

亚马逊S3简单介绍
Amazon S3介绍
Amazon Simple Storage Service (Amazon S3) 是一种对象存储,它具有简单的 Web 服务接口,可用于在 Web 上的任何位置存储和检索任意数量的数据。它能够提供 99.999999999% 的持久性,并且可以在全球大规模传递数万亿对象。
S3的基本数据结构
S3的数据存储结构非常简单,就是一个扁平化的两层结构:一层是存储桶(Bucket,又称存储段),另一层是存储对象(Object,又称数据元)。存储桶是S3中用来归类数据的一个方式,它是数据存储的容器。每一个存储对象都需要存储在某一个存储桶中。存储桶是S3命名空间的最高层,它会成为用户访问数据的域名的一部分,因此存储桶的名字必须是唯一的,而且需要保持DNS兼容,比如采用小写、不能用特殊字符等。例如,你创建了一个名为:zhangsan的存储桶,那么对应的域名就是zhangsan.s3.amazonaws.com,以后你可以通过http://zhangsan.s3.amazonaws.com/来访问其中存储的数据。由于数据存储的地理位置有时对用户来说挺重要,因此在创建存储桶的时候S3会提示选择区域(Region)信息。存储对象就是用户实际要存储的内容,其构成就是对象数据内容再加上一些元数据信息。这里的对象数据通常是一个文件,而元数据就是描述对象数据的信息,比如数据修改的时间等。如果你在zhangsan的存储桶中存放了一个文件picture.jpg,那么你可以通过http://zhangsan.s3.amazonaws.com/picture.jpg这个URL来访问这个文件。从这个URL访问我们可以看到,存储桶名称需要全球唯一,而存储对象的命名则需要在存储桶中唯一。只有这样你才能通过一个全球唯一的URL访问到你指定的数据。S3的数据存储结构如下图所示:
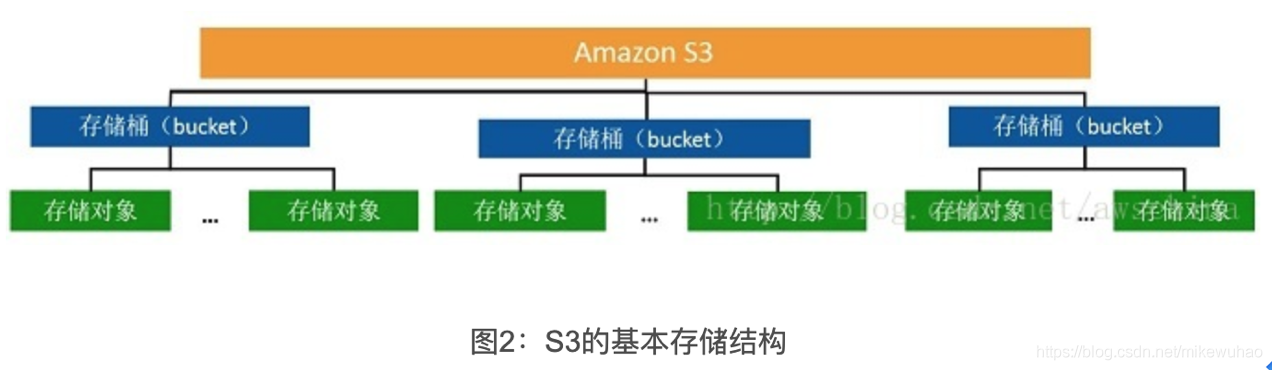
S3存储对象中的数据大小可以从1个字节到5TB。在缺省情况下每个AWS账号最多能创建100个存储桶。不过用户可以在一个存储桶中存放任意多存储对象。理论上存储桶中的对象数是没有限制的,因为S3完全是按照分布式存储方式设计。除了在容量上S3具有很到的扩展性,S3的性能上也具有高度扩展性,允许多个客户端和应用线程并发访问数据。
可能有人会把S3的存储结构与一般的文件系统进行比较,要注意的是S3在架构上只有两层结构,并不支持多层次的树形目录结构。不过你可以通过设计带“/”的存储对象名称来模拟出一个树形结构来。例如有些S3工具就提供了一个操作选项是“创建文件夹”,其实际上就是通过控制存储对象的名称来实现的。
S3的几个特点
作为云存储的典型代表,Amazon S3在扩展性、持久性和性能等几个方面有自己明显的特点。
耐久性和可用性, 弹性和可扩展性, 良好的性能, 接口简单
官网地址 https://docs.aws.amazon.com/zh_cn/AmazonS3/latest/userguide/Welcome.html

