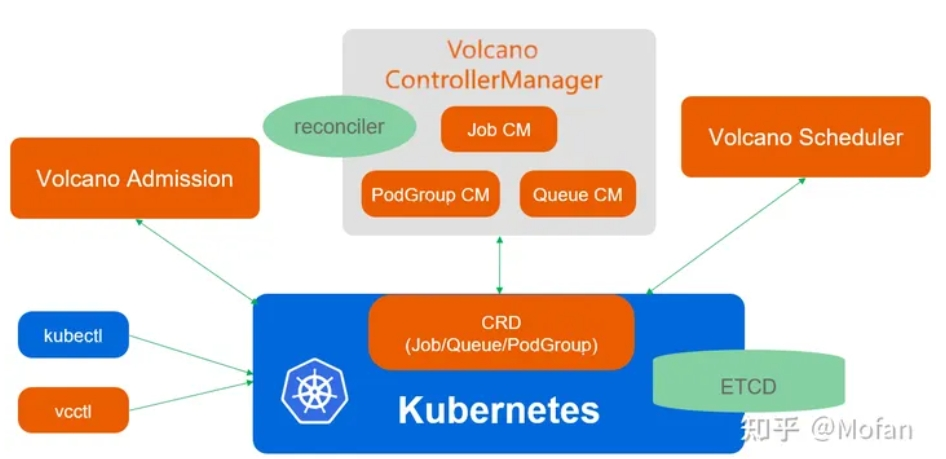
Volcano架构
架构
- Queue
- Queue是容纳一组PodGroup的队列,也是PodGroup获取集群资源的划分依据。
- PodGroup
- PodGroup是一组强关联的pod,对应批处理workload。
- VolcanoJob
- VolcanoJob(vcjob)是自定义的Job资源类型,区别于Kubernetes Job,vcjob可以指定调度器、支持最小运行pod数、支持task、支持生命周期管理、支持指定队列、支持优先级调度等。
Volcano由Scheduler、ControllerManager、Admission和vcctl四个组件组成:
ControllerManager:管理CRD资源的生命周期
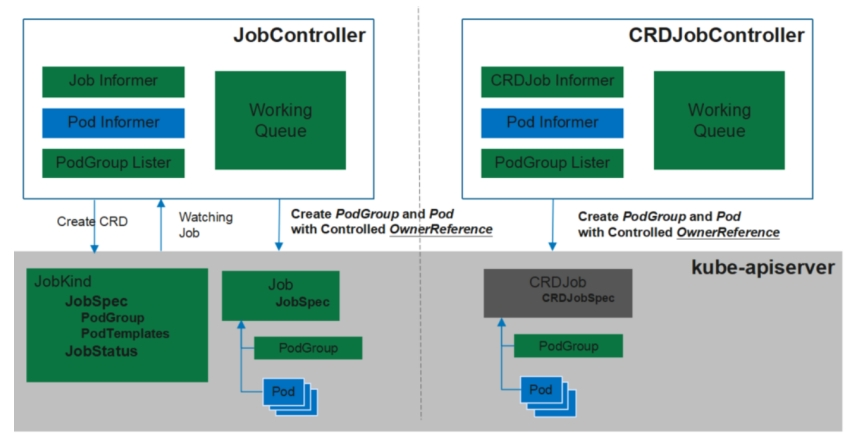
- 左边为Volcano Job Controller,不只调度使用的Volcano,Job的生命周期管理、作业管理都在这里面包含。我们提供了统一的作业管理,你只要使用Volcano,也不需要创建各种各样的操作,就可以直接运行作业。
- 右边为CRD Job Controller,通过下面的PodGroup去做集成。
- 我们来先看一下左侧的架构。在这个Controller里面,有Job Informer监听命令行创建的Volcano的job,监听到事件之后,会创建pod 和 podgroup两种资源,podgroup我们新加的一个概念,它会把调度相关的信息都给transfer到podgroup,然后通过podgroup再下放给schedule。通过这一系列的工作之后,在kube-apiserver里面我们就会看到job、pod以及podgroup的一些信息。这个时候schedule就会拉取pod和podgroup的信息去进行调度的整个过程。右边其实也是非常类似的 。
- 在这里需要强调的是,在设计之初我们就把 job和podgroup两个概念分开。
- 所有跟作业相关的信息,都是放在 job里面;所有跟调度相关的信息都放在podgroup里面,这个设计与Kubernetes非常相像。
Scheduler:通过一系列的action和plugin调度Job,并为容器寻找合适的节点
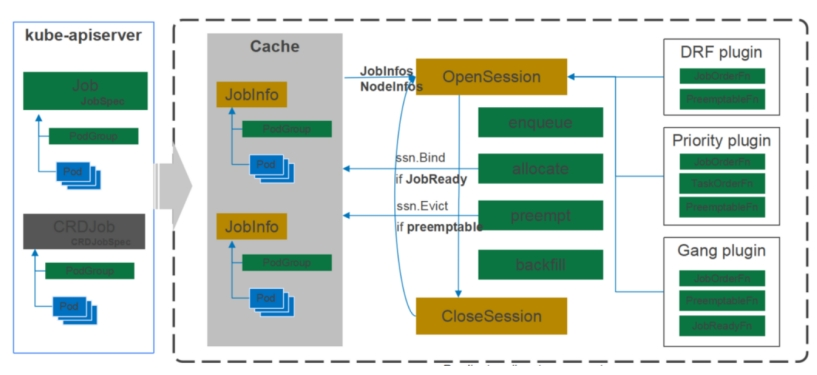
- Scheduler支持动态配置和加载。左边为apiserver,右边为整个Scheduler,apiserver里有Job、Pod、Pod Group;Scheduler分为三部分,第一层为Cache,中间层为整个调度的过程,右边是以插件形式存在的调度算法。Cache会将apiserver里创建的Pod、Pod Group这些信息存储并加工为Jobinfors。中间层的OpenSession会从Cache里拉取Pod、Pod Group,同时将右边的算法插件一起获取,从而运行它的调度工作。
- Cache 缓存了集群中Node和Pod信息,并根据PodGroup的信息重新构建 Job (PodGroup) 和 Task (Pod) 的关系。由于在分布式系统中很难保证信息的同步,因此调度器经常以某一时间点的集群快照进行调度;并保证每个调度周期的决定是一致的。在每个调度周期中,Volcano 通过以下几个步骤派发作业:
- 1、在每个调度周期都会创建一个Session对象,用来存储当前调度周期的所需的数据,**例如,Cache 的一个快照。当前的调度器中仅创建了一个Session,并由一个调度线程执行;后续将会根据需要创建多个Session,并为每个Session分配一个线程进行调度;并由Cache来解决调度冲突。
- 2、在每个调度周期中,会按顺序执行 OpenSession, 配置的多个动作(action)和CloseSession。在 OpenSession中用户可以注册自定义的插件,例如gang、 drf,这些插件为action提供了相应算法;多个action根据配置顺序执行,调用注册的插件进行调度;最后,CloseSession负责清理中间数据。
