
一文搞懂InnoDB索引存储结构
参考资料:掘金小册:MySQL 是怎样运行的:从根儿上理解 MySQL
B+树
我们知道,InnoDB是用B+树作为组织数据形式的数据结构。不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把它们存放到B+树这个数据结构中了,所以我们也称这些数据页为节点。从图中可以看出来,我们的实际用户记录其实都存放在B+树的最底层的节点上,这些节点也被称为叶子节点或叶节点,其余用来存放目录项的节点称为非叶子节点或者内节点,其中B+树最上边的那个节点也称为根节点。
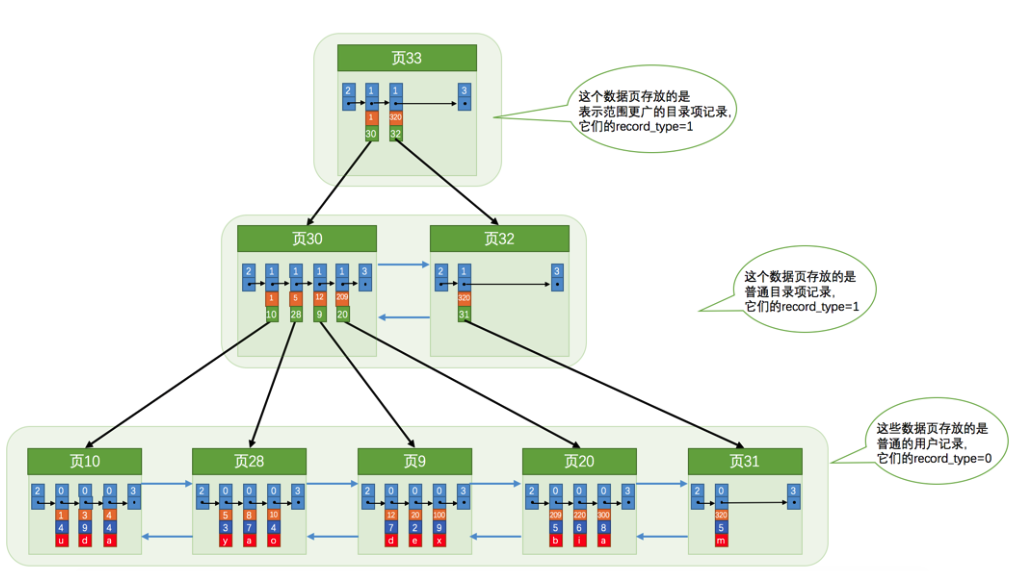
从图中可以看出来,一个B+树的节点其实可以分成好多层,设计InnoDB的大叔们为了讨论方便,规定最下边的那层,也就是存放我们用户记录的那层为第0层,之后依次往上加。之前的讨论我们做了一个非常极端的假设:存放用户记录的页最多存放3条记录,存放目录项记录的页最多存放4条记录。其实真实环境中一个页存放的记录数量是非常大的,假设,假设,假设所有存放用户记录的叶子节点代表的数据页可以存放100条用户记录,所有存放目录项记录的内节点代表的数据页可以存放1000条目录项记录,那么:
- 如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放100条记录。
- 如果B+树有2层,最多能存放
1000×100=100000条记录。 - 如果B+树有3层,最多能存放
1000×1000×100=100000000条记录。 - 如果B+树有4层,最多能存放
1000×1000×1000×100=100000000000条记录。哇咔咔~这么多的记录!!!
你的表里能存放100000000000条记录么?所以一般情况下,我们用到的B+树都不会超过4层,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有所谓的Page Directory(页目录),所以在页面内也可以通过二分法实现快速定位记录,这不是很牛么,哈哈!
聚簇索引
我们上边介绍的B+树本身就是一个目录,或者说本身就是一个索引。它有两个特点:
- 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
- 页内的记录是按照主键的大小顺序排成一个单向链表。
- 各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
- B+树的叶子节点存储的是完整的用户记录。所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的使用INDEX语句去创建(后边会介绍索引相关的语句),InnoDB存储引擎会自动的为我们创建聚簇索引。另外有趣的一点是,在InnoDB存储引擎中,聚簇索引就是数据的存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索引即数据,数据即索引。
二级索引
大家有木有发现,上边介绍的聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。那如果我们想以别的列作为搜索条件该咋办呢?难道只能从头到尾沿着链表依次遍历记录么?
不,我们可以多建几棵B+树,不同的B+树中的数据采用不同的排序规则。比方说我们用c2列的大小作为数据页、页中记录的排序规则,再建一棵B+树,效果如下图所示:
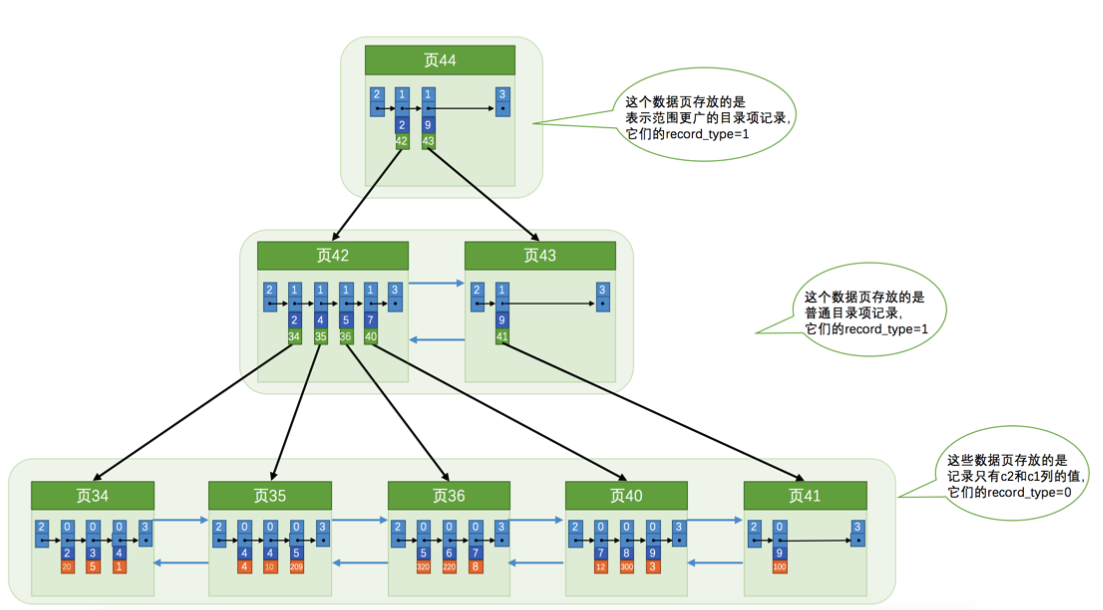
这个B+树与上边介绍的聚簇索引有几处不同:
- 使用记录
c2列的大小进行记录和页的排序,这包括三个方面的含义:- 页内的记录是按照
c2列的大小顺序排成一个单向链表。 - 各个存放用户记录的页也是根据页中记录的
c2列大小顺序排成一个双向链表。 - 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的
c2列大小顺序排成一个双向链表。
- 页内的记录是按照
- B+树的叶子节点存储的并不是完整的用户记录,而只是
c2列+主键这两个列的值。 - 目录项记录中不再是
主键+页号的搭配,而变成了c2列+页号的搭配。
所以如果我们现在想通过c2列的值查找某些记录的话就可以使用我们刚刚建好的这个B+树了。以查找c2列的值为4的记录为例,查找过程如下:
- 确定
目录项记录页。根据根页面,也就是页44,可以快速定位到目录项记录所在的页为页42(因为2 < 4 < 9)。 - 通过目录项记录页确定用户记录真实所在的页。在页42中可以快速定位到实际存储用户记录的页,但是由于c2列并没有唯一性约束,所以c2列值为4的记录可能分布在多个数据页中,又因为2 < 4 ≤ 4,所以确定实际存储用户记录的页在页34和页35中。
- 在真实存储用户记录的页中定位到具体的记录。到
页34和页35中定位到具体的记录。 - 但是这个B+树的叶子节点中的记录只存储了
c2和c1(也就是主键)两个列,所以我们必须再根据主键值去聚簇索引中再查找一遍完整的用户记录,这个过程被称为回表。
为什么我们还需要一次回表操作呢?直接把完整的用户记录放到叶子节点不就好了么?你说的对,如果把完整的用户记录放到叶子节点是可以不用回表,但是太占地方了呀~相当于每建立一棵B+树都需要把所有的用户记录再都拷贝一遍,这就有点太浪费存储空间了。因为这种按照非主键列建立的B+树需要一次回表操作才可以定位到完整的用户记录,所以这种B+树也被称为二级索引(英文名secondary index),或者辅助索引。由于我们使用的是c2列的大小作为B+树的排序规则,所以我们也称这个B+树为为c2列建立的索引。
联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照c2和c3列的大小进行排序,这个包含两层含义:
- 先把各个记录和页按照c2列进行排序。
- 在记录的c2列相同的情况下,采用c3列进行排序。
为c2和c3列建立的索引的示意图如下:
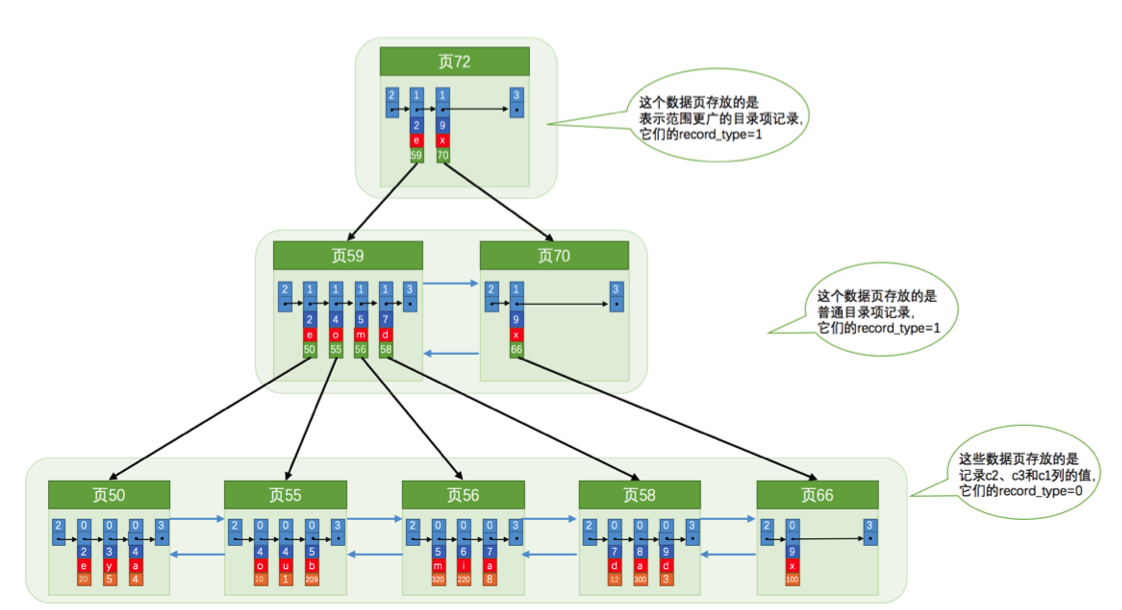
如图所示,我们需要注意一下几点:
- 每条目录项记录都由c2、c3、页号这三个部分组成,各条记录先按照c2列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序。
- B+树叶子节点处的用户记录由c2、c3和主键c1列组成。
千万要注意一点,以c2和c3列的大小为排序规则建立的B+树称为联合索引,本质上也是一个二级索引。它的意思与分别为c2和c3列分别建立索引的表述是不同的,不同点如下:
- 建立联合索引只会建立如上图一样的1棵B+树。
- 为c2和c3列分别建立索引会分别以c2和c3列的大小为排序规则建立2棵B+树。
覆盖索引
为了彻底告别回表操作带来的性能损耗,我们建议:最好在查询列表里只包含索引列,比如这样:
SELECT name, birthday, phone_number FROM person_info WHERE name > 'Asa' AND name < 'Barlow'
为我们只查询name, birthday, phone_number这三个索引列的值,所以在通过idx_name_birthday_phone_number的联合索引得到结果后就不必到聚簇索引中再查找记录的剩余列,也就是country列的值了,这样就省去了回表操作带来的性能损耗。我们把这种只需要用到索引的查询方式称为索引覆盖。
InnoDB的B+树索引的注意事项
根页面万年不动窝
我们前边介绍B+树索引的时候,为了大家理解上的方便,先把存储用户记录的叶子节点都画出来,然后接着画存储目录项记录的内节点,实际上B+树的形成过程是这样的:
-
每当为某个表创建一个B+树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个
根节点页面。最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录。 -
随后向表中插入用户记录时,先把用户记录存储到这个根节点中。
-
当
根节点中的可用空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如页b。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到页a或者页b中,而根节点便升级为存储目录项记录的页。
这个过程需要大家特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表建立一个索引,那么它的根节点的页号便会被记录到某个地方,然后凡是InnoDB存储引擎需要用到这个索引的时候,都会从那个固定的地方(数据字典)取出根节点的页号,从而来访问这个索引。
内节点中目录项记录的唯一性
我们知道B+树索引的内节点中目录项记录的内容是索引列 + 页号的搭配,但是这个搭配对于二级索引来说有点儿不严谨。拿下表为例:
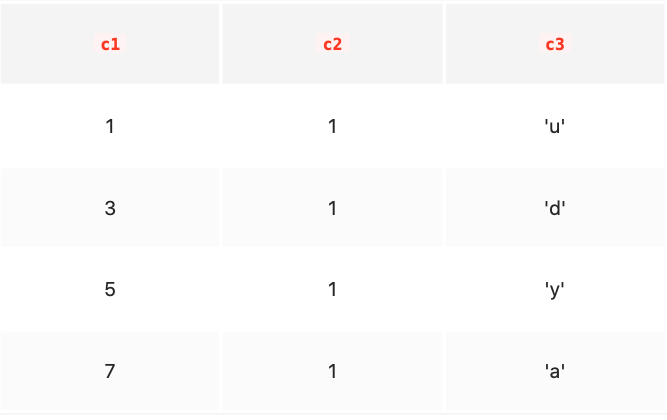
如果二级索引中目录项记录的内容只是索引列 + 页号的搭配的话,那么为c2列建立索引后的B+树应该长这样:
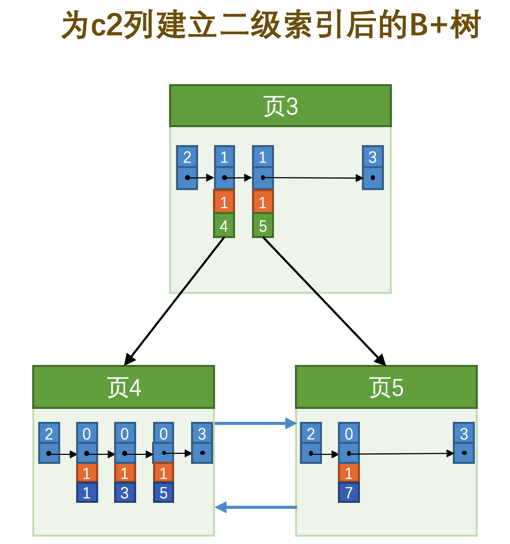
如果我们想新插入一行记录,其中c1、c2、c3的值分别是:9、1、'c',那么在修改这个为c2列建立的二级索引对应的B+树时便碰到了个大问题:由于页3中存储的目录项记录是由c2列 + 页号的值构成的,页3中的两条目录项记录对应的c2列的值都是1,而我们新插入的这条记录的c2列的值也是1,那我们这条新插入的记录到底应该放到页4中,还是应该放到页5中啊?答案是:对不起,懵逼了。
为了让新插入记录能找到自己在那个页里,我们需要保证在B+树的同一层内节点的目录项记录除页号这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的:
- 索引列的值
- 主键值
- 页号
也就是我们把主键值也添加到二级索引内节点中的目录项记录了,这样就能保证B+树每一层节点中各条目录项记录除页号这个字段外是唯一的,所以我们为c2列建立二级索引后的示意图实际上应该是这样子的:
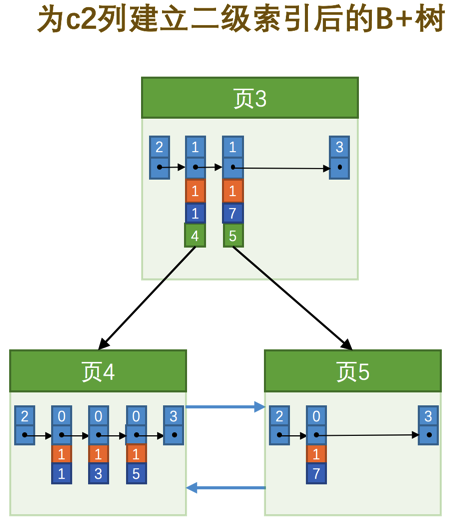
这样我们再插入记录(9, 1, 'c')时,由于页3中存储的目录项记录是由c2列 + 主键 + 页号的值构成的,可以先把新记录的c2列的值和页3中各目录项记录的c2列的值作比较,如果c2列的值相同的话,可以接着比较主键值,因为B+树同一层中不同目录项记录的c2列 + 主键的值肯定是不一样的,所以最后肯定能定位唯一的一条目录项记录,在本例中最后确定新记录应该被插入到页5中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号