
大模型训练记录
思路
对于模型的每10亿个参数,需要6GB的内存(使用16位半精度)来加载和训练模型。请记住,内存大小只是训练故事的一部分。完成预训练所需的时间也是另一个重要部分。举个例子,最小的 Llama2 模型(Llama2 7B)具有70亿个参数,它花费了184320 GPU 小时才完成训练。
- 首先要弄清楚的是,消耗显存的都有哪些?
- 模型的参数 $P_p$。
- 前向过程中,一些中间计算结果以及激活值(即激活函数的执行结果)。
- 后向过程中,每个参数的梯度值 $P_g$。
- 优化器的状态$P_{os}$(Optimizer state)。比如 adam 算法,需要为每个参数再保存一个一阶动量和二阶动量。
- 接下来,思考如何解决内存不足的问题。核心思路其实很简单,主要有两个方向:
- 先不把全部数据加载到 GPU 显存,暂时存放在别的地方,需要的时候再同步到 GPU 显存中,用完就扔掉。把参数放到 CPU 内存中或者高速SSD中(支持NVMe的ssd,走的PCI-E总线),这就是 deepspeed 中的 offload 技术;多张GPU卡,每张卡保存一部分,需要的时候再从其他卡同步过来,这就是参数分割。
- 降低内存的需求。原来每个参数都是 float32 类型,占用4个字节。改成半精度,用2个字节的 float16 替代4个字节 float32,显存需求一下就降低一半。用量化技术,用2个字节的 int16 或者1个字节的 int8 代替4字节的 float32 。
显然,每种方法都不是完美的,都有一定的局限性并且会引入新的问题,比如:
- 参数进行多卡分割或者 offload,比如会增加大量数据同步通信时间,不要小看这部分时间消耗,相对于 GPU 的显存访问速度而言, 多机器之间的网络通信、单机多卡之间通信、cpu内存到GPU内存的通信,这些都是巨大的延迟。
- 模型运行中,大量的浮点数乘法,产生很多很小的浮点数,降低参数精度,会造成数据溢出,导致出问题,即使不溢出,也损失了数据准确性。 模型训练时,梯度误差大,导致损失不收敛。模型推理时,误差变大,推理效果变差。
参数分割策略:说到分割参数,无论是多GPU之间分割参数(比如ZeRO),还是 offload 到CPU内存(比如ZeRO-Offload),都需要对参数进行分割分组。 这就涉及到多种划分策略。
- 按照模型的层(Layer)进行分割,保留每一层(Layer)为整体,不同层存储在不同的 GPU 中, 多个层(GPU)串行在一起,需要串行执行,这就是所谓的 流水线并行(Pipeline Parallel,PP)。时间效率很差, 并且如果某一层的参数量就很大并超过了单卡的显存就尴尬。当然可以通过异步执行一定程度解决时间效率差的问题,有兴趣的读者可以研读相关资料。
- 把参数张量切开,切开张量分开存储很容易,但切开之后,张量计算的时候怎么办?这里可以分两种策略。
- 张量的计算过程也是可以切割,这样把一个大的张量,切分成多个小张量,每张 GPU 卡只保存一个小片段,每个小张量片段(GPU卡)独立进行相关计算,最后在需要的时候合并结果就行了。这种思路就称为 张量并行(Tensor Parallel,TP) , Megatron 就是走的这个路线。
- 同样是把参数张量分割,每张卡只保存一个片段。但是需要计算的时候,每张卡都从其他卡同步其它片段过来,恢复完整的参数张量,再继续数据计算。Deepspeed 选取的这个策略,这个策略实现起来更简单一些。 PS:ZeRO是一种显存优化的数据并行(data parallelism, DP)方案,它可以显著降低模型训练所需的内存。ZeRO通过在多个GPU之间分散模型参数、优化器状态和梯度,从而降低了单个GPU上的内存需求。此外,ZeRO还通过高效的通信算法最小化了跨GPU的数据传输。
降低精度:降低参数精度也有讲究,有些地方可以降低,有些地方就不能降低,所以一般是混合精度。 半精度还有另一个好处,就是 计算效率更高,两个字节的计算速度自然是高于4个字节的。 在模型训练过程中,参数的梯度是非常重要的,参数更新累积梯度变化时,如果精度损失太多会导致模型不收敛。 所以优化器的状态一般需要保留 float32 类型。实际上,GPU 显存不足的问题更多的是靠上面的参数分割来解决,半精度的应用更多的是为了提高计算速度。
