


Json-Tutorial04 Unicode解析
前言
本节实际上做的工作是上一节的遗留工作:\u转义字符的解析。
UTF-8的解析规则
在本教程所设计的Json库中,只涉及UTF-8的解析。具体的解析规则教程中都已经说的非常清楚了,这里就不再赘述。值得注意的是包含高代理项和低代理项的情况。为什么会有高代理项和低代理项呢?因为咱们的unicode字符\uxxxx是一个4位的16进制数,而unicode的码点范围是0至0x10FFFF,显然一个unicode字符是无法表示所有的码点范围的。所以我们使用高代理项和低代理项两个unicode字符\uXXXX\uYYYY来表示U+FFFF以上的码点。具体计算的过程见Tutorial。写代码的时候,在解析完第一个unicode字符时,也需要注意下一个字符是不是unicode,如果是的话,需要按照高低代理项的计算规则一起计算出码点解析。
代码设计
1. 实现 lept_parse_hex4(),不合法的十六进位数返回 LEPT_PARSE_INVALID_UNICODE_HEX
这个函数只应负责解析4位的16进制数,如果后面还有字符,不用管,等下一次循环会解析。所以,我们只需要挨个解析4个字符就可以。如果遇到不是16进制的字符,直接返回NULL,表示解析失败。
static const char* lept_parse_hex4(const char* p, unsigned* u) {
*u = 0;
int i;
for (i = 0; i < 4; i++) {
switch (*p++) {
case '0':
*u = (*u << 4) | 0x0; break;
case '1':
*u = (*u << 4) | 0x1; break;
case '2':
*u = (*u << 4) | 0x2; break;
case '3':
*u = (*u << 4) | 0x3; break;
case '4':
*u = (*u << 4) | 0x4; break;
case '5':
*u = (*u << 4) | 0x5; break;
case '6':
*u = (*u << 4) | 0x6; break;
case '7':
*u = (*u << 4) | 0x7; break;
case '8':
*u = (*u << 4) | 0x8; break;
case '9':
*u = (*u << 4) | 0x9; break;
case 'A':
case 'a':
*u = (*u << 4) | 0xA; break;
case 'B':
case 'b':
*u = (*u << 4) | 0xB; break;
case 'C':
case 'c':
*u = (*u << 4) | 0xC; break;
case 'D':
case 'd':
*u = (*u << 4) | 0xD; break;
case 'E':
case 'e':
*u = (*u << 4) | 0xE; break;
case 'F':
case 'f':
*u = (*u << 4) | 0xF; break;
default:
return NULL;
}
}
return p;
}
我这个是比较笨的版本,简洁明了的版本请移步tutorial。
2. 按第 3 节谈到的 UTF-8 编码原理,实现 lept_encode_utf8()
static void lept_encode_utf8(lept_context* c, unsigned u) {
if (u <= 0x7F) {
PUTC(c, u & 0x7F);
} else if (u <= 0x7FF) {
PUTC(c, 0xC0 | ((u >> 6) & 0x1F));
PUTC(c, 0x80 | (u & 0x3F));
} else if (u <= 0xFFFF) {
PUTC(c, 0xE0 | ((u >> 12) & 0xF));
PUTC(c, 0x80 | ((u >> 6) & 0x3F));
PUTC(c, 0x80 | (u & 0x3F));
} else {
assert(u <= 0x10FFFF);
PUTC(c, 0xF0 | ((u >> 18) & 0x7));
PUTC(c, 0x80 | ((u >> 12) & 0x3F));
PUTC(c, 0x80 | ((u >> 6) & 0x3F));
PUTC(c, 0x80 | (u & 0x3F));
}
}
这里u是无符号数右移,左边最高位会补0,所以不需要像tutorial中把所有位都&上一遍1。其他的步骤就都跟UTF-8的编码完全吻合了。
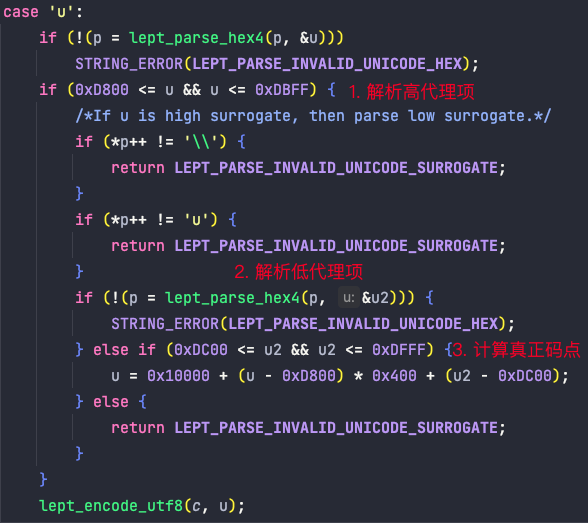
3. 加入对代理对的处理,不正确的代理对范围要返回 LEPT_PARSE_INVALID_UNICODE_SURROGATE 错误
当我们解析出来的码点在0xDC00和0xDFFF之间时,说明这只是一个高代理项,还需要后面的一个低代理项才能计算出来真正的码点。
分类:
Json解析库实现


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix