

docker配置深度学习环境
版权声明:本文为博主原创文章,转载注明出处即可。 https://blog.csdn.net/bskfnvjtlyzmv867/article/details/81017226
序
阅读本篇文章可以帮你解决的问题是:提供一套解决方案,能够在支持Docker的任何版本Ubuntu系统下,搭建出完美运行各种深度学习框架、各种版本、各种环境依赖(NAIVID显卡)深度学习工程的开发环境。不仅如此,还要像在本机一样方便的修改代码运行计算。
搭建深度学习计算平台,一般需要我们在本机上安装一些必要的环境,安装系统、显卡驱动、cuda、cudnn等。而随着Docker的流行,往往能够帮我们轻松的进行环境搭建、复制与隔离,所以官方也利用容器技术与深度学习相结合,因此也出现了以下方案。
容器方案比传统方案带来更多的随意性,装系统前不需要考虑Ubuntu哪一个版本符合不符合我们的代码运行要求,我们只需要安装一个自己喜欢的(18.04完全可以),再在官网下载一下显卡驱动,或者软件源附加驱动更新一下就行了,剩下都不需要我们继续考虑。这些也非常的轻松,因为Nvidia对Ubuntu的支持越来越友好,我们只需要下载deb包,一行命令即可安装成功。
| 系统 | 显卡驱动 | Cuda | Cudnn | |
|---|---|---|---|---|
| 传统方案 | 一种版本 | 必需 | 一种版本 | 必需 |
| 容器方案 | 各种版本 | 必需 | 非必需 | 非必需 |
安装显卡驱动可以参照:https://blog.csdn.net/bskfnvjtlyzmv867/article/details/80102000
正式进入正文之前,确保你已经安装好趁手的系统和显卡驱动。
I. 安装Docker
关于Docker教程,详见:Docker——入门实战
安装指定版本Docker CE
这里的版本由第二部分的Nvidia Docker依赖决定,笔者在写此文时需要的版本是18.03.1,如果在安装Nvidia Docker时依赖的Docker CE版本已经变更,可以卸载重新安装需要的版本。
sudo apt install curl
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
echo "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial edge" | sudo tee /etc/apt/sources.list.d/docker.list
sudo apt-get update && sudo apt-get install -y docker-ce=18.03.1~ce-0~ubuntu1234
执行这个命令后,脚本就会自动的将一切准备工作做好,并且把Docker CE 的Edge版本安装在系统中。
启动Docker CE
sudo systemctl enable docker
sudo systemctl start docker12
建立docker 用户组
默认情况下,docker 命令会使用Unix socket 与Docker 引擎通讯。而只有root 用户和docker 组的用户才可以访问Docker 引擎的Unix socket。出于安全考虑,一般Ubuntu系统上不会直接使用root 用户。因此,更好地做法是将需要使用docker 的用户加入docker用户组。
# 建立docker组
sudo groupadd docker
# 将当前用户加入docker组
sudo usermod -aG docker $USER1234
注销当前用户,重新登录Ubuntu,输入docker info,此时可以直接出现信息。
配置国内镜像加速
在/etc/docker/daemon.json 中写入如下内容(如果文件不存在请新建该文件)
{
"registry-mirrors": [
"https://registry.docker-cn.com"
]
}12345
重新启动服务
sudo systemctl daemon-reload
sudo systemctl restart docker12
II. 安装Nvidia Docker2
Nvidia Docker2项目的主页:https://github.com/NVIDIA/nvidia-docker
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers
ocker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
# Add the package repositories
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo apt-get update && sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
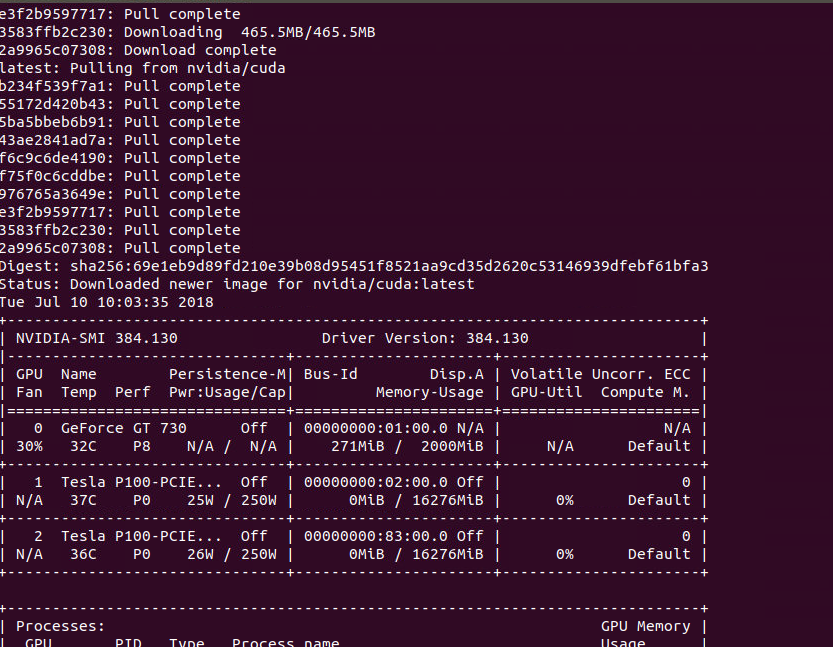
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi1234567891011121314
III. 搭建环境
拉取镜像
Nvidia官网在DockerHub中提供了关于深度学习的各个版本环境,点我…有Ubuntu14.04-18.04,Cuda6.5-9.2,Cudnn4-7,基本含盖了我们所需要的各种版本的深度学习环境,我们直接拉取镜像,在已有的镜像基础上配置我们的深度学习环境。
下载镜像,这里以ubuntu16.04、cuda8.0、cudnn5.1的版本为例,我们找到满足版本要求的TAG为8.0-cudnn5-devel-ubuntu16.04。
# 拉取镜像
docker pull nvidia/cuda:8.0-cudnn5-devel-ubuntu16.04
# 查看镜像
docker images -a1234
创建启动容器
利用下载好的镜像,创建一个交互式的容器。容器需要使用nvidia显卡,需要设置额外的参数。
docker run -it --name 自定义容器名 -v /home/你的用户名/mnist/:/home/你的用户名/mnist/ --runtime=nvidia -e NVIDIA_VISIBLE_DEVICE=0,1 nvidia/cuda:8.0-cudnn5-devel-ubuntu16.041
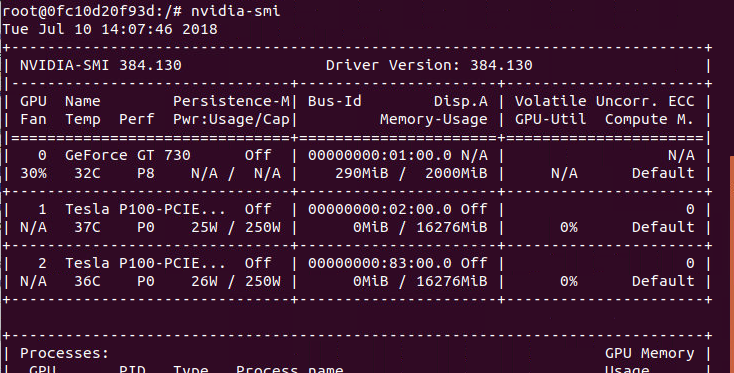
NVIDIA_VISIBLE_DEVICE参数指定对容器分配几块GPU资源;-v参数用于挂载本地目录,冒号前为宿主机目录,冒号后为容器目录,两个可以设置为一样比较方便代码书写。配置目录挂载是为了方便本文下一部分测试Mnist服务。容器启动完毕,此时,可以像正常本机配置的深度学习环境一样,测试各个软件的版本。
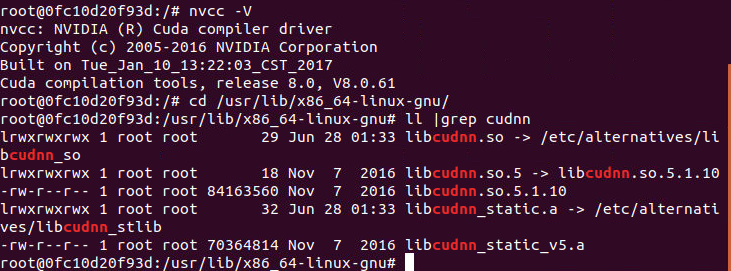
nvidia-smi
nvcc -V
# 查看cudnn版本
cd /usr/lib/x86_64-linux-gnu/
ll |grep cudnn12345
IV. 构建环境
安装环境
在上一部分我们搭建了深度学习计算的必要环境,包括CUDA和CUDNN。然而大多数深度学习环境都是需要执行Python编写的深度学习代码的,甚至需要一些常用的深度学习框架,如TensorFlow、PyTorch等。在上一部分我们拉取的Nvidia官方提供的镜像中并没有包含Python运行环境以及任何的深度学习框架,需要我们自己安装。
附上安装环境的所有命令:
apt-get update
# 安装Python2.7环境 3.+版本自行添加
apt-get install -y --no-install-recommends build-essential curl libfreetype6-dev libpng12-dev libzmq3-dev pkg-config python python-dev python-pip python-qt4 python-tk git vim
apt-get clean
## 安装深度学习框架 自行添加
pip --no-cache-dir install setuptools
pip --no-cache-dir install tensorflow-gpu==1.2 opencv-python Pillow scikit-image matplotlib1234567
构建镜像
安装好环境后,其实已经可以开始运行我们的深度学习代码了。如果你想立刻测试自己的Docker深度学习环境搭建成功与否,可以直接开始下一部分的Mnist数据集测试。
如果此时,项目组另一位小伙伴也想跑深度学习,恰好需要和你一样的环境依赖,我们完全可以“拷贝”一份配好的环境给他,他可以直接上手去使用。Docker的方便之处也体现在这,我们可以将自己定制的容器构建成镜像,可以上传到Docker Hub给别人下载,也可以生成压缩包拷贝给别人。
利用commit命令,生成一个名为homography1.0的新镜像。
# docker commit -a "作者信息" -m "提交信息" 之前启动的容器名 自定义镜像名
docker commit -a "wangguoping" -m "deep homography environment" tensorflow1.2 homography1.012
至于将镜像提交Hub和拷贝就不是本文重点,也就不介绍了。
另外,这里生成镜像还有一个好处,就是第六部分结合PyCharm使用。PyCharm里面配Docker选择的是镜像(IMAGE),而不是容器(Container),它会根据我们选择的镜像自己帮我们启动一个容器,用来运行PyCharm里面的代码。我一开始没有搞清楚这个概念,也走了不少弯路。
V. 测试Mnist
进入上一部分挂载的目录:
cd /home/test/mnist # test是我的用户名
vim mnist.py # 创建mnist的tensorflow代码12
代码内容可以参考:Tensorflow——nn、cnn、rnn玩mnist
# coding=utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
train_img = mnist.train.images
train_lab = mnist.train.labels
test_img = mnist.test.images
test_lab = mnist.test.labels
dim_input = 784
dim_output = 10
x_data = tf.placeholder(tf.float32, [None, dim_input])
y_real = tf.placeholder(tf.float32, [None, dim_output])
stddev = 0.1
weights = {"w_conv1": tf.Variable(tf.random_normal([3, 3, 1, 64], stddev=stddev)),
"w_conv2": tf.Variable(tf.random_normal([3, 3, 64, 128], stddev=stddev)),
"w_fc1": tf.Variable(tf.random_normal([7 * 7 * 128, 1024], stddev=stddev)),
"w_fc2": tf.Variable(tf.random_normal([1024, dim_output], stddev=stddev))}
biases = {"b_conv1": tf.Variable(tf.zeros([64])),
"b_conv2": tf.Variable(tf.zeros([128])),
"b_fc1": tf.Variable(tf.zeros([1024])),
"b_fc2": tf.Variable(tf.zeros([dim_output]))}
def forward_prop(_input, _w, _b, keep_prob):
_input_r = tf.reshape(_input, shape=[-1, 28, 28, 1])
_conv1 = tf.nn.conv2d(_input_r, _w["w_conv1"], strides=[1, 1, 1, 1], padding="SAME")
_conv1 = tf.nn.relu(tf.nn.bias_add(_conv1, _b["b_conv1"]))
_pool1 = tf.nn.max_pool(_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# dropout
_pool_dr1 = tf.nn.dropout(_pool1, keep_prob=keep_prob)
_conv2 = tf.nn.conv2d(_pool_dr1, _w["w_conv2"], strides=[1, 1, 1, 1], padding="SAME")
_conv2 = tf.nn.relu(tf.nn.bias_add(_conv2, _b["b_conv2"]))
_pool2 = tf.nn.max_pool(_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
_pool_dr2 = tf.nn.dropout(_pool2, keep_prob=keep_prob)
flatten = tf.reshape(_pool_dr2, shape=[-1, _w["w_fc1"].get_shape().as_list()[0]])
_fc1 = tf.nn.relu(tf.add(tf.matmul(flatten, _w["w_fc1"]), _b["b_fc1"]))
_fc_dr1 = tf.nn.dropout(_fc1, keep_prob=keep_prob)
_out = tf.nn.relu(tf.add(tf.matmul(_fc_dr1, _w["w_fc2"]), _b["b_fc2"]))
return {"input_r": _input_r, "conv1": _conv1, "pool1": _pool1, "pool_dr1": _pool_dr1, "conv2": _conv2,
"pool2": _pool2, "pool_dr2": _pool_dr2, "flatten": flatten, "fc1": _fc1, "fc_dr1": _fc_dr1, "out": _out}
keep_prob = tf.placeholder(tf.float32)
y_pred = forward_prop(x_data, weights, biases, keep_prob)["out"]
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_pred, labels=y_real))
op = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
correct = tf.equal(tf.arg_max(y_pred, 1), tf.arg_max(y_real, 1))
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
training_epoch = 100
batch_size = 128
display_step = 2
init = tf.global_variables_initializer()
total_batch = mnist.train.num_examples // batch_size
print("have %d batchs,each batch size is:%d" % (total_batch, batch_size))
saver = tf.train.Saver(max_to_keep=2)
is_training = True
with tf.Session() as sess:
sess.run(init)
if is_training:
for epoch in range(training_epoch):
avg_loss = 0
for i_batch in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
feed_dict = {x_data: batch_xs, y_real: batch_ys, keep_prob: 0.5}
sess.run(op, feed_dict=feed_dict)
avg_loss += sess.run(loss, feed_dict=feed_dict)
avg_loss = avg_loss / total_batch
if epoch % display_step == 0:
print("Epoch:%3d/%3d, loss:%.6f" % (epoch, training_epoch, avg_loss))
feed_dict = {x_data: batch_xs, y_real: batch_ys, keep_prob: 0.5}
train_accuracy = sess.run(accuracy, feed_dict=feed_dict)
print("train accuracy:%.6f" % train_accuracy)
saver.save(sess, "MNIST_model/model.ckpt-" + str(epoch))
else:
saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir="MNIST_model/"))
feed_dict = {x_data: mnist.test.images, y_real: mnist.test.labels, keep_prob: 1.0}
test_accuracy = sess.run(accuracy, feed_dict=feed_dict)
print("test accuracy:%.6f" % test_accuracy)
print("end!")
下载Mnist数据集,保存在/home/test/mnist/MNIST_data目录下。这里需要我们修改目录权限,Docker共享目录默认只读。注意,这里切换到宿主机的终端下进行操作,可能你会问为什么不直接容器内下载,因为以后我们要跑的数据集不可能只是mnist大小,难道你要在docker里下载几十个G的数据集吗。
sudo chmod -R a+rw /home/test/mnist
mkdir -p /home/test/mnist/MNIST_data
wget http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
wget http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
wget http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
wget http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz123456
切换至Docker的终端下,运行mnist.py脚本文件,即可发现已经可以跑起来了。
python mnist.py1
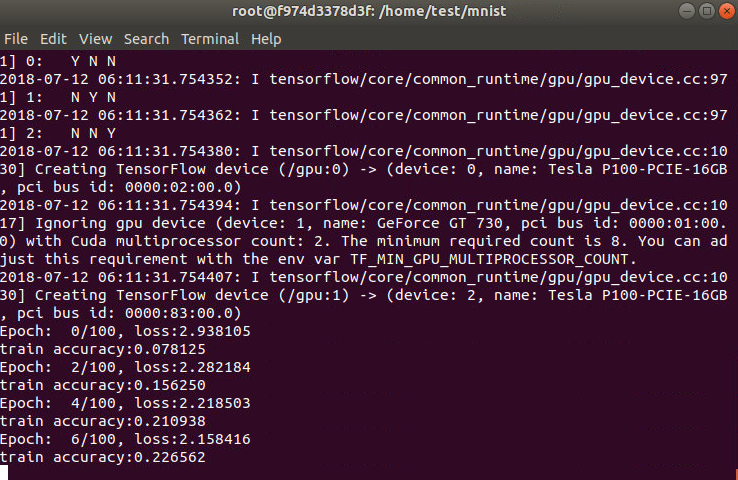
此时会在/home/test/mnist下产生MNSIT_model文件夹,里面保存着训练生成的模型。
VI. PyCharm+Docker
Mnist已经测试成功,基本的Docker+Deep Learning方案演示已经完成。然而,我一直不喜欢命令行修改代码,运行脚本,查看结果,我十分推崇PyCharm去调试Python。比如,当Mnist训练完毕,我需要修改第80行的is_training = False来测试我训练出的模型,没有PyCharm,我需要通过vim修改mnist.py,然后再输入python来运行。可能你会觉得也不是很麻烦,如果需要修改模型,更换网络,甚至重构代码呢?
所以能用IDE尽量还是让PyCharm来开发我们代码,我们只需要编码,点击运行,剩下的其他操作我都不太愿意去干,一行命令都懒得敲,毕竟懒嘛!
PyCharm在2018的Profession版本之后都是提供Docker的功能的,可以利用容器中的Python解释器为我们的代码提供运行条件。利用PyCharm,你可以像在使用本机的深度学习环境一样,无需考虑因容器带来的过多的繁琐操作。官方关于Docker的使用文档参见:http://www.jetbrains.com/help/pycharm/run-debug-configuration-docker.html
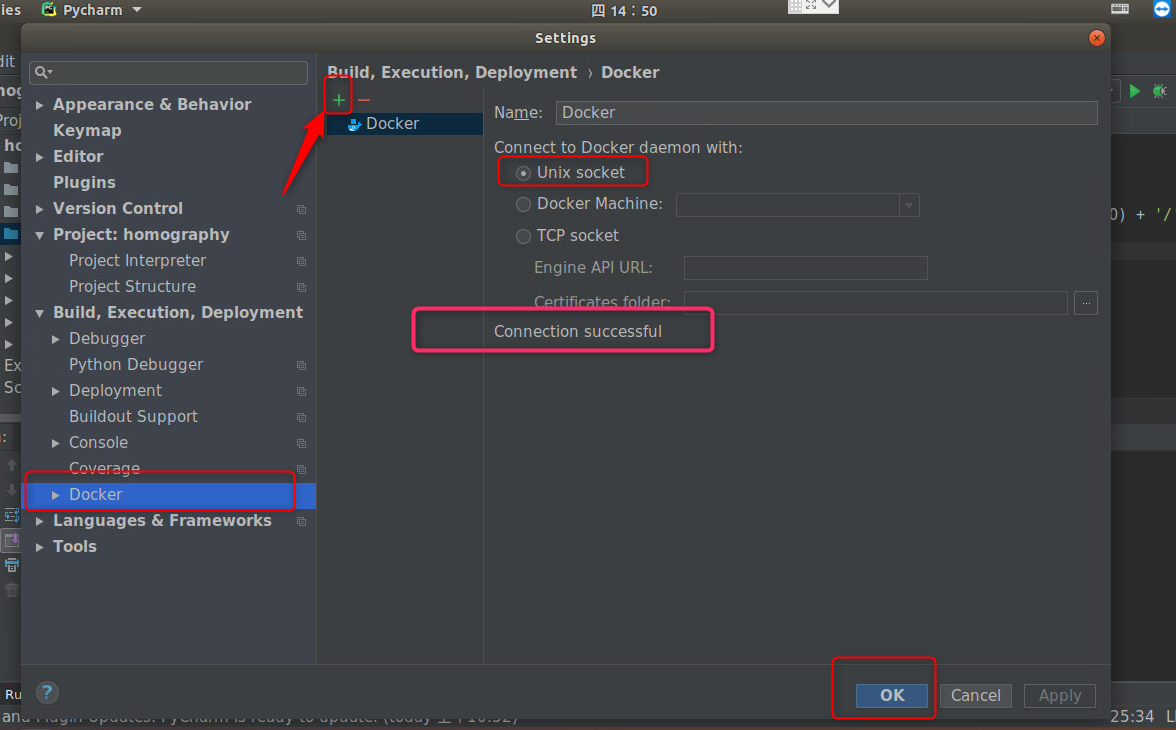
在Settings的Build下有一个Docker选项,右侧添加,PyCharm默认会给我们设置好选择Unix Socket的方式与Docker守护进程进行通信。出现Connection successful即可,点击OK。
添加成功后,PyCharm下方会出现docker的窗口,可以可视化的查看镜像与容器的相关信息。其中的homography1.0:latsest是我们上一步构建的镜像。
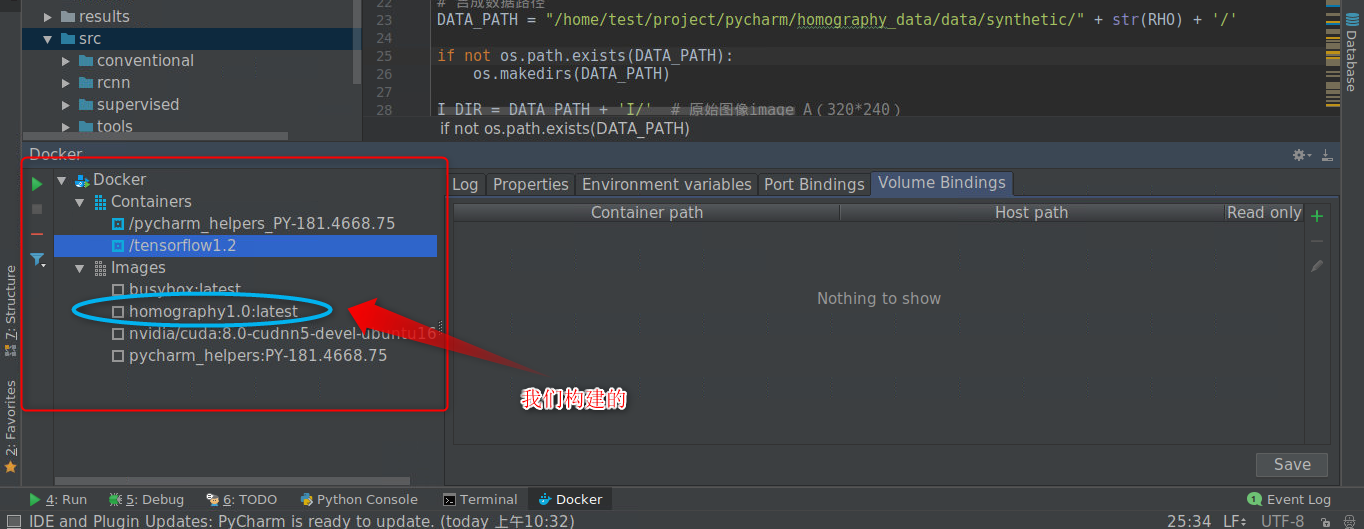
下面新建一个Python的解释器,类似于本地的Python创建虚拟环境。
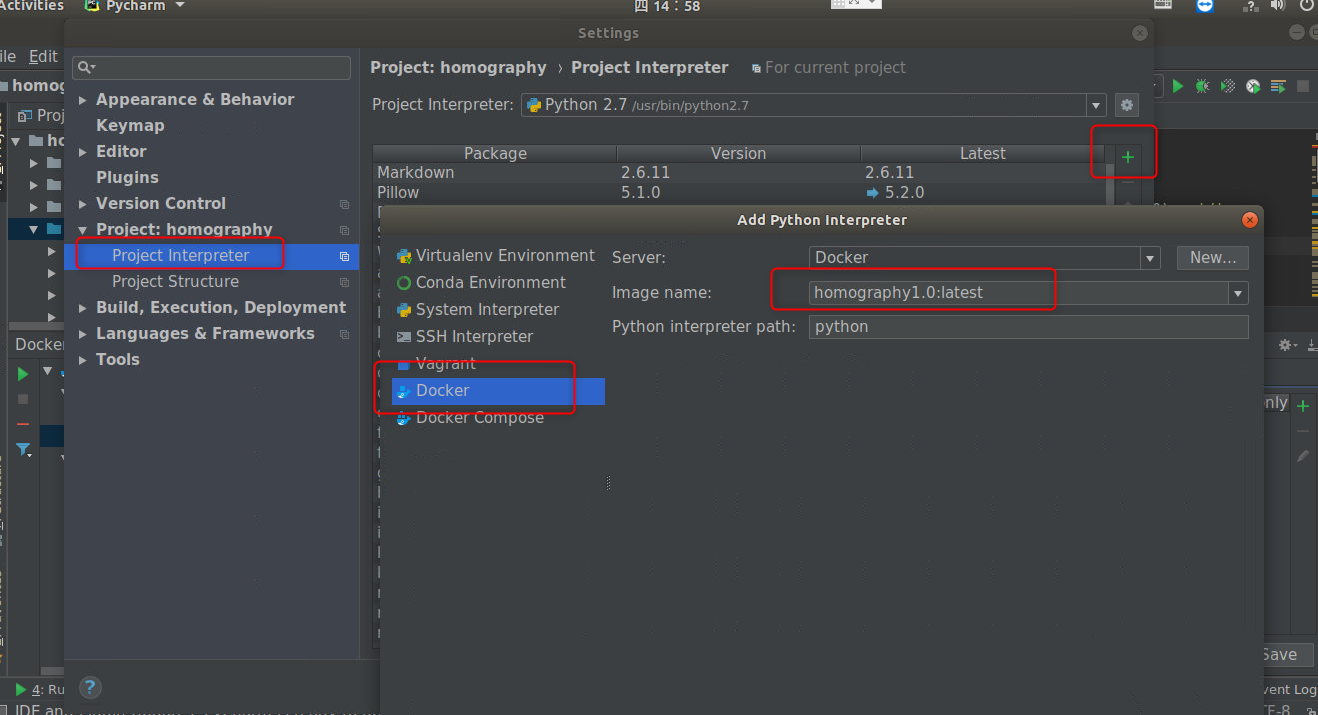
按照图示新建,点击OK,即可发现导入容器的Python解释器已经拥有了全部的第三方Python库以及深度学习框架。
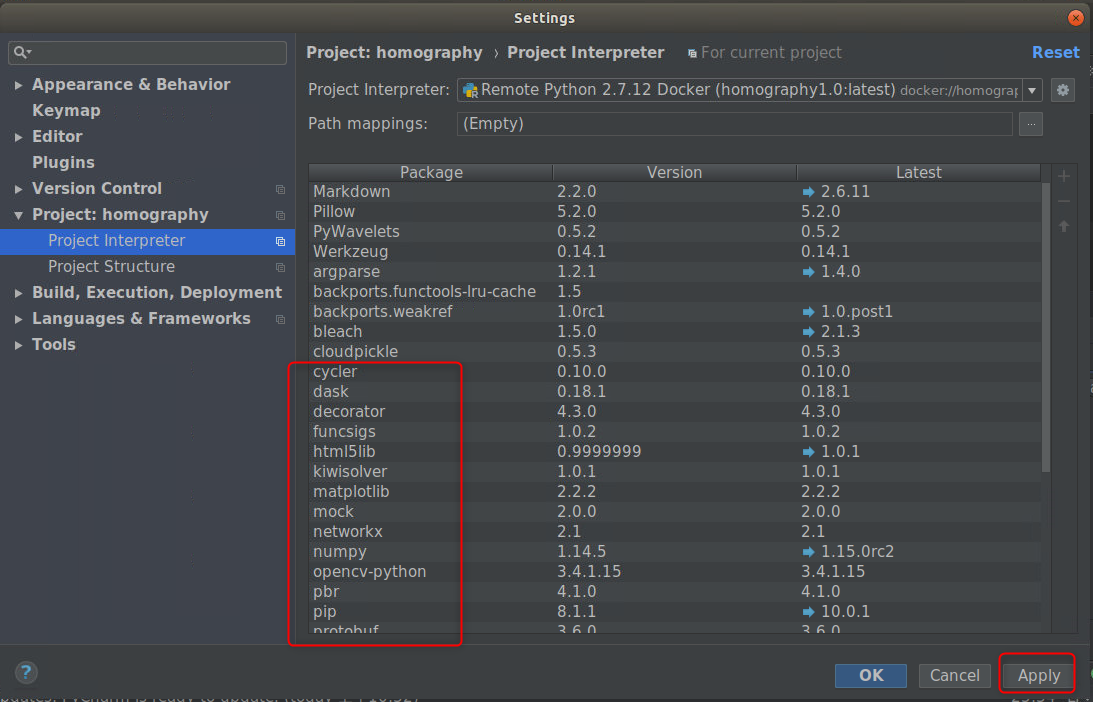
等待PyCharm导入容器的解释器成功,理论上我们便可以开始点击运行按钮跑起我们的代码了。但实际还有两个问题需要解决。
首先,PyCharm会根据我们的镜像来启动一个容器运行我们的代码,然而PyCharm并不知道我们是要运行深度学习程序,需要利用Nvidia Docker使用GPU资源。