
"同步"三二事
关于“CDC数据同步”的作业经验
不同的业务模式会有不同的同步方案(根据自己的业务模式进行相应调整)
本次使用
canal ==> kafka ==> logstash ==> es
一,canal
1.概念:canal是阿里巴巴旗下的一款开源项目,Java开发(依赖于java所需的一切依赖)。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
2.工作原理
canal将自己模拟成MySQL的从库,读取MySQL的binlog日志
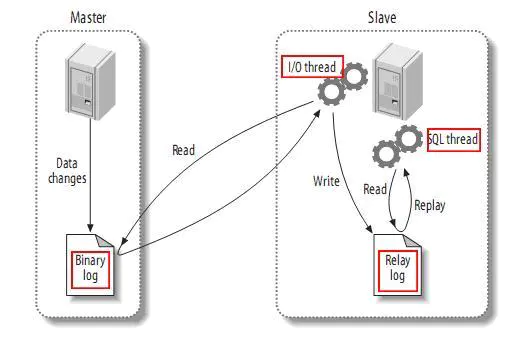
复制分成三步:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
- 搭建集群时依赖zookeeper
- canal将读到的mysql的binlog发送给kafka,作为kafka的消息生产者
二,kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
原理:Kafka 是一个消息系统,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家公司作为多种类型的数据管道和消息系统使用。活动流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据),总的来说,运营数据的统计方法种类繁多
Message Queue 的通讯模式
- 点对点通讯:点对点方式是最为传统和常见的通讯方式,它支持一对一、一对多、多对多、多对一等多种配置方式,支持树状、网状等多种拓扑结构。
- 多点广播:MQ 适用于不同类型的应用。其中重要的,也是正在发展中的是”多点广播”应用,即能够将消息发送到多个目标站点 (Destination List)。可以使用一条 MQ 指令将单一消息发送到多个目标站点,并确保为每一站点可靠地提供信息。MQ 不仅提供了多点广播的功能,而且还拥有智能消息分发功能,在将一条消息发送到同一系统上的多个用户时,MQ 将消息的一个复制版本和该系统上接收者的名单发送到目标 MQ 系统。目标 MQ 系统在本地复制这些消息,并将它们发送到名单上的队列,从而尽可能减少网络的传输量。
- 发布/订阅 (Publish/Subscribe) 模式:发布/订阅功能使消息的分发可以突破目的队列地理指向的限制,使消息按照特定的主题甚至内容进行分发,用户或应用程序可以根据主题或内容接收到所需要的消息。发布/订阅功能使得发送者和接收者之间的耦合关系变得更为松散,发送者不必关心接收者的目的地址,而接收者也不必关心消息的发送地址,而只是根据消息的主题进行消息的收发。
- 群集 (Cluster):为了简化点对点通讯模式中的系统配置,MQ 提供 Cluster(群集) 的解决方案。群集类似于一个域 (Domain),群集内部的队列管理器之间通讯时,不需要两两之间建立消息通道,而是采用群集 (Cluster) 通道与其它成员通讯,从而大大简化了系统配置。此外,群集中的队列管理器之间能够自动进行负载均衡,当某一队列管理器出现故障时,其它队列管理器可以接管它的工作,从而大大提高系统的高可靠性。
Kafka 专用术语
-
Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。
-
Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
-
Partition:Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。
-
Producer:负责发布消息到 Kafka broker。
-
Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
-
Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。
Kafka 特性
Kafka 的几个特性非常满足我们的需求:可扩展性、数据分区、低延迟、处理大量不同消费者的能力。这个案例我们可以配置在 Kafka 中为登录和交易配置同一个主题。由于 Kafka 支持在单一主题内的排序,而不是跨主题的排序,所以我们为了保证用户在交易前使用实际的 IP 地址登录系统,我们采用了同一个主题来存储登录信息和交易信息。
当用户登录或者发起交易动作后,负责接收的服务器立即发事件给 Kafka。这里我们采用用户 id 作为消息的主键,具体事件作为值。这保证了同一个用户的所有的交易信息和登录信息被发送到 Kafka 分区。每一个事件处理服务被当作一个 Kafka 消费者来运行,所有的消费者被配置到了同一个消费者群组,这样每一台服务器从一些 Kafka 分区读取数据,一个分区的所有数据被送到同一个事件处理服务器 (可以与接收服务器不同)。当事件处理服务器从 Kafka 读取了用户交易信息,它可以把该信息加入到保存在本地内存中的历史信息列表里面,这样可以保证事件处理服务器在本地内存中调用用户的历史信息并做出预警,而不需要额外的网络或磁盘开销。
综上所述,Kafka 的设计可以帮助我们解决很多架构上的问题。但是想要用好 Kafka 的高性能、低耦合、高可靠性、数据不丢失等特性,我们需要非常了解 Kafka,以及我们自身的应用系统使用场景,并不是任何环境 Kafka 都是最佳选择。
三,logstash
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Logstash是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储”。(当然,我们最喜欢的是Elasticsearch)
输入:采集各种样式、大小和来源的数据(数据源:文件,filebeat,kafka,redis,rabbitmq等。。。)
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤:输入的数据可能会包含一些垃圾数据,敏感数据,特许数据
Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
-
- 利用 Grok 从非结构化数据处理输入的数据
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段,可将敏感字段进行所需的修改及输出
- 整体处理不受数据源、格式或架构的影响
- 可判断多数据源时发生的不同数据过滤不同信息
输出:选择你所需要的存储,输出数据到你最舒适的终端
Elasticsearch 首选输出方向,这样能够为我们的搜索和分析带来无限方便,但它并非唯一选择。(还可输出致flume,hive,hbase等不同类型的nosql中)
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例
在这里我们选择输出到 ES(Elasticsearch)
配置:我们使用logstash做kafka的消费者,数据输出存储到 ES 中,需在配置文件中做好数据源及数据目标的地址
四,Elasticsearch(概念较多需根据理解自行体会,此处不多写)
概念:Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
分片机制:我们不用关心数据是按照什么机制分片的、最后放入到哪个分片中
分片的副本:
集群发现机制(cluster discovery):比如当前我们启动了一个es进程,当启动第二个es进程时,这个进程作为一个node自动就发现了集群,并且加入了进去
shard负载均衡:比如现在有10shard,集群中有3个节点,es会进行均衡的进行分配,以保证每个节点均衡的负载请求
请求路由
对于使用Elasticsearch进行索引时需要注意:
-
- 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
- 同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
- 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询

