人群计数相关研究
最近在做人群计数的实验,发现一篇总结很详细的综述文章《CNN-based Density Estimation and Crowd Counting: A Survey》,论文地址是 https://arxiv.org/pdf/2003.12783.pdf
本文内容参考自该综述,总结了其中提到的部分网络和其他人群计数的相关研究,包括损失函数设计评价指标等。
另一个学习人群计数很好的资源项目是c3f,地址是https://github.com/gjy3035/C-3-Framework,另一个很好的学习资源是同作者的awesome总结 https://github.com/gjy3035/Awesome-Crowd-Counting
c3F实现了一些较知名的人群计数算法,从数据集的处理到模型搭建到指标评价,代码写的很友好详细。Awesome-crowd也在持续更新人群计数的最新进展。
相关工作
早期基于检测的工作:
通过聚类检测进行人群计数 《Counting people by clustering person detector outputs》
通过背景分割与头-肩检测进行计数《Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection》
密集场景的行人检测 《Pedestrian detection in crowded scenes》
行人检测 《Monocular pedestrian detection: Survey and experiments》
大多通过滑窗的方式进行头部或者肩部的检测。其余通用目标检测结构,在稀疏场景效果好,但密集人群,遮挡和背景混乱时效果很差。
升级: 基于回归的检测,直接学习图像到目标数量的映射。如Privacy preserving
crowd monitoring: Counting people without people models or tracking, 《Multi-source multi-
scale counting in extremely dense crowd images》,《Bayesian poisson regression for crowd counting》。他们提取全局特征,如纹理、渐变、边缘或者局部特征SIFT LBP HOG GLCM。然后利用线性回归或者高斯回归进行学习特征到数量的映射。
采用密度估计的方法:回归的方法解决了遮挡问题,但是忽略了空间信息,《Learning to count objects in image》学习局部特征到密度图的线性映射,首次提出基于密度估计的方法。解决线性映射的困难,《Deep people counting in extremely dense crowds》提出非线性映射。这些方法都是手工特征。所以后面cnn的发展,自动提取特征。
cnn的方法: 早期的模型使用简单的cnn预测密度图,如《Deep people counting in extremely dense crowds》、《Fast crowd density estimation with convolutional neural networks》、《Cross-scene crowd counting via deep convolutional neural networks》,相比传统手工特征提升巨大。最近主流是基于全连接网络。
具有代表性的网络
分为三类: 传统cnn结构、 多列、单列
传统cnn结构
即卷积+池化+全连接三大块组合而成,而无其他信息。
《Fast crowd density estimation with convolutional neural networks》2015是第一篇引入CNN的人群计数论文,使用两个级联conv-net完成,
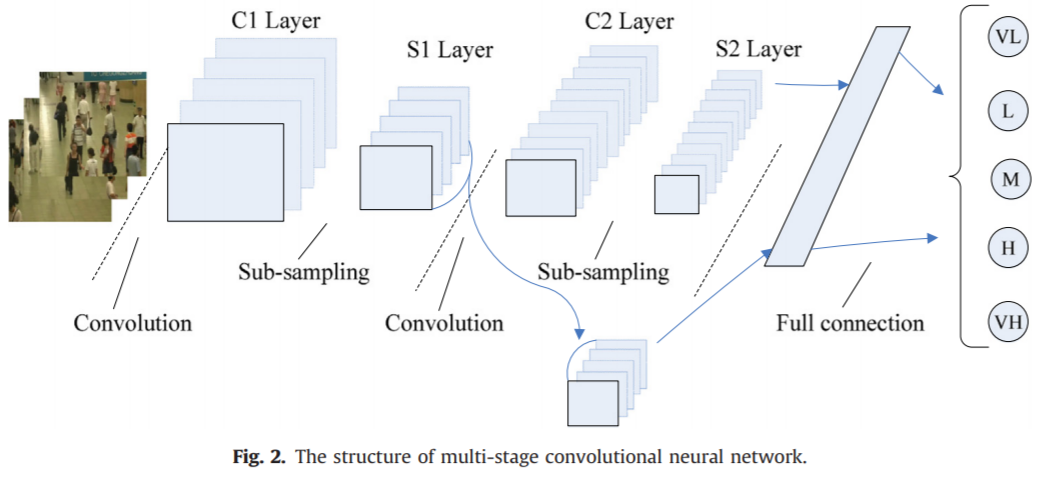
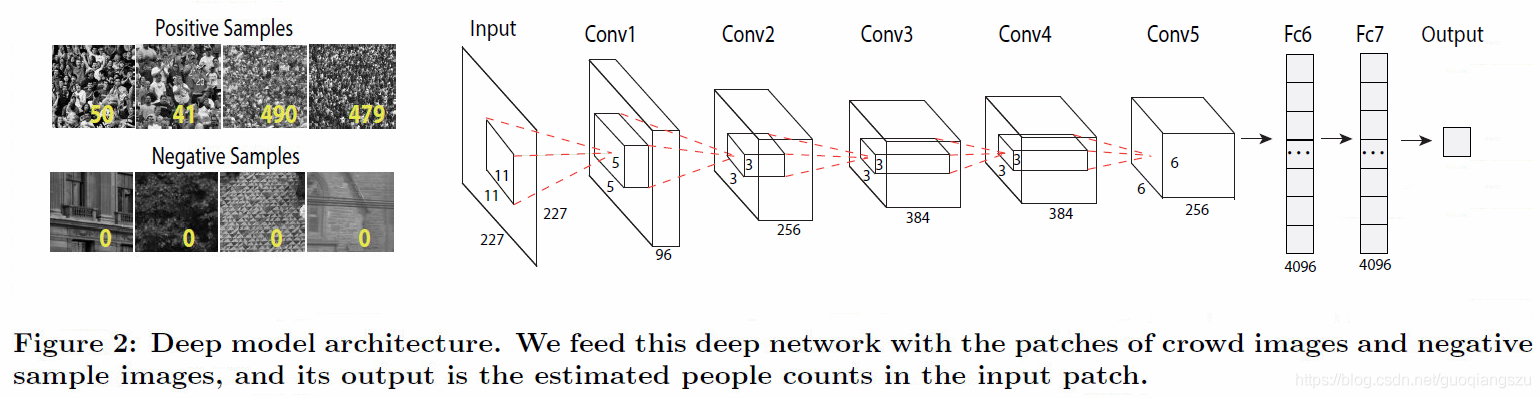
《Deep people counting in extremely dense crowds》2015基于AlexNet实现一个深层的人群计数网络,使用的技巧包括将原图裁剪、翻转生成大量小的patches,而不是直接喂入原图像。
《Learning to count with cnn boosting》2016,利用组合学习的boosting算法,使用了分层增强和选择性采样来提高计数准确性并减少训练时间。
上面这些都是基本的cnn结构,即卷积池化叠加的结构,全连接输出,效果不是很好,后来发展出多列的结构。
多列结构
多列结构是使用不同列捕获不同尺度的信息,从而提高精度。
《Single-image crowd counting via multi-column convolutional neural network》cvpr2016,
是第一篇使用多列结构的人群计数网络,它受MDNN的启发,有三个结构和深度都相同的分支,只是卷积的大小不同,最后组合,生成密度图,而不是输出统计的数字。三个分支捕获不同尺度信息,但是三个分支太相似,而且很浅,整个结果看来只是几个弱回归变量的组合,效果不是很好。
另外,第一篇使用密度图输出的计数论文是2010年的《Learning To Count Objects in Images》。
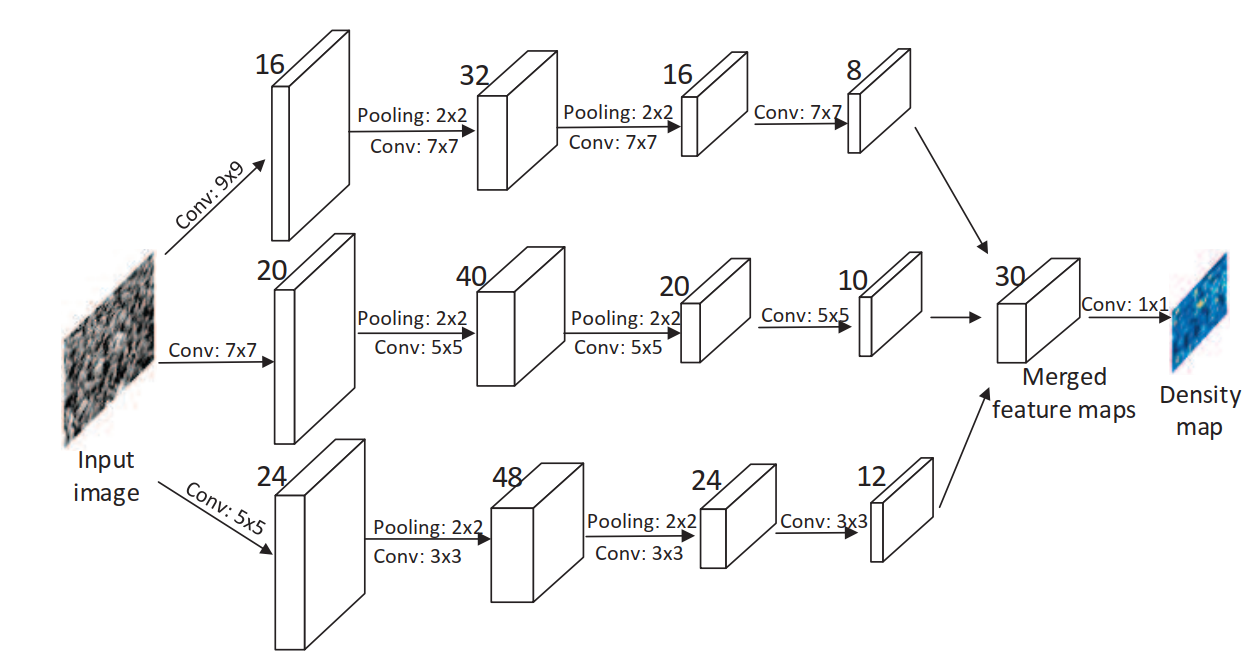
《Towards perspective-free object counting with deep learning》
该论文两个要点:提出了一个 novel convolutional neural network:Counting CNN (CCNN),将图像块回归到密度图,; 提出Hydra CNN,学习多尺度非线性回归的计数模型。


Hydra网络的输入是patches的金字塔,金字塔的每一层都重设到固定大小然后输入。
《Crowdnet: A deep convolutional network for dense crowd counting》2016,
Crowdnet的输入分别进入两个网络,一个deep netweork是类似vgg的结构,去掉了全连接,是一个全卷积的结构,该部分卷积核小,捕获高级语义信息,另一部分shallow network,卷积核大,检测距离相机视角远的人头,最后concat两个部分的输出,使用1x1卷积输出,双线性插值恢复到原图像尺寸,即为图像的特征图。

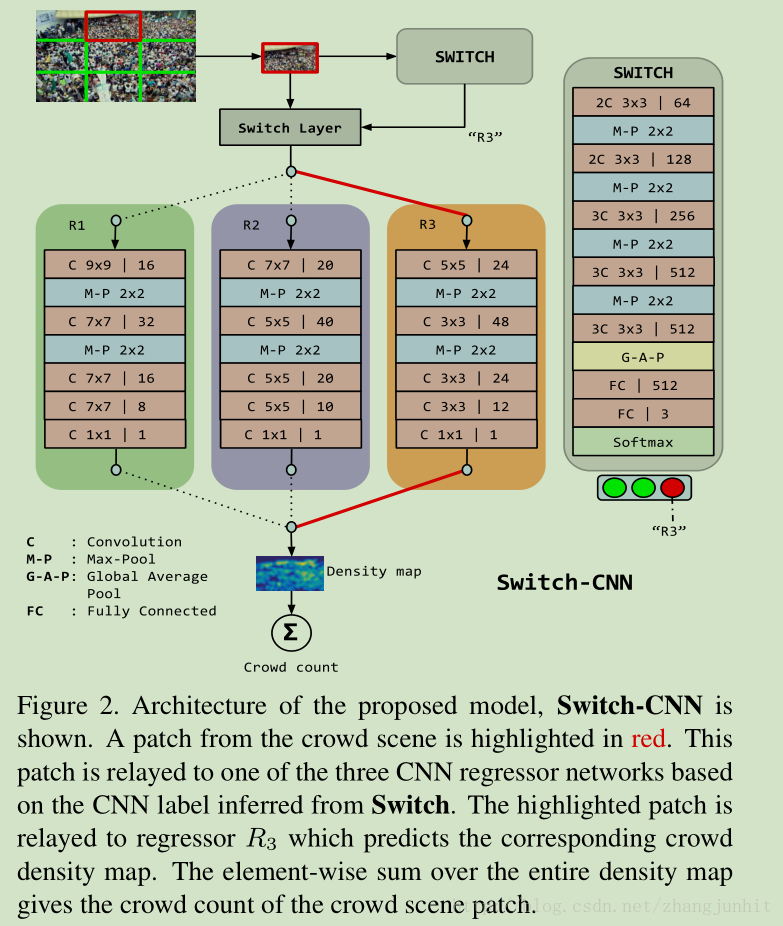
《Switching convolutional neural network for crowd counting》2017.
Switch-CNN。该论文在图像块上训练多个独立的cnn,先把图像分为3x3份,对每份使用一个cnn网络输出,即图中的switch,看它适合选择后面那个网络进行密度估计,一共有三种选择。三种选择的网络结构设计参考的是MCNN,而switch部分则是基于vgg16。
《Generating high-quality crowd density maps using contextual pyramid cnns》2017
CP-CNN,该论文的改进点是结合整体和局部信息,从而提高检测精度。该论文认为:
1)这些方法都没有显示的嵌入 context 信息,而 context 信息对提升性能很有帮助 2)当前基于回归的密度图估计方法更侧重降低人群总数估计误差,而不是侧重人群密度图的质量 3)当前的 CNN 网络基本都是使用 像素级欧式损失函数来训练网络,这导致密度图比较模糊。https://blog.csdn.net/zhangjunhit/article/details/78029133
网络结构如下,GCE和LCE是分类网络,分别获取全局和局部context信息,文章将图像的密度分为5个级别,很低、低、中等、高和很高。而DME是类似MCNN的三列结构,将图像映射到高维的特征图,最后使用F-CNN整合三个部分学习到特征。更多信息可以参考原文和这篇博客https://blog.csdn.net/zhangjunhit/article/details/78029133

《Top-down feedback for crowd counting convolutional neural network》 2018
TDF-CNN,将自上而下的信息传递给自下而上的网络以修改密度估计。
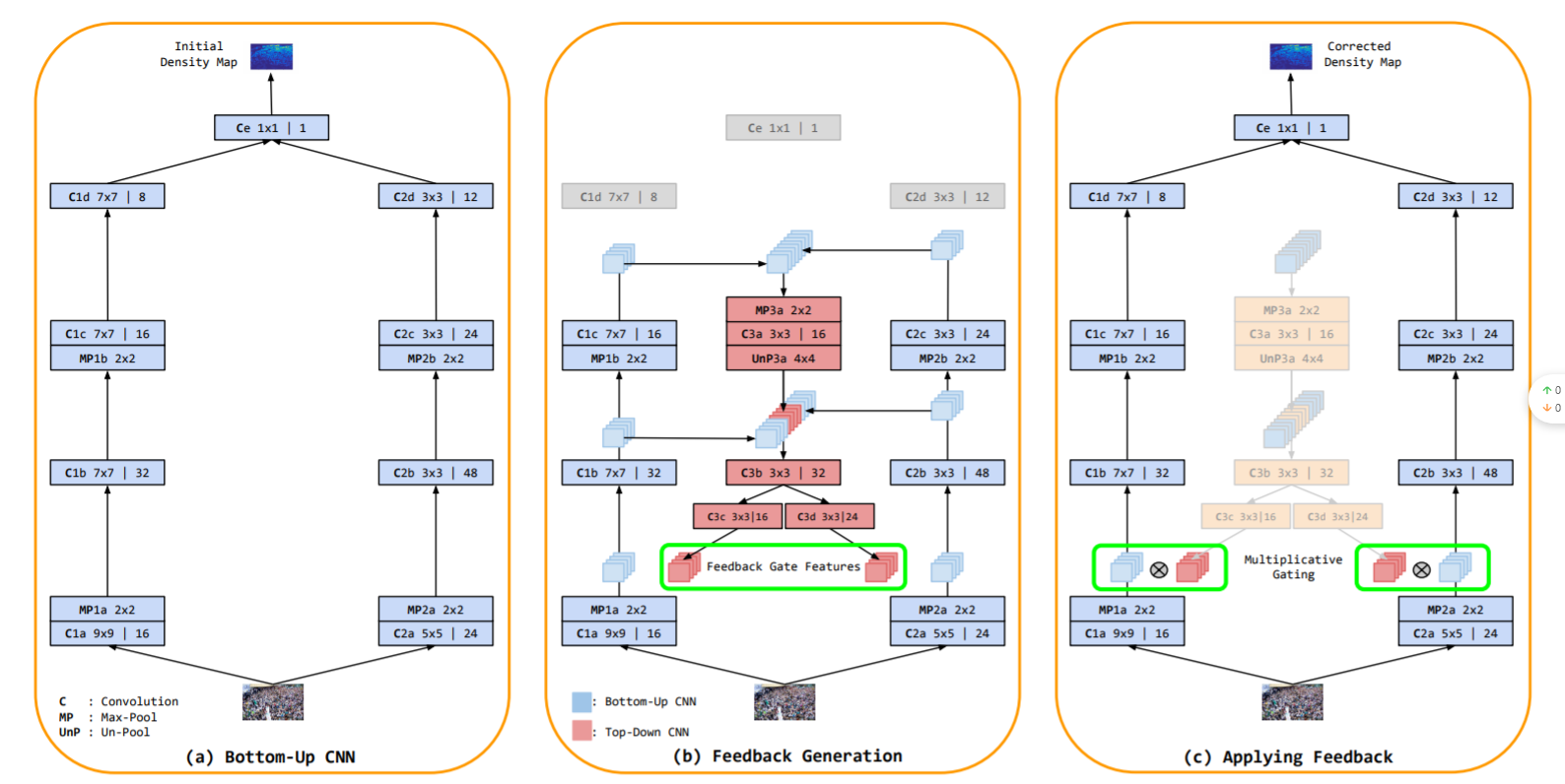
《Crowd counting using deep recurrent spatial-aware network》
DRSAN,利用空间变压器网络(STN)处理尺度变化和旋转变化的问题
《Crowd counting using scale-aware attention networks》2019
SAAN。类似于CP-CNN的思想,利用视觉注意机制自动为全局图像级别和局部图像补丁级别选择特定的比例
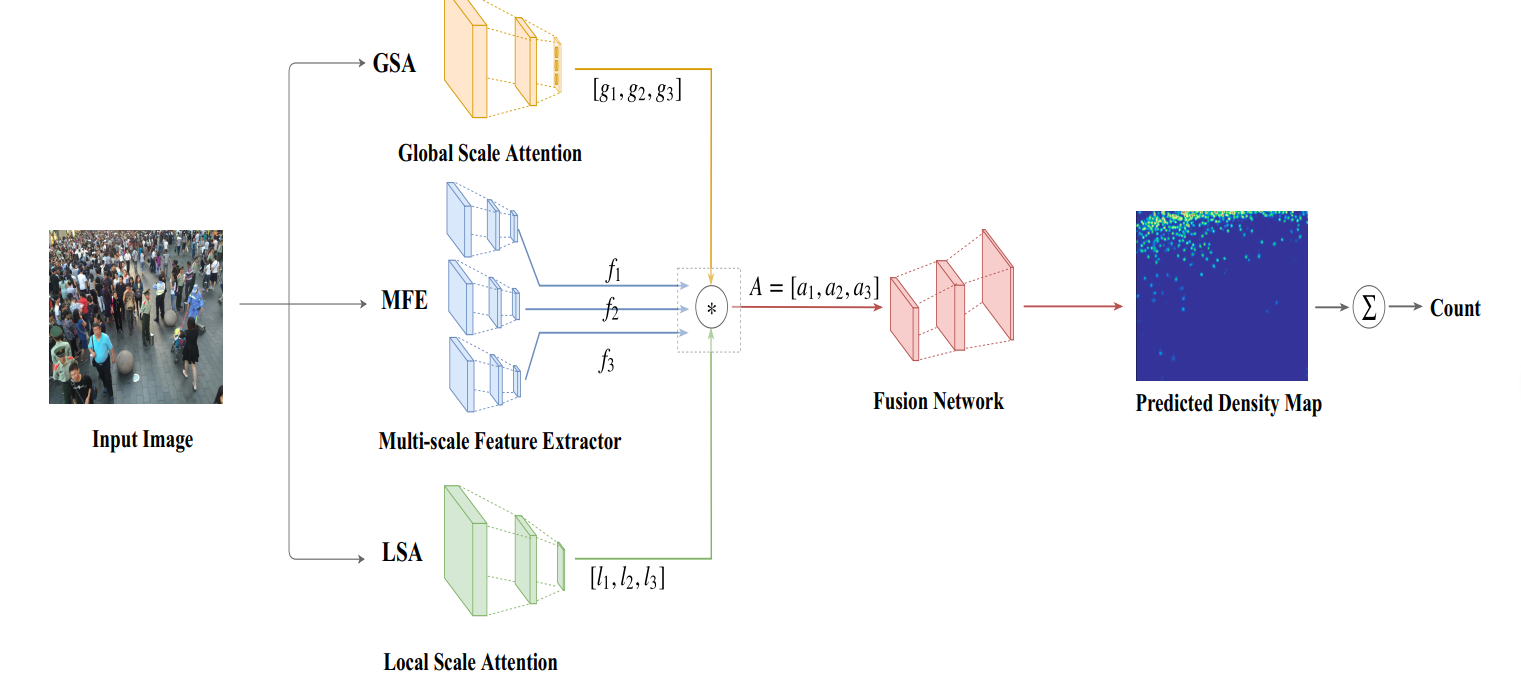
整体结构如上,GSA是全局尺度注意力网络,MFE是一个多尺度的特征提取结构,LSA是局部尺度注意网络。
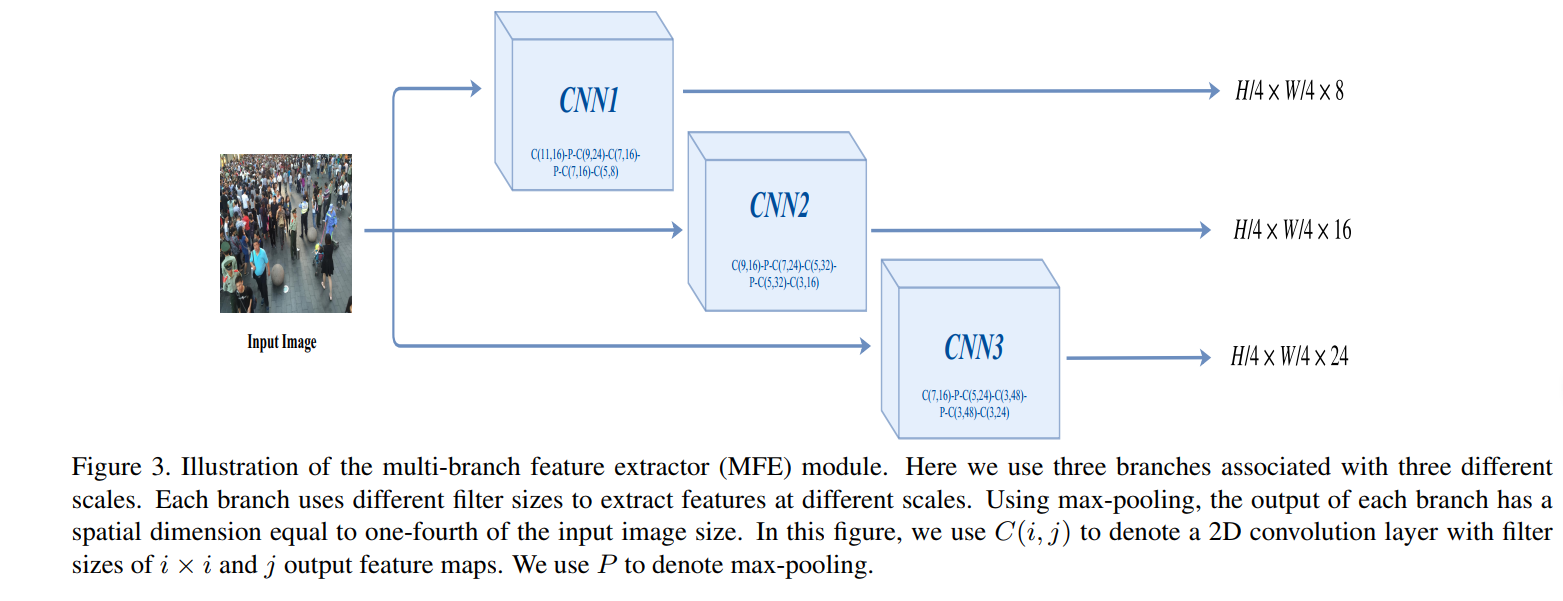
MFE采用多个分支获取多尺度的特征。
该论文将注意力集中在尺度上,其中GSA是用于捕获全局的上下文信息,类似之前的CP-CNN,但是只将密度分为了三个级别:低密度、中密度和高密度。结构如下,网络输出三个得分,分别代表了三个预定义的密度级别。
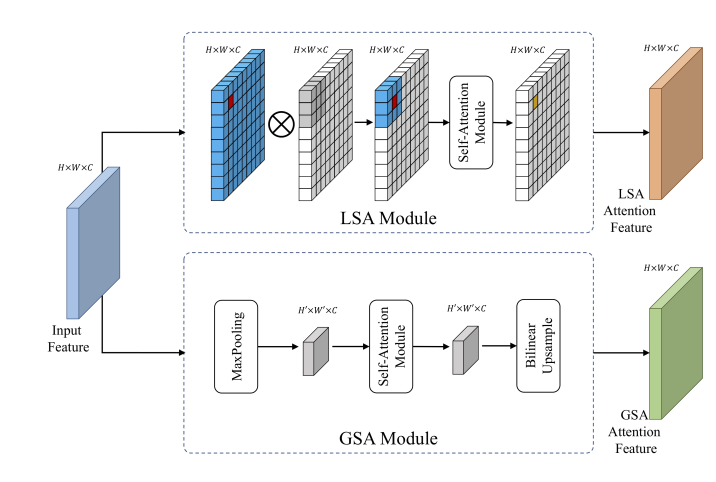