- 总体来讲,带有动作属性的功能,一般需要引入 action 插件;带有选择 (包括排序) 属性的功能,一般使用 plugin 插件。因此,这些常见场景中,fair-sharing、queue、co-scheduling都通过plugin机制来实现:都带有选择属性,比如“哪些作业应该被优先调度”;
而preemption、reclaim、backfill、reserve 则通过 action 机制来实现:都带有动作属性,比如“作业A 抢占 作业B”。
- 这里需要注意的是,action 与 plugin 一定是一同工作的;fair-sharing 这些 plugin 是借助 allocate 发展作用,而 preemption 在创建新的 action 后,同样需要 plugin 来选择哪些作业应该被抢占。
- action是第一级插件,定义了调度周期内需要的各个动作;默认提供 enqueue入队、allocate分配、 preempt抢占和backfill预留四个action。以allocate为例,它定义了调度中资源分配过程:根据 plugin 的 JobOrderFn 对作业进行排序,根据NodeOrderFn对节点进行排序,检测节点上的资源是否满足,满足作业的分配要求(JobReady)后提交分配决定。由于action也是基于插件机制,因此用户可以重新定义自己的分配动作,例如 基于图的调度算法firmament。
- Preemption: preempt是在allocate之后的一个action,它会为“高”优先级的Pending作业选取一个或多个“低”优先级的作业进行驱逐。由于抢占的动作与分配的动作不一致,因此新创建了preempt action来处理相应的逻辑;同时,在选取高低优先级的作业时,preempt action还是依赖相应的plugin插件来实现。其它动作插件的实现方式也类似,即根据需要创建整体的流程;将带有选择属性的问题转换为算法插件。
- plugin是第二级插件,定义了action需要的各个算法;以drf插件为例,为了根据dominant resource进行作业排序,drf插件实现了 JobOrderFn函数。JobOrderFn函数根据 drf 计算每个作业的share值,share值较低代表当前作业分配的资源较少,因此会为其优先分配资源;drf插件还实现了EventHandler回调函数,当作业被分配或抢占资源后,调度器会通知drf插件来更新share值。
- Job-based Fairness (DRF): 目前的公平调度是基于DRF,并通过 plugin 插件来实现。在 OpenSession 中会先计算每个作业的 dominant resource和每个作业share的初始值;然后注册 JobOrderFn回调函数,JobOrderFn 中接收两个作业对象,并根据对像的 dominant resource 的 share值对作业进行排序;同时注册EventHandler, 当Pod被分配或抢占资源时,drf根据相应的作业及资源信息动态更新share值。其它插件的实现方案也基本相似,在OpenSession中注册相应的回调,例如 JobOrderFn, TaskOrderFn,调度器会根据回调函数的结果决定如何分配资源,并通过EventHandler来更新插件内的调度数。
- 3、Cache 不仅提供了集群的快照,同时还提供了调度器与kube-apiserver的交互接口,**调度器与kube-apiserver之间的通信也都通过Cache来完成,例如 Bind。
Task/Pod 状态转换
Job (PodGroup) 和 Task (Pod)
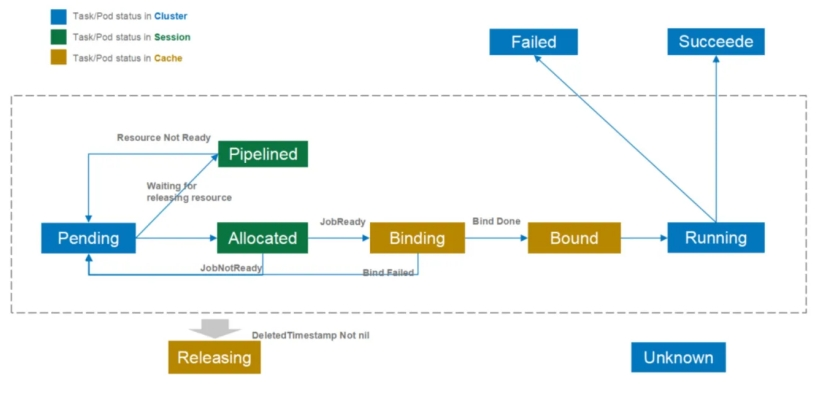
