

sql优化案例(索引创建不合理)
SQL Monitoring Report
SQL Text
------------------------------
INSERT INTO FS_PAY_DET_INFO
(PAY_DET_ID,
PAY_INFO_ID,
GC_TYPE_CODE,
GRA_PQ,
PAY_GRA_AMT,
PUR_PQ,
PAY_PUR_AMT)
SELECT PKG_SP_SEQ.F_A_RCVBL_PL_FLOW_RCVBLID,
A.PAY_INFO_ID,
C.GC_TYPE_CODE,
SUM(DECODE(G.DISC_MODE, '13102', B.T_SETTLE_PQ, 0)) GRA_PQ,
SUM(A.PAY_GRA_AMT) PAY_GRA_AMT,
SUM(DECODE(G.DISC_MODE, '13103', B.T_SETTLE_PQ, 0)) PUR_PQ,
SUM(A.PAY_PUR_AMT) PAY_PUR_AMT
FROM FS_PAY_INFO A, E_CONS_PRC_AMT B, E_GP_SNAP C, E_CAT_PRC G
WHERE A.CALC_ID = B.CALC_ID
AND A.CALC_ID = C.CALC_ID
AND A.PAY_YM = B.YM
AND A.ORG_NO = B.ORG_NO
AND B.PARA_VN = G.PARA_VN
AND B.PRC_CODE = G.PRC_CODE
AND B.ORG_NO = :B3
AND B.YM = :B2
AND B.APP_CODE = :B1
GROUP BY A.PAY_INFO_ID, C.GC_TYPE_CODE;
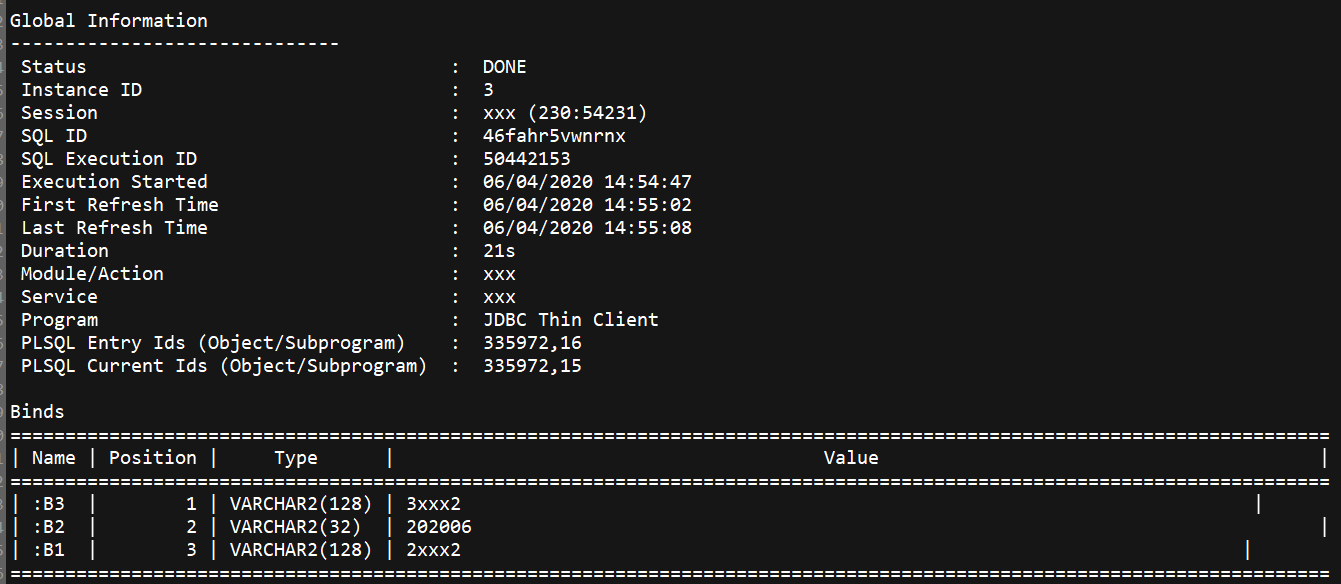