流水线并行、张量并行,把模型一次完整的计算过程(前后向)分拆到多个 GPU 上进行, 所以这两者都被称为模型并行(Model Parallel,MP)。 而如果每张卡都能进行模型一次完整前后向计算,只是每张卡处理不同的训练数据批次(batch), 就称为数据并行(Data Parallel,DP)。 deepspeed 对参数进行了分割,每张卡存储一个片段,但在进行运算时, 每张卡都会恢复完整的参数张量,每张卡处理不同的数据批次, 因此 deepspeed 属于数据并行。
最后总结一下, 针对大模型的训练有三种并行策略,理解起来并不复杂:
- 数据并行:模型的计算过程没有分割,训练数据是分割并行处理的。
- 模型并行:模型的计算过程被分割。
- 流水线并行:模型按照层(Layer)切分。
- 张量并行:把参数张量切分,并且将矩阵乘法分解后多 GPU 并行计算。
训练框架
虽然支持大模型训练的分布式框架仍有不少,但是社区主流的方案主要还是
- DeepSpeed,这是一个用于加速深度学习模型训练的开源库,由微软开发。它提供了一种高效的训练框架,支持分布式训练、模型并行和数据并行。DeepSpeed 还包括内存优化技术,如梯度累积和激活检查点,以降低内存需求。DeepSpeed 可以与流行的深度学习框架(如 PyTorch)无缝集成
- Megatron,Megatron 是 NVIDIA 开发的一个用于训练大规模 transformer 模型的项目。它基于 PyTorch 框架,实现了高效的并行策略,包括模型并行、数据并行和管道并行。Megatron 还采用了混合精度训练,以减少内存消耗并提高计算性能。
- Megatron-LM:Megatron-LM 是在 Megatron 的基础上,结合了 DeepSpeed 技术的NVIDIA做的项目。它旨在进一步提高训练大规模 transformer 模型的性能。Megatron-LM 项目包括对多种 transformer 模型(如 BERT、GPT-2 和 T5)的支持,以及一些预训练模型和脚本, 主导Pytorch。
- Megatron-DeepSpeed : 采用了一种名为 ZeRO (Zero Redundancy Optimizer) 的内存优化技术,以降低内存占用并提高扩展性,提供了一些其他优化功能,如梯度累积、激活检查点等。Megatron-DeepSpeed 支持多个深度学习框架,包括 PyTorch、TensorFlow 和 Horovod。这使得 Megatron-DeepSpeed 对于使用不同框架的用户具有更广泛的适用性。
目前被采纳训练千亿模型最多的还是3和4, Megatron-LM(大语言模型训练过程中对显存的占用,主要来自于 optimizer states, gradients, model parameters, 和 activation 几个部分。DeepSpeed 的 ZeRO 系列主要是对 Optimizer, Gradients 和 Model 的 State 在数据并行维度做切分。优点是对模型改动小,缺点是没有对 Activation 进行切分。Megatron-LM 拥有比较完备的 Tensor 并行和 Pipeline 并行的实现。)。那么为什么大模型训练偏爱 3D 并行呢,比如Megatron-Turing NLG(530B), Bloom(176B)?相信对大模型训练感兴趣的同学,都会熟悉和了解一些使用分布式训练的具体策略和 tricks。我们不如来算一笔账,看看这些 tricks 是为什么。
- ZeRO-Offload 和 ZeRO-3 增加了带宽的压力,变得不可取
- 使用 3D 并行来降低每卡显存占用,避免 recomputation
- GA>1,主要是为了 overlap 和减少 bubble
- Flash Attention2 (显存的节省上面等效于 Selective Activation Recompute)