我们之前是通过配置–runtime=nvidia参数来启动一个可以使用GPU的容器,那我们只要指定PyCharm启动一个容器的时候也带上这个参数就好。
另一个问题就是,我们现在跑的程序是读取宿主机上某个目录下的几十个G的数据集,好像Docker也不知道数据在哪里,毕竟我们没有挂载。同样,模型它也不会帮我们保存,一旦程序运行结束,PyCharm启动的容器销毁,所有的结果都没了,程序白跑了,所以我们也要指定-v参数告诉PyCharm挂载什么目录。
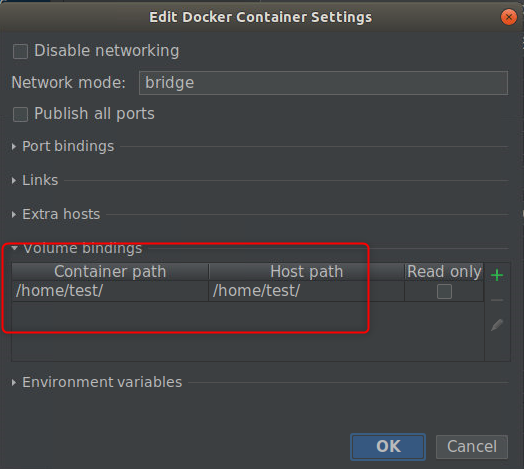
解决这两个问题,在PyCharm的Run/Debug Configuration中,可以配置。
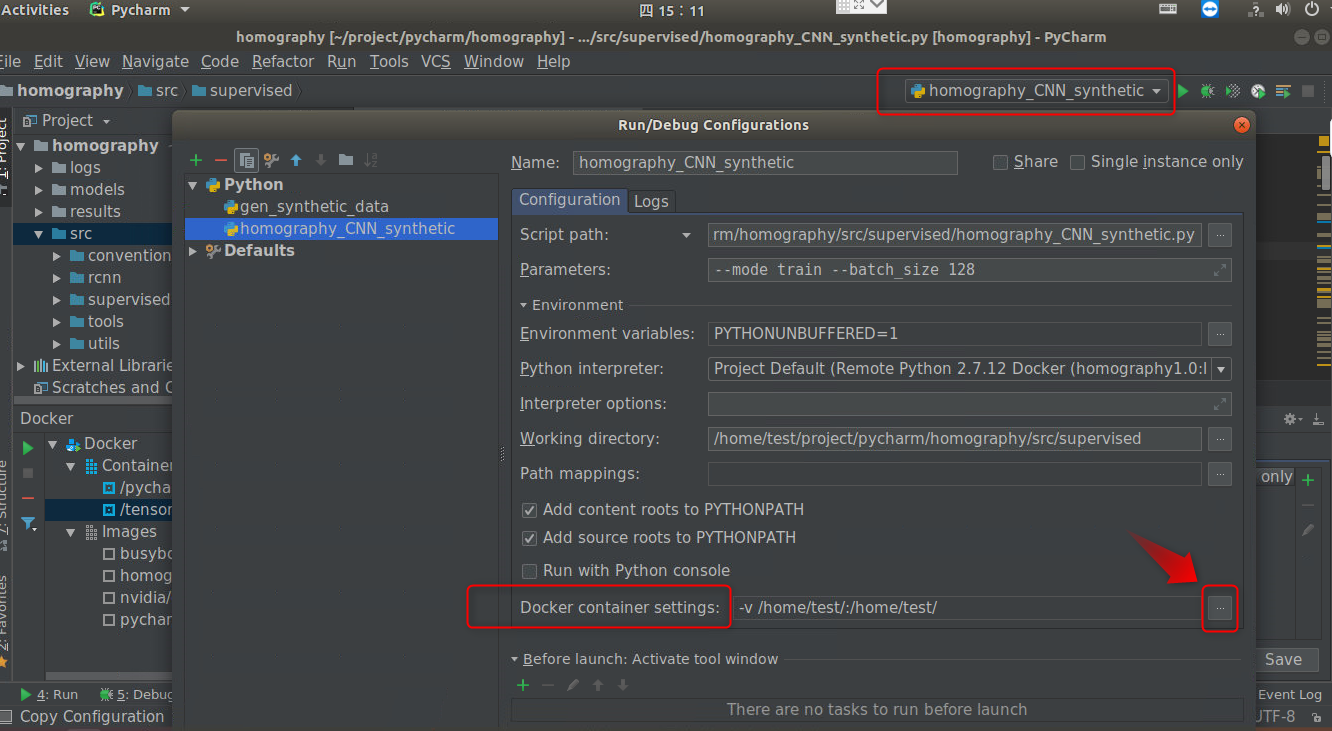
点击Docker Container settings右边的按钮,添加上面所说的两个参数即可。
坑的是,你发现没法加入–runtime参数。然而,还是找到了解决方案。把default-runtime”: “nvidia”添加到/etc/docker/daemon.json文件中。这个文件也是我们配置国内镜像加速的文件。
{
"registry-mirrors": [
"https://registry.docker-cn.com"
],
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}123456789101112
修改完毕,需要重启docker服务。
sudo systemctl daemon-reload
sudo systemctl restart docker12
好了,大功告成,点击运行,跑起来~~
VII. 结语
Docker还是有很多技巧的,短暂几天也只学了个皮毛,用于深度学习也十分不错。官方也有很多构建好的深度学习环境镜像,包含了主流的深度学习框架,可以再Docker Hub自行搜索。实验室电脑有时候还是很奇葩的,需要耐心解决,积极的去利用一些新的技术解决难题应该是更应该考虑的事情。
