

如何处理动态变化的xpath id?
最近学习python+selenium实现自动登录,在获取xpath后使用 driver.find_element_by_xpath定位元素出错了
初始代码:

from selenium import webdriver from selenium.webdriver.chrome.options import Options import time,ddddocr from PIL import Image driver=webdriver.Chrome() def get_img_code(): driver.get('http://192.168.11.55:12345/#/login') driver.find_element_by_xpath('//*[@id="el-id-4208-4"]').clear() #copy的xpth包含一些随机数字,每次页面加载时都会更改,选择copy full xpth可以解决 driver.find_element_by_xpath('//*[@id="el-id-4208-4"]').send_keys('username') driver.find_element_by_xpath('//*[@id="el-id-4208-5"]').clear() driver.find_element_by_xpath('//*[@id="el-id-4208-5"]').send_keys('password') driver.find_element_by_xpath('//*[@id="el-id-4208-6"]').clear() driver.find_element_by_xpath('//*[@id="el-id-4208-6"]').send_keys('vficode') time.sleep(3) driver.find_element_by_xpath('//*[@id="userLayout"]/div/div[1]/form/div[4]/div/button[2]/span').click() if __name__ == '__main__': get_img_code()
报错截图:

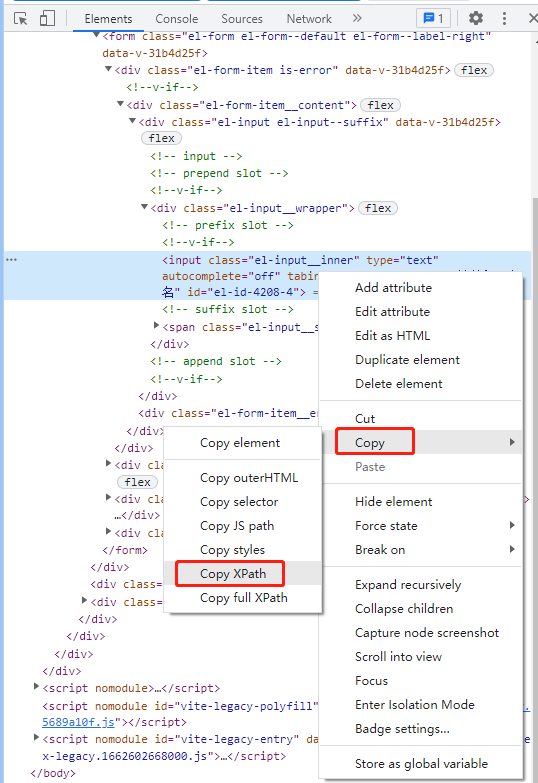
首先,看看我是如何获取xpath的,之前按照网上网友教的一个方法可以快速获取到HTML网页元素的xpath,以获得登录输入框的xpath为例,具体操作步骤如下图:

打开网页后按F12--> 点击箭头1处图标--> 在网页中点击需要获取xpath的元素位置(如箭头2)--> web源码就会自动定位到该元素(如箭头3),然后右键选择Copy-->Copy XPath,即可获得该元素的XPath地址了(例如我获取到的就是://*[@id="el-id-4208-4"])
解决方案:
1)一般使用上述方法获取xpath地址是没问题的,但是我这个网页的xpth包含一些随机数字,每次页面加载时都会更改,选择copy full xpth可以解决(例如我获取到的就是:/html/body/div/div/div/div/div[1]/form/div[1]/div/div[1]/div/input)
from selenium import webdriver from selenium.webdriver.chrome.options import Options import time,ddddocr from PIL import Image driver=webdriver.Chrome() def get_img_code(): driver.get('http://192.168.11.55:12345/#/login') driver.find_element_by_xpath('/html/body/div/div/div/div/div[1]/form/div[1]/div/div[1]/div/input').clear() #copy的xpth包含一些随机数字,每次页面加载时都会更改,选择copy full xpth可以解决 driver.find_element_by_xpath('/html/body/div/div/div/div/div[1]/form/div[1]/div/div[1]/div/input').send_keys('username') driver.find_element_by_xpath('/html/body/div/div/div/div/div[1]/form/div[2]/div/div[1]/div/input').clear() driver.find_element_by_xpath('/html/body/div/div/div/div/div[1]/form/div[2]/div/div[1]/div/input').send_keys('password') driver.find_element_by_xpath('/html/body/div/div/div/div/div[1]/form/div[3]/div/div[1]/div[1]/div/input').clear() driver.find_element_by_xpath('/html/body/div/div/div/div/div[1]/form/div[3]/div/div[1]/div[1]/div/input').send_keys('vficode') time.sleep(3) driver.find_element_by_xpath('//*[@id="userLayout"]/div/div[1]/form/div[4]/div/button[2]/span').click() if __name__ == '__main__': get_img_code()
2)但是full xpath未免太长了,向身边的同事请教后获得了另一种获取xpath的方法,由于该元素的id每次打开页面时会随机变化,可以用标签层级来定位xpath,取到的xpath就是://input[@type="text"],有些相同标签的情况下就要继续往上层取
from selenium import webdriver from selenium.webdriver.chrome.options import Options import time,ddddocr from PIL import Image driver=webdriver.Chrome() def get_img_code(): driver.get('http://192.168.11.55:12345/#/login') driver.find_element_by_xpath('//input[@type="text"]').clear() #copy的xpth包含一些随机数字,每次页面加载时都会更改,选择copy full xpth可以解决 driver.find_element_by_xpath('//input[@type="text"]').send_keys('username') driver.find_element_by_xpath('//input[@type="password"]').clear() driver.find_element_by_xpath('//input[@type="password"]').send_keys('password') driver.find_element_by_xpath('//div[@class="vPicBox"]/div/div/input[@type="text"]').clear() driver.find_element_by_xpath('//div[@class="vPicBox"]/div/div/input[@type="text"]').send_keys('vficode') time.sleep(3) driver.find_element_by_xpath('//*[@id="userLayout"]/div/div[1]/form/div[4]/div/button[2]/span').click() if __name__ == '__main__': get_img_code()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~