- ZeRO1 Data Parallel + Tensor Parallel(Sequence Parallel) + Interleave Pipeline Parallel
- 为什么不用 ZeRO2,因为在 GA 的基础上面 Gradient 切分反而多了通信次数
- FP16/BF16/FP8 训练,通信压缩
- Overlapped distributed optimizer
DeepSpeed
DeepSpeed 实现的 ZeRO ,出发点是为了减少显存使用,跨机器跨节点进行更大模型的训练。按层切分模型分别载入参数,看起来好像是模型并行。但是运行时其实质则是数据并行方式,不同的数据会在不同的卡运行,且同一组数据一般会在一块卡上完成全部前向和后向过程。而被切分的参数和梯度等数据会通过互联结构在运行态共享到不同节点,只是复制出的数据用后即焚删除了,不再占用空间。
整体设计
普通数据并行时GPU 内存的占用情况
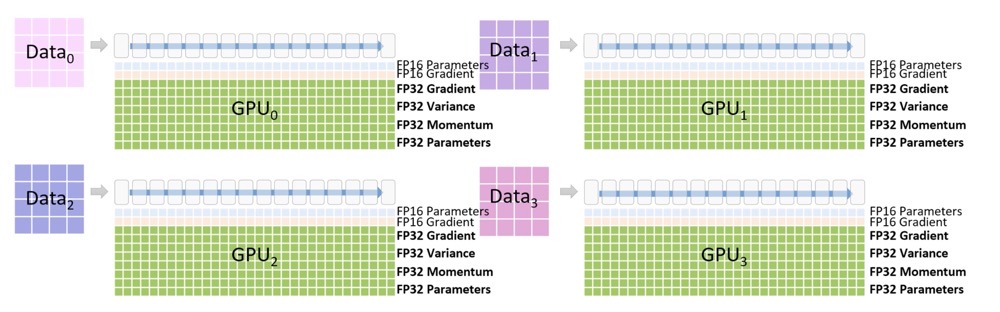
在DeepSpeed下,ZeRO训练支持了完整的ZeRO Stages1, 2和3,以及支持将优化器状态、梯度和模型参数从GPU显存下沉到CPU内存或者硬盘上,实现不同程度的显存节省,以便训练更大的模型。不同Stage对应的做法:
- Stage 1: 把 优化器状态(optimizer states) 分片到每个数据并行的工作进程(每个GPU)下
- Stage 2: 把 优化器状态(optimizer states) + 梯度(gradients) 分片到每个数据并行的工作进程(每个GPU)下
- Stage 3: 把 优化器状态(optimizer states) + 梯度(gradients) + 模型参数(parameters) 分片到每个数据并行的工作进程(每个GPU)下
- Optimizer Offload: 在Stage2的基础上,把梯度和优化器状态下沉到CPU内存或硬盘上
- Param Offload: 在Stage3的基础上,把模型参数下沉到CPU内存或硬盘上
假如GPU卡数为N=64,$\psi$是模型参数,假设$\psi$=7.5B,假设使用Adam优化器,在64个GPU下K=12,则:
- 如果不用ZeRO,需要占用120GB的显存,A100最大才80GB,塞不下
- 如果用ZeRO Stage1,则占用31.4GB,A100 40GB或者80GB卡都能跑,单机多卡或多机多卡训练的通信量不变
- 如果用ZeRO Stage2,则占用16.6GB,大部分卡都能跑了,比如V100 32GB,3090 24GB,通信量同样不变
- 如果用ZeRO Stage3,分片到每个数据并行的工作进程(每个GPU)下),则占用1.9GB,啥卡都能跑了,但是通信量会变为1.5倍
PS:从计算过程的角度讲,先正向后反向,再优化器,正向的时候,反向所需的数据不需要在显存中。从层的角度讲,正向反向的时候,计算前面的层时后面层的参数不需要在显存中,所以就可以用通信换省空间。
DeepSpeed 使用
config = {
"train_batch_size": 8,
"gradient_accumulation_steps": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.00015
}
},
"fp16": {
"enabled": True,
}
"zero_optimization": {
}
}
model_engine,optimizer, _, _ = deepspeed.initialize(config=config, model=model, model_parameters=model.parameters())
for step,batch in enumerate(data_loader):
loss = model_engine(batch) # 前向传播
model_engine.backward(loss) # 反向传播
model_engine.step() # 参数更新
if step