执行计划观察到:

该步骤消耗大量资源且时间长。
分析FS_PAY_INFO表:
select num_rows,LAST_ANALYZED from dba_tables where table_name='FS_PAY_INFO';
NUM_ROWS LAST_ANALYZED
6541065 2020/4/15 0:05:30
select column_name,num_distinct from dba_tab_col_statistics where table_name='FS_PAY_INFO';
COLUMN_NAME NUM_DISTINCT
CALC_ID 6541065
PAY_YM 70
CALC_ID选择性比PAY_YM高出很多。
添加索引:
create index xx.IDX_FS_PAY_CALC_ID on xx.FS_PAY_INFO (CALC_ID) parallel 4 online tablespace xx;
alter index xx.IDX_FS_PAY_CALC_ID noparallel;
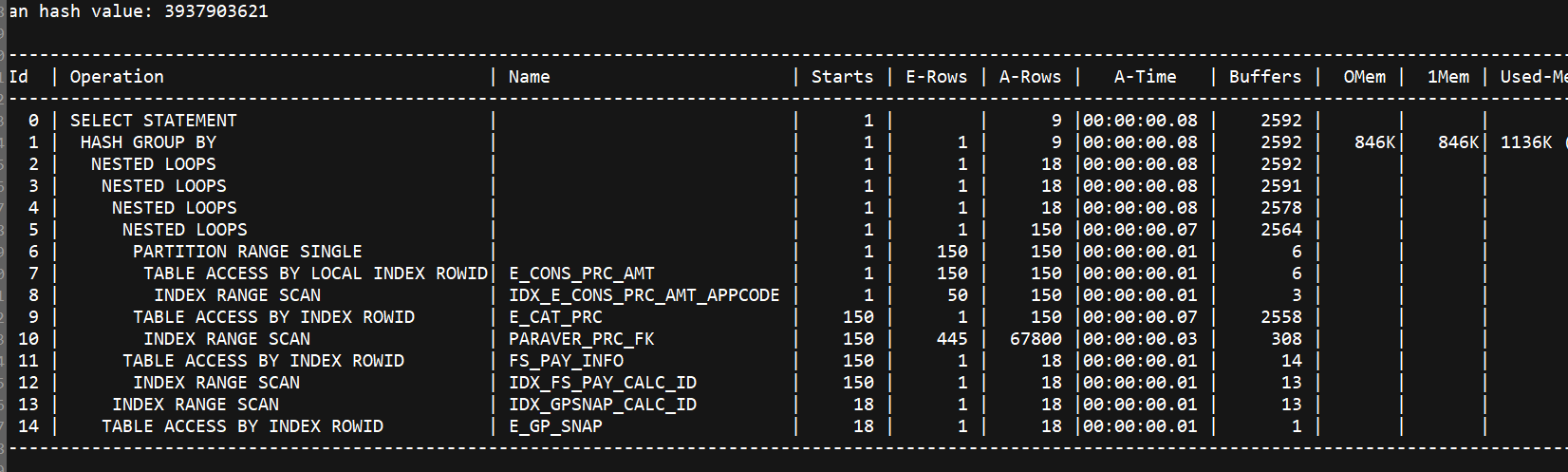
添加索引后,执行计划如下:
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
Predicate Information (identified by operation id):
---------------------------------------------------
7 - filter(("B"."YM"='202006' AND "B"."ORG_NO"='3xxx2'))
8 - access("B"."APP_CODE"='2xxx2')
9 - filter("B"."PRC_CODE"="G"."PRC_CODE")
10 - access("B"."PARA_VN"="G"."PARA_VN")
11 - filter(("A"."PAY_YM"='202006' AND "A"."ORG_NO"='3xxx2'))
12 - access("A"."CALC_ID"="B"."CALC_ID")
13 - access("A"."CALC_ID"="C"."CALC_ID")
添加索引后速度为毫秒。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY