解决:pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it‘s not in your PATH. See README file for more information.
问题:使用pytesseract库识别图片中文字时出现报错

代码:
import pytesseract from PIL import Image,ImageEnhance img=Image.open(r'F:\Test\venv\vfi_code.png') #修改图片的灰度,提高识别准确性 img=img.convert('RGB') enhancer=ImageEnhance.Color(img) enhancer=enhancer.enhance(0) enhancer=ImageEnhance.Brightness(enhancer) enhancer=enhancer.enhance(2) enhancer=ImageEnhance.Contrast(enhancer) enhancer=enhancer.enhance(8) enhancer=ImageEnhance.Sharpness(enhancer) img=enhancer.enhance(20) code=pytesseract.image_to_string(img,lang='chi_sim') print(code)
原因:在安装pytesseract库后还需要安装Tesseract-OCR才能正常使用
解决办法:
1)先下载对应版本的Tesseract-OCR并安装,安装时记得把语言包都勾上。下载链接:Index of /tesseract
没有勾选语言包会有这个报错:
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:\\Program Files\\Tesseract-OCR/tessdata/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
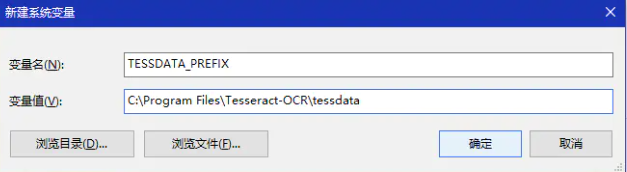
2)将安装路径C:\Program Files\Tesseract-OCR 添加到系统环境变量Path里;再增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径C:\Program Files\Tesseract-OCR\tessdata这是将语言字库文件夹添加到变量中;
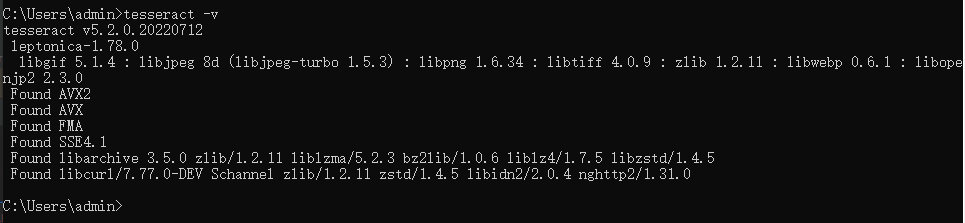
3)打开终端,输入:tesseract -v,可以看到版本信息
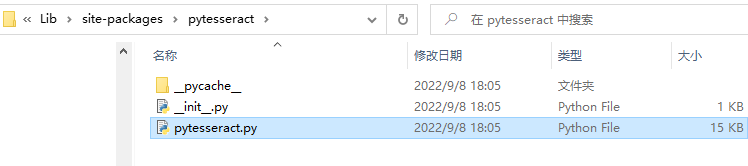
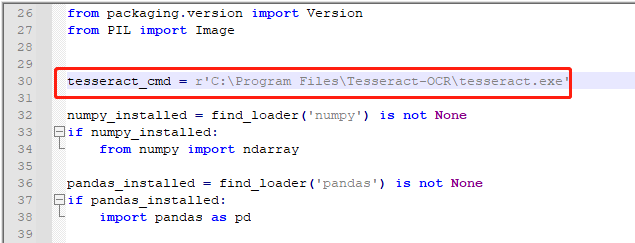
4)在pytesseract库下的pytesseract.py文件中找到tesseract_cmd = 'tesseract',修改成 tesseract_cmd =r'C:\Program Files\Tesseract-OCR\tesseract.exe'