- 我们在Pod和Pod的状态方面增加了很多状态,图中蓝色部分为K8s自带的状态;绿色部分是session级别的状态,一个调度周期,我们会创建一个session,它只在调度周期内发挥作用,一旦过了调度周期,这几个状态它是失效的;黄色部分的状态是放在Cache内的。我们加这些状态的目的是减少调度和API之间的一个交互,从而来优化调度性能。
- 同时,为了支持上面这些场景,Volcano的调度器还增加了多个Pod状态以提高调度的性能:
- Pending: 当Pod被创建后就处于Pending状态,等待调度器对其进行调度;调度的主要目的也是为这些Pending的Pod寻找最优的资源
- Allocated: 当Pod被分配空闲资源,但是还没有向kube-apiserver发送调度决策时,Pod处于Allocated状态。Allocated状态仅存在于调度周期内部,用于记录Pod和资源分配情况。当作业满足启动条件时 (e.g. 满足minMember),会向kube-apiserver提交调度决策。如果本轮调度周期内无法提交调度决策,由状态会回滚为Pending状态。(相当于 default scheduler 中Assume状态)
- Pipelined: 该状态与Allocated状态相似,区别在于处**于该状态的Pod分配到的资源为正在被释放的资源 (Releasing)。**该状态主要用于等待被抢占的资源释放。该状态是调度周期中的状态,不会更新到kube-apiserver以减少通信,节省kube-apiserver的qps。
- Binding: 当作业满足启动条件时,调度器会向kube-apiserver提交调度决策,在kube-apiserver返回最终状态之前,Pod一直处于Binding状态。该状态也保存在调度器的Cache之中,因此跨调度周期有效。
- Bound: 当作业的调度决策在kube-apiserver确认后,该Pod即为Bound状态。
- Releasing: Pod等待被删除时即为Releasing状态。
- Running, Failed, Succeeded, Unknown: 与Pod的现有含义一致。
- Pod的这些状态为调度器提供了更多优化的可能。例如,当进行Pod驱逐时,驱逐在Binding和Bound状态的Pod要比较驱逐Running状态的Pod的代价要小 (思考:还有其它状态的Pod可以驱逐吗?);并且状态都是记录在Volcano调度内部,减少了与kube-apiserver的通信。但目前Volcano调度器仅使用了状态的部分功能,比如现在的preemption/reclaim仅会驱逐Running状态下的Pod;这主要是由于分布式系统中很难做到完全的状态同步,在驱逐Binding和Bound状态的Pod会有很多的状态竞争。
核心调度算法
- Scheduler支持动态配置和加载。
- Gang Scheduling
- Fair Share
- Preempt & Reclaim
- Reserve & Backfill
- Topology Aware Scheduling
- GPU Sharing
Admission:负责对CRD API资源校验;
Vcctl:命令行客户端工具。
Volcano工作流程
1)用户创建一个 Volcano 作业
2)Volcano Admission 拦截作业的创建请求,并进行合法性校验
3)Kubernetes 持久化存储 Volcano Job 到 ETCD
4)ControllerManager 通过 List-Watch 机制观察到Job 资源的创建,创建任务(Pod)
5)Scheduler 负责任务的调度,绑定 Node
6)Kubelet Watch 到 Pod的创建,接管 Pod 的运行
7)ControllerManager 监控所有任务的运行状态,保证所有的任务在期望的状态下运行
作业管理插件
- **svc:**提供不同类型任务之间互访能力
- **env:**任务索引,例如 Tensorflow Worker index
- **ssh:**ssh 秘钥对创建及挂载,主要供 MPI 作业使用
