

编码与解码
2017-12-05 10:57 菜鸟飞呀飞 阅读(1423) 评论(1) 编辑 收藏 举报1. 编码
什么是编码?
计算机中存储的都是二进制,但是要显示的时候,就是我们看到的却可以有中国 ,a 1 等字符
计算机中是没有存储字符的,但是我们却看到了。计算机在存储这些信息的时候,根据一个有规则的编号,当用户输入a 有a对映的编号,就将这个编号存进计算机中这就是编码。
计算机只能识别二进制数据。
为了方便应用计算机,让它可以识别各个国家的文字。就将各个国家的文字用数字来表示,并一一对应,形成一张表,这就是编码表。
例如:汉字 中
有一种编码:
中字在utf 8中对映的编码
utf-8 -->100
在gbk中呢?有可能就不是100了
gbk --> 150
很显然同一个信息在不同的编码中对映的数字也不同,
不同的国家和地区使用的码表是不同的,
gbk 是中国大陆
bjg5 是台湾同胞中的繁体字。所以如果给big5一个简体字是不认识的。
还有ASCII 美国标准信息交换码
1.1. 码表
常见的码表如下:
ASCII: 美国标准信息交换码。用一个字节的7位可以表示。 -128~127 256
ISO8859-1: 拉丁码表。欧洲码表,用一个字节的8位表示。又称Latin-1(拉丁编码)或“西欧语言”。ASCII码是包含的仅仅是英文字母,并且没有完全占满256个编码位置,所以它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入192个字母及符号,
藉以供使用变音符号的拉丁字母语言使用。从而支持德文,法文等。因而它依然是一个单字节编码,只是比ASCII更全面。
GB2312: 英文占一个字节, 中文占两个字节。中国的中文编码表。
GBK: 中国的中文编码表升级,融合了更多的中文文字符号。
Unicode: 国际标准码,融合了多种文字。所有文字都用两个字节来表示,Java语言使用的就是unicode。
UTF-8: 英文占一个字节,中文占三个字节。 最多用三个字节来表示一个字符。
(我们以后接触最多的是iso8859-1、gbk、utf-8)
UTF-16: 不管英文中文都是占两个字节。
1.2. 编码:
字符串---》字节数组
String类的getBytes() 方法进行编码,将字符串,转为对映的二进制,并且这个方法可以指定编码表。如果没有指定码表,该方法会使用操作系统默认码表。
注意:中国大陆的Windows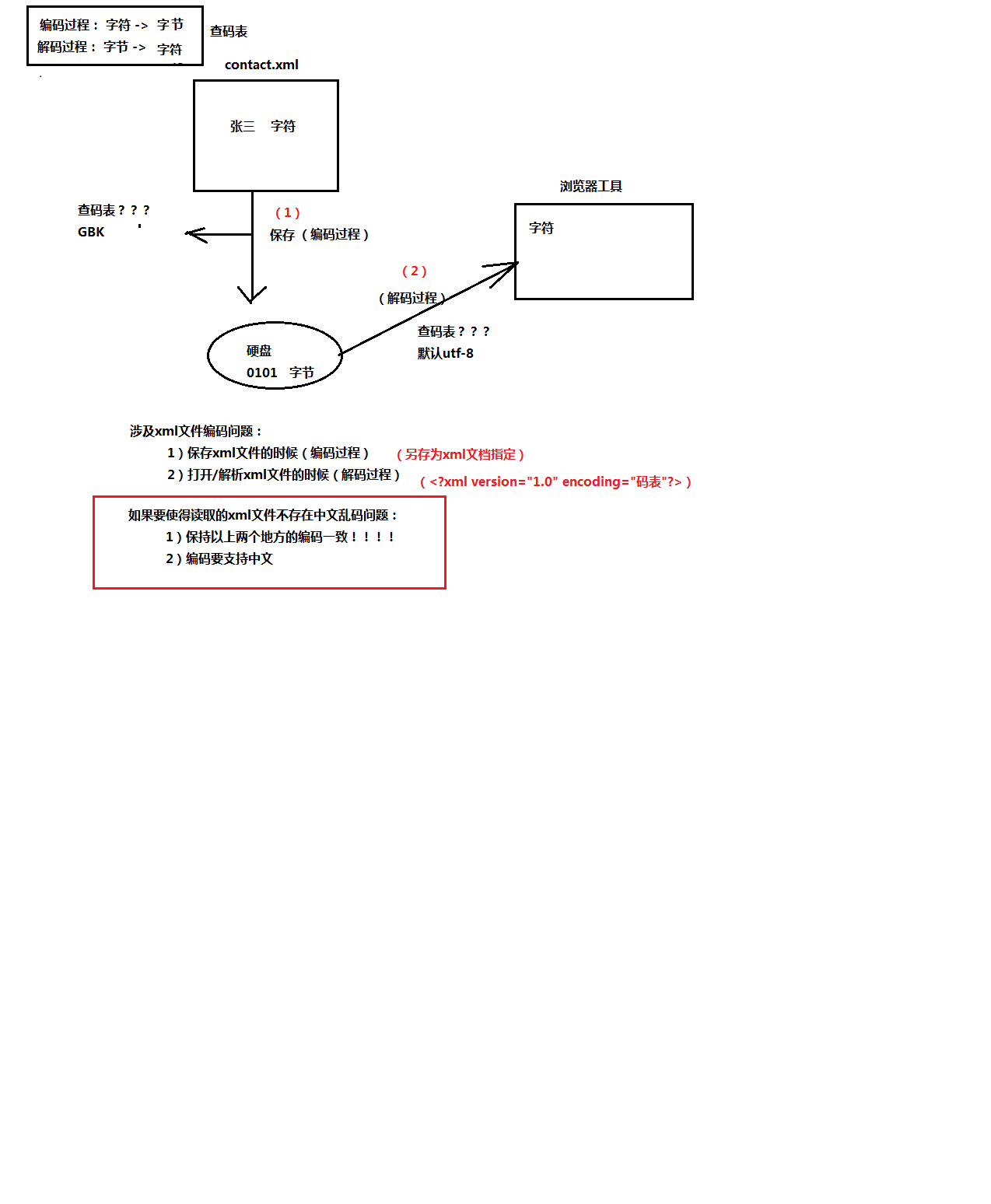 系统上默认的编码一般为GBK。在Java程序中可以使用System.getProperty("file.encoding")方式得到当前的默认编码。
系统上默认的编码一般为GBK。在Java程序中可以使用System.getProperty("file.encoding")方式得到当前的默认编码。
1.3. 解码:
字节数组---》字符串
String类的构造函数完成。
String(byte[] bytes) 使用系统默认码表
String(byte[],charset)指定码表
注意:我们使用什么字符集(码表)进行编码,就应该使用什么字符集进行解码,否则很有可能出现乱码(兼容字符集不会)。
