

220127_202201_机器学习中一些 模型评价指标简介
220127_202201_机器学习中一些模型评价指标简介
不同任务下衡量模型性能有不同指标。
回归任务
平均绝对误差(Mean Absolute Deviation)
均方误差(Mean Square Error)
均方根误差(Root Mean Squared Error)
分类任务
-
准确率(Accuracy)与错误率(Error Rate)
Accuracy = 判断正确的样本数/总样本数
Error = 1 - Accuracy
| p=1 | p =0 | |
|---|---|---|
| y=1 | True Positive(真判真) | False Negative(真判假) |
| y=0 | False Positive(假判真) | True Negative(假判假) |
以上这张表中数据,可以构成 混淆矩阵(Confusion Matrix)
查准率 / 精度(Precision)
召回率(Recall)
F_β与F_1
其中β参数控制F指标中对P与R的侧重:β越大,越侧重P;β越小,越侧重R。
ROC曲线与AUC曲线
定义 真正例率(true positive ratio) 与 假正利率(true positive ratio) 如下:
在二分类时,需要阈值(threshold)来划分正负。大于或等于阈值记正例,否则记负例。
容易知道,不同的threshold,将会产生不同的混淆矩阵,对应不同的FPR、TPR。
取不同threshold,FPR为横轴, TPR(即召回率)为纵轴,可以绘制出ROC曲线(Receiver Operating Characteristic Curve)。
最理想的情况是,TPR=1,FPR=0,即(0,0)-(0,1)-(1,1)的折线;
当threshold极低,所有样本都被预测为正例,TPR=1,FPR=1,对应(1,1);
当threshold极高,所有样本都被预测为负例,TPR=0,FPR=0,对应(0,0);
一般来说,当分类模型适当,threshold∈(0,1),TPR大于FPR。
当没有预测模型而采用完全随机猜测时,ROC曲线表现为对角直线(即图a的虚线)。
实际工作中,样本数是有限的,所以绘制出来的ROC曲线,往往呈现为阶梯状。
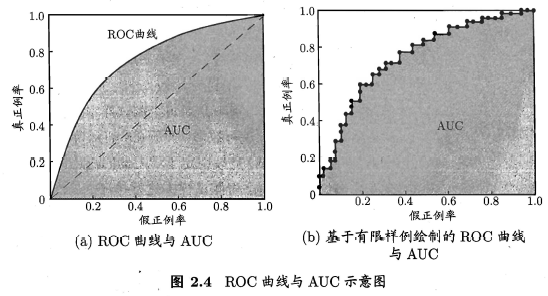
AUC(Area Under ROC Curve)指的是ROC曲线下的面积,认为AUC越大越好。
ROC绘制举例:
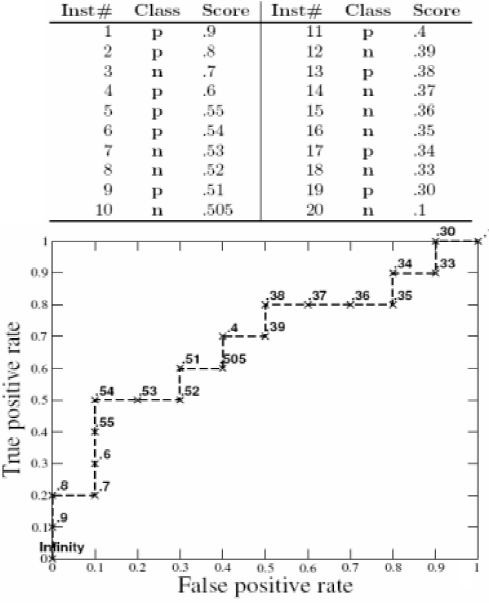
AUC计算的简便方法:
将测试样例以预测值从大到小排序,其中有n1个真实正例,n0个真实负例。
设 ri 为第i个真实负例的秩,即第 i 个真实负例在排序中排第ri个,令 S0 = Σ ri。
那么AUC可以用下式计算:
个性化推荐
-
前K项精度(Precision@K)
前K个推荐中,正例(用户喜欢的项目)所占的比例。
-
前K项召回率(Recall@K)
前K个推荐中,正例占候选集中鄋正例的比例。
-
前K项命中率(Hit@K)
前K个推荐中,是否有正例。
DCG(Discounted cumulative gain)
是一个衡量搜索引擎算法的指标。
表示一个样本的相关性,依次来衡量这个样本的有用性,也叫做增益(gain):
假设我们在Google上搜索一个词,然后得到5个结果。我们对这些结果进行3个等级的区分:Good(好)、Fair(一般)、Bad(差),然后赋予他们分值分别为3、2、1,假定通过逐条打分后,可以得到这5个结果的分值分别为3、2 、1 、3、 2。
随着排序位次增加,即排序越靠后,这种增益减弱: ,其中discounted(x)被称为折损函数。
经典的折损函数可以取对数的倒数 。
因此在计算前P位的DCG有:
或
归一化DCG (Normalized DCG)
理想情况下,越大的样本应该越靠前,此时的DCG最大。
计算NDCG的过程,就是将推荐结果的DCG除以理想情况下的DCG,实现归一化。
对话系统
BLEU(bilingual evaluation understudy)
常用在机器翻译,后来也被运用在其他任务,比如对话生成等等。
这个公式是怎么来的?
举例:

(1)
希望模型译文与参考译文一致。
1-gram : 将参考译文与模型译文 按照 每段1个词 分成片段。
模型译文中的第一个片段you,在参考译文的片段中出现;模型译文中的第二个片段you,
在参考译文的片段中出现。P=(1+1)/2=1.0 。
这显然是荒谬的。所以进行修正,强调模型译文中每个片段的出现次数应当和参考译文中的片段出现次数对应。
修正之后,记作 。
2-gram:将参考译文与模型译文 按照 每段2个词 分成片段。
修正前,P=1/0=0 ;修正后,记作。
(2)
认为参考译文更长时更可靠。
所以,当模型译文短于参考译文时,记:
当模型译文长于参考译文时,BP=1。
所以,本例当中,。
出现ln0:
-
BLEU直接置零。
-
对精度做平滑,修改BLEU规则:计算P时,分子分母同时+1。
Bleu的评价方式没有考虑语法等其他语言学因素,比较简单粗暴。

posted on 2022-01-27 21:52 木子但丁MuzziDante 阅读(311) 评论(0) 编辑 收藏 举报

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