一张图的不同区域密度级别不一样,因此增加了LSA捕获局部密度信息。
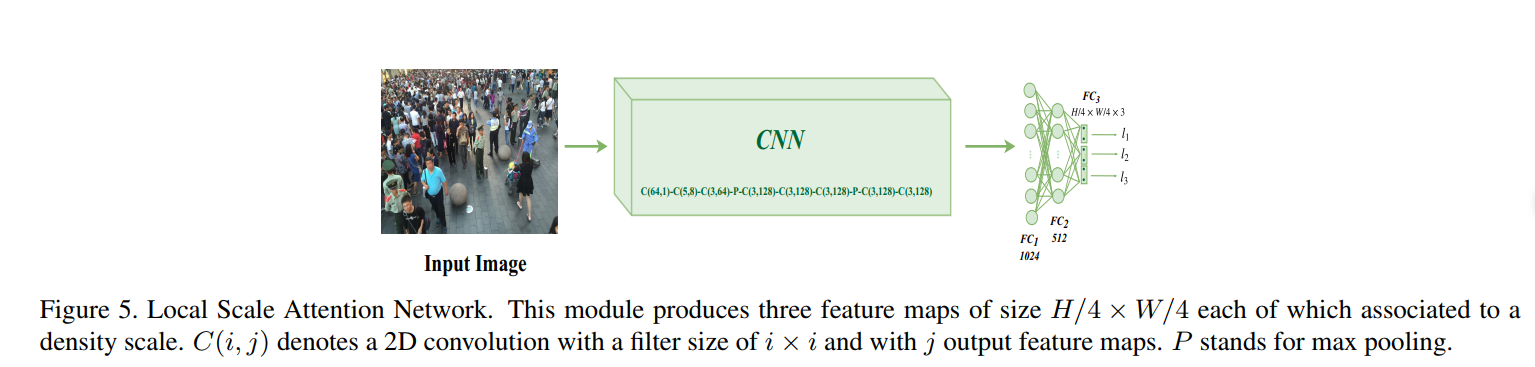
LSA的输出也是三个数,但是它在最后用的sigmoid激活,而GSA是softmax输出三个值。
最后那个GSA、LSA和MFE的输出融合,可以看到MFE的三个分支输出都是一样的尺寸,但是通道数不一样,设定低密度,中密度和高密度的通道数分别设置为24、16和8(卷积核越大,感受野范围越广,因此密度越大,即图上的第一个分支是高密度)。
融合的方式是加权,加权后的特征图再送入Fusion Network,该部分是卷积与反卷积组成,反卷积的目的是上采样,恢复特征图的大小为原始图像大小,最后经过一个1x1的卷积得到预测的图像密度图。
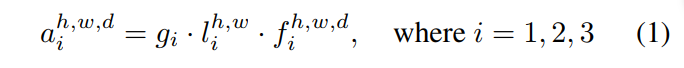
另外在损失函数上,除了密度图与gt之间的距离,还考虑了全局和局部的尺度注意力。而这个尺度注意力的计算如下:
对于数据集的gt,找到人数的范围,即人数最多的那张图的值和最少的值,将这个范围分为三段,实际上就是对应着之前提到的三个密度级别,然后对于某一张具体图片的全局尺度注意力得分进行计算。某张具体图片的gt的人数,落在划分的哪一段,如{1,2,3},那么该图像的全局尺度值即为该值,然后该图像在GSA的输出是三个尺度的预测得分g,将这三个数g与gt进行比较,使用多类交叉熵损失函数CE计算。如该图像在GSA的输出是g = [0.2,0.5,0.3],而该图的标签是高密度,即gt=[0,0,1]。那么计算CE(g,gt)的结果即为这个GSA的损失值。
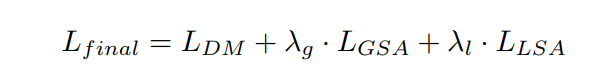
相应的,局部的尺度注意力损失值计算类似,计算gt的局部尺度注意力范围是指 每个像素的64x64邻域的密度范围,即计算每个像素的邻域密度值,然后统计整个图的像素邻域密度值范围。将这个范围分为三段。 然后具体某个像素的的局部尺度值,与LSA的输出进行交叉熵计算。
《Relational attention network for crowd counting》2019
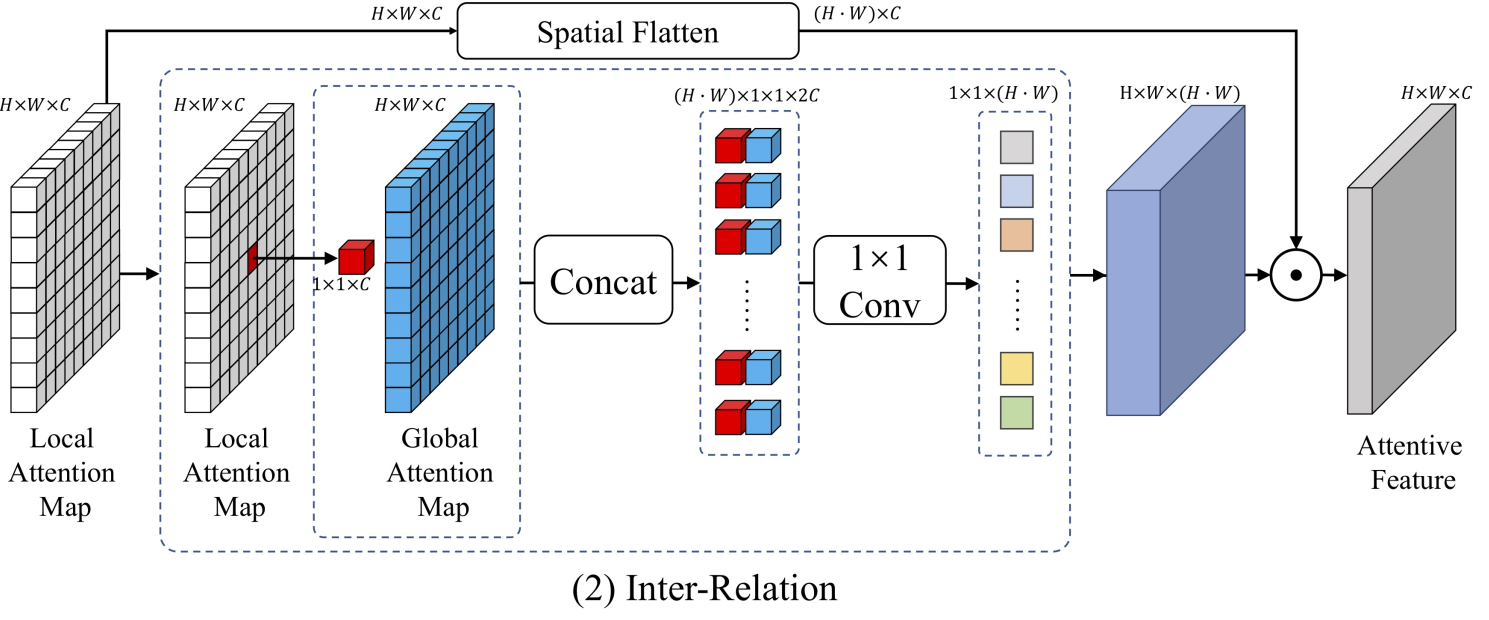
RA-Net,该网络也是使用了局部注意力和全局注意力。用LSA和GSA生成两个特征图,(这里的SA是self-attention,SAAN中的SA是指Scale attention)。
