静态文件中间件。
3、跨域中间件:
4、自定义中间件:三种方式
1、匿名方式


2、基于IMiddleware接口实现


3、基于约定方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号