python 进行抓包嗅探
一、绪论
最近一直想弄一个代理,并且对数据包进行解读,从而完成来往流量的嗅探。于是今天学习了一下如何使用Python抓包并进行解包。
首先要用到两个模块
dpkt(我这边ubuntu16.04 LTS)Python2.7中默认安装的
pcap安装
1 pip install pypcap
然后来说一下,pypcap主要用来抓包或者说是sniffer的,dpkt用来解包的,我对dpkt的认知是解包传输层以及传输层一下的数据比较不错,但是对于应用层数据的解读就是渣渣。尤其是HTTP,所以HTTP部分解包,是我自己重写的,并没有使用dpkt.http.Request和dpkt.http.Response。(总他妈报错).
二、目前做到:
(1)正常解码请求和响应数据包。
(2)对于长连接传输数据的数据包解读失败。
三、先来讲抓包

1 import pcap
2 import dpkt
3
4 sniffer = pcap.pcap(name="eth1") #name parameter => interface name
5 sniffer.setfilter("tcp") #filter sentence
6 for packet_time packet_data in sniifer:
7 pass
8
9 # packet_time => packet receive time
10 # packet_data => ethernet level data
四、解包:
1 packet = dpkt.ethernet.Ethernet(pdata)#二层数据报文嘛 2 print "SRC IP:%d.%d.%d.%d"%tuple(map(ord,list(packet.data.src))) 3 print "DST IP:%d.%d.%d.%d"%tuple(map(ord,list(packet.data.dst))) 4 print "SRC PORT:%s"%packet.data.data.sport 5 print "DST PORT:%s"%packet.data.data.dport
五、HTTP部分是我自己解的包:
1 def http_request_analyst(string):
2 string = string[1:-1]
3 method = string.split(" ")[0]
4 print "Method:",method
5 path = string.split(" ")[1]
6 print "Path:",urllib.unquote(path)
7 protover = string.split(" ")[2].split("\\r\\n")[0]
8 print "Protocol Version:",protover
9 headers = string.split("\\r\\n\\r\\n")[0].split("\\r\\n")[1:]
10 print "^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^"
11 print "Header:"
12 for header in headers:
13 header = header.split(":")
14 try:
15 hstr = "%s:%s"%(str(header[0]),str(header[1])) if header[0] not in ["Referer"] else "%s:%s:%s"%(str(header[0]),str(header[1]),str(header[2]))
16 except Exception,ex:
17 print "[*]",ex
18 print header
19 raw_input()
20 print hstr
21 print "^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^"
22 print "Data:",string.split("\\r\\n")[-1]
1 def http_response_analyst(string):
2 string = string[1:-1]
3 protover = string.split(" ")[0]
4 print "Protocol Version:",protover
5 status_code = string.split(" ")[1]
6 print "Response Code:",status_code
7 status_string = string.split(" ")[2].split("\\r\\n")[0]
8 print "Reposne String:",status_string
9 headers = string.split("\\r\\n\\r\\n")[0].split("\\r\\n")[1:]
10 print repr(headers)
11 print repr(string)
12 print "^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^"
13 print "Header:"
14 for header in headers:
15 header = header.split(":")
16 try:
17 hstr = "%s:%s"%(str(header[0]),str(header[1])) if header[0] not in ["Referer"] else "%s:%s:%s"%(str(header[0]),str(header[1]),str(header[2]))
18 except Exception,ex:
19 print "[*]",ex
20 print header
21 raw_input()
22 print hstr
23 print "^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^"
24 print "Data:",string.split("\\r\\n")[-1]
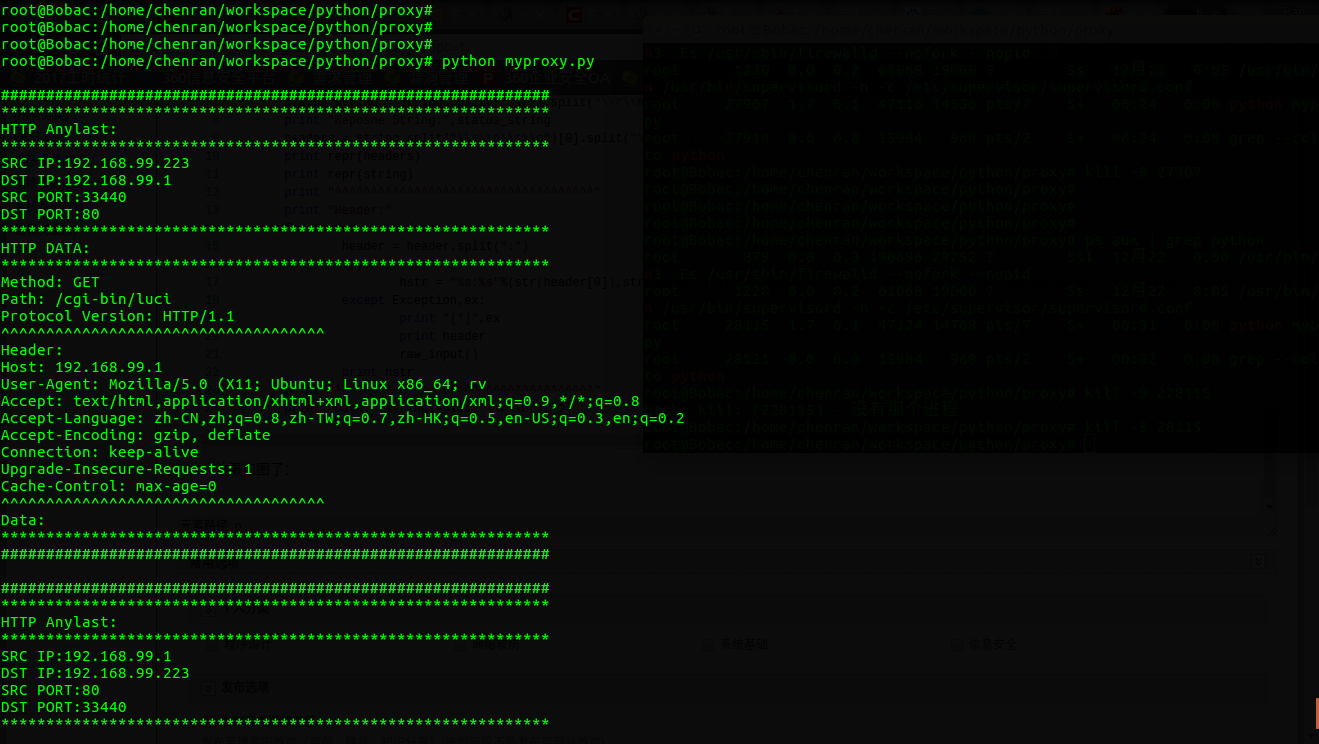
六、效果如图了:

博主简介:博主国内安全行业目前最强大的网络安全公司做技术研究员,常年做技术工作。 获得过以下全国竞赛大奖: 《中国电子作品大赛一等奖》 《云计算技术大赛一等奖》 《AIIA人工智能大赛优胜奖》《网络安全知识竞赛一等奖》 《高新技术个人突出贡献奖》,并参与《虚拟化技术-**保密**》一书编写,现已出版。还拥有多项专利,多项软件著作权! 且学习状态上进,立志做技术牛逼的人。座右铭:在路上,永远年轻,永远热泪盈眶。可邮件联系博主共同进步,个人邮箱:Mrli888@88.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号