得到两种特征图后,进行特征的融合,论文中提出三种融合方式,
一种是 Intra-Relation,它又分为sum和concat的方式,故实际上Intra-Relation是两种不同的方式,融合方式也很简单,如下图。一个采用concat后卷积输出,另外一种直接相加输出。
另一种融合方式是Inter-Relation,
《Improving the learning of multi-column convolutional neural network for crowd counting》
McML,该论文是对多列卷积网络计数的思考,提出一种可以用于任何多列CNN的结构组件,如下图,其中的statistical network整合了两列的信息,最后输出参数Iw应用于各自列的特征图输出。
McML已将统计网络集成到多列结构中,以自动估计列之间的相互信息。统计网络的本质是分类器网络。具体来说,输入是来自不同列的要素,而输出是列之间的相互信息。我们使用互信息来大致指示不同列中要素之间的比例相关性。通过最大程度地减少列之间的相互信息,McML可以指导每一列专注于不同的图像比例信息。(原文对McML的描述)
《Dadnet: Dilated-attention-deformable convnet for crowd counting》2019
DadNet,扩张-注意-可变形( Dilated-Attention-Deformable)卷积网络
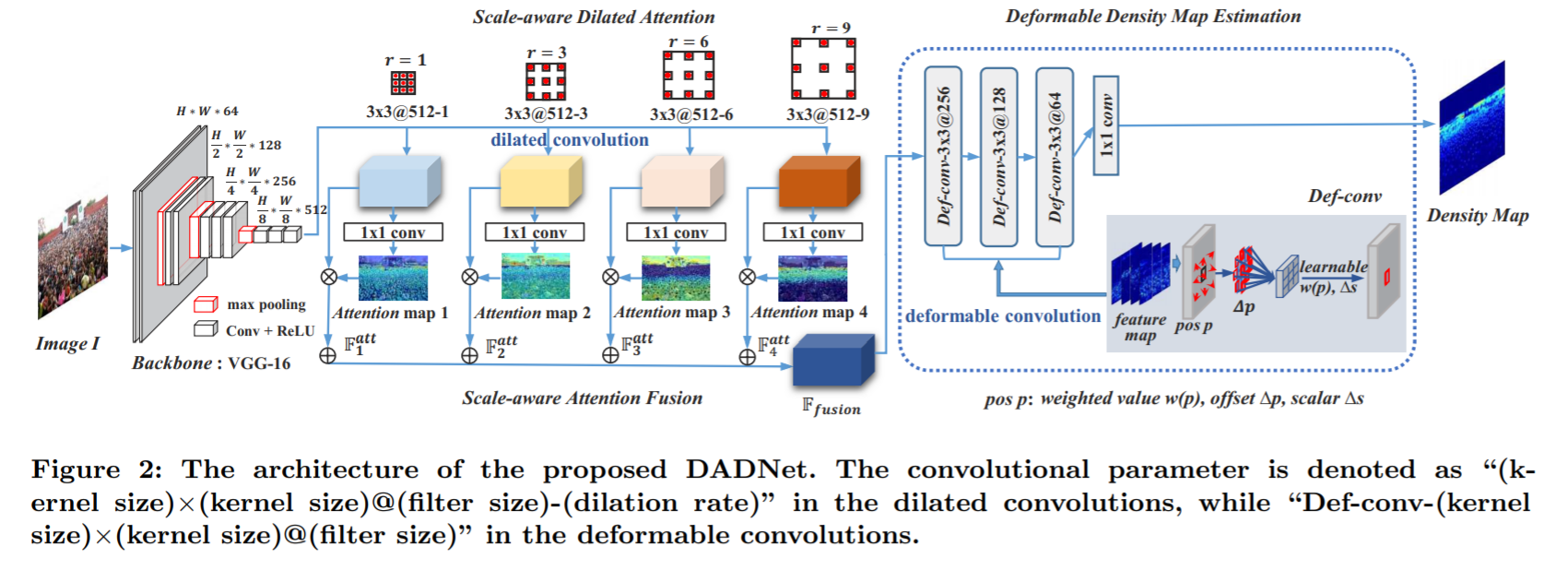
文章侧重于特征融合,对于多尺度问题采用空洞卷积,从而获得不同大小的感受野。总体结构如上。
骨干网络VGG输出原图1/8的尺寸,然后将其通过四个不同扩张尺寸的空洞卷积和1x1普通卷积,得到四个对应不同感受野尺度的特征图,这四个特征图再依次乘上其对应的原空洞卷积输出,最后叠加为融合后的特征,将其输入最后的可变形模块,最后的可变形模块是连续三个可变形卷积,其输出经过1x1卷积后即为最终的估计密度图。
单列的cnn模型
多列cnn的效果很好,但仍有缺点,在《Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes》(CVPR 2018)论文中有讨论。该论文提出CSRnet,使用单列的空洞卷积,上面的DadNet的空洞思想也启发自该网络,
CSRnet中提出的多列卷积缺点:1)训练困难,时间长。2)各列的结果相似,效果大同小异,冗余大。3)分类器的精度难以把控,高精度的分类器又会导致模型结构过于复杂。4)参数浪费,大量参数被用于密度等级分类器,使得密度生成部分反而精度不足。
单列网络体系结构通常部署单个和更深的CNN,而不是多列网络体系结构的膨胀结构,并且前提是不增加网络的复杂性。
W-VLAD : 《Crowd counting via weighted vlad on dense attribute feature maps》
该论文提出一种LAF结构,对比SPP,可以来表示空间信息。
学习范式
人群计数分为多任务和单任务。大多是单任务范式,即生成密度图,然后求和得到人数或者直接回归出人数。
多任务:通过结合密度估计和其他任务(例如分类,检测,分割等)而表现出更好的性能。基于多任务的方法通常设计有多个子网此外,与纯单列架构相比,可能存在对应于不同任务的其他分支。综上所述,多任务体系结构可以看作是多列和单列之间的交叉融合,但二者都不相同
推理方式
基于patches和基于整幅图像的。前者通常将图像分成小块送入训练,各小块得出其密度估计图后进行整合,后者送入整幅图像训练。
基于patches的方法特点是忽略全局信息,且滑窗导致计算成本大。后者缺点是忽略局部信息。
监督方式
全监督和半/无/自监督。
评估指标
分为三类:图像级的计数值评估,像素级的密度图质量评估,点级的定位精度评估。
图像级指标
-
MAE和RMSE
\[\begin{array}{c} M A E=\frac{1}{N} \sum_{i=1}^{N}\left|C_{I_{i}}^{p r e d}-C_{I_{i}}^{g t}\right| \\ R M S E=\sqrt{\frac{1}{N} \sum_{i=1}^{N}\left|C_{I_{i}}^{p r e d}-C_{I_{i}}^{g t}\right|^{2}} \end{array} \]即直接比较gt的人数与预测密度图的人数。MAE可以评估准确性,RMSE可以
-
GAME 因为MAE没有考虑位置信息,故提出Grid Average Mean Absolute Error 。
\[\operatorname{GAME}(L)=\frac{1}{N} \sum_{n=1}^{N}\left(\sum_{l=1}^{4^{L}}\left|C_{I_{i}}^{p r e d}-C_{I_{i}}^{g t}\right|\right) \]其中\(4^L\)表示将图像划分为一些不重叠的区域,\(L\)越大,对GAME指标的限制越大
质量评估PSNR等,略
其他
模型设计
数据集坐标到密度图的生成
高斯核,自适应,结合K近邻等。
密度图的三种方式生成:
- 使用高斯核 适用于场景没有严重透视失真的场景
- 透视密度图 适用于固定场景,利用行人高度线性回归生成的透视图,对不同的头部生成不同大小的高斯核。出自论文 跨场景人群计数Cross-scene Crowd Counting via Deep Convolutional Neural Networks
- k-nn密度图 mcnn论文提出。
损失函数
最常用欧几里得距离损失,此外smoothL1损失,tukey损失具有更强的鲁棒性,对抗性损失可以用来提升密度图质量,轻量级的局部SSIM损失结合欧式距离损失,来增强密度图和标签的结构相似性。TEDnet提出的损失:空间抽象损失SAL,Spatial Abstraction Loss将密度图做金字塔池化,计算不同空间层上的MSE,考虑到了像素空间的关联性,而不是独立像素。类似于DSnet的密度图池化后计算损失。另一个是空间相关性损失SAL,Spatial Correlation Loss,通过互相关系数计算比较估计图和gt的相似性,计算如下,其中pq是图像的横纵坐标。Z和Y表示各自在各个像素点处的值。
经过简单的实验,DSNet论文中提到的一致性损失确实很有效,即将密度图和真实图进行自适应平均池化,目的是汇聚局部信息,因为原来的L2损失是只比较了单个像素点,现在将一个区域汇聚后再进行比较,考虑到了邻域像素,因此更有效,类似于金字塔池化的SAL损失。一致性损失的torch实现如下。
def cal_lc_loss(output, target, sizes=(1,2,4)):
criterion_L1 = nn.L1Loss()
Lc_loss = None
for s in sizes:
pool = nn.AdaptiveAvgPool2d(s) # 输出s*s
est = pool(output)
gt = pool(target)
if Lc_loss:
Lc_loss += criterion_L1(est, gt)
else:
Lc_loss = criterion_L1(est, gt)
return Lc_loss

