
认识字符集
1.*础知识
计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致'a'解析成'b'或者乱码。
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项*本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为*础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
2.常用字符集和字符编码
常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
2.1. ASCII字符集&编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是*于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被Unicode追上的迹象),并等同于国际标准ISO/IEC 646。
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。ASCII字符集映射到数字编码规则如下图所示:
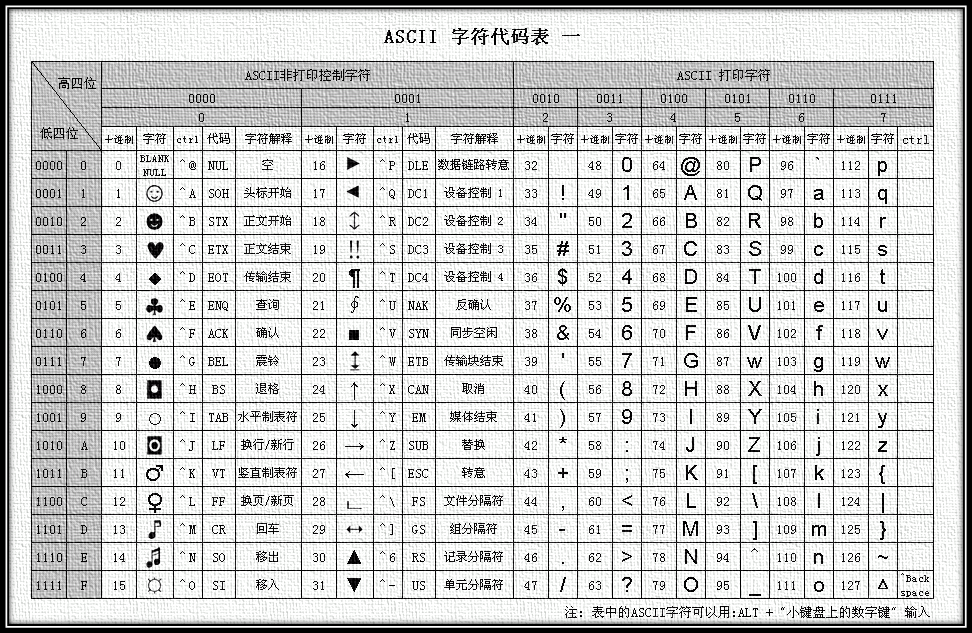
图1 ASCII编码表
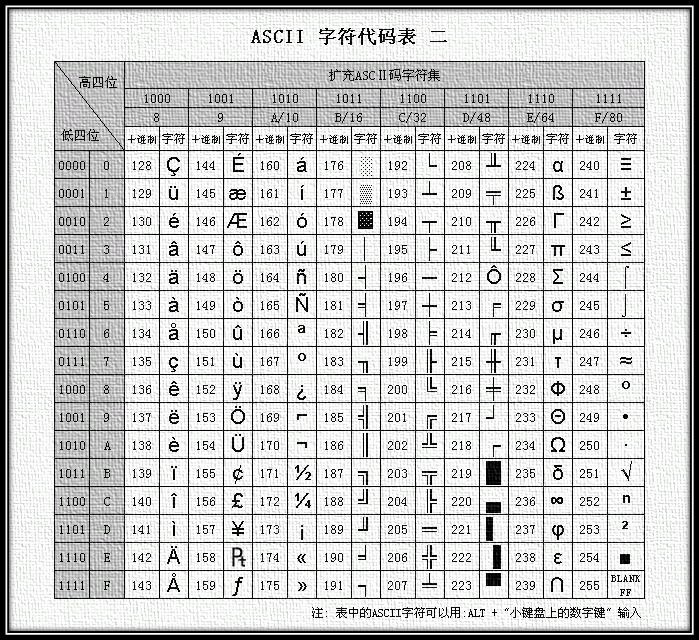
图2 扩展ASCII编码表
ASCII的最大缺点是只能显示26个*本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。而EASCII虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。因此现在的苹果电脑已经抛弃ASCII而转用Unicode。
2.2. GBXXXX字符集&编码
计算机发明之处及后面很长一段时间,只用应用于美国及西方一些发达国家,ASCII能够很好满足用户的需求。但是当天朝也有了计算机之后,为了显示中文,必须设计一套编码规则用于将汉字转换为计算机可以接受的数字系统的数。
天朝专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
上述编码规则就是GB2312。GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·*本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312的出现,*本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。下图是GB2312编码的开始部分(由于其非常庞大,只列举开始部分,具体可查看GB2312简体中文编码表):
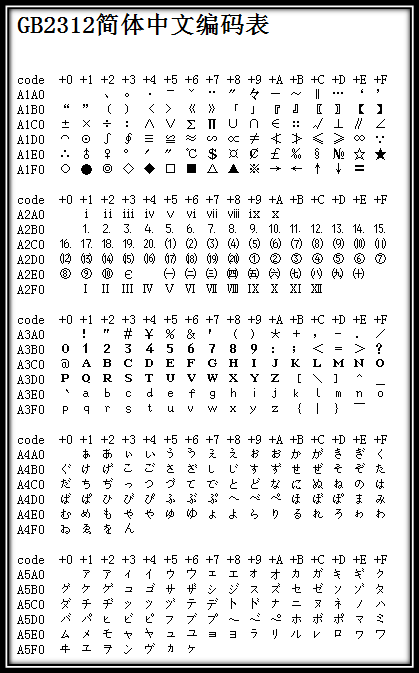
图3 GB2312编码表的开始部分
由于GB 2312-80只收录6763个汉字,有不少汉字,如部分在GB 2312-80推出以后才简化的汉字(如"啰"),部分人名用字(如中国前总理***的"*"字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。于是厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。根据微软资料,GBK是对GB2312-80的扩展,也就是CP936字码表 (Code Page 936)的扩展(之前CP936和GB 2312-80一模一样),最早实现于Windows 95简体中文版。虽然GBK收录GB 13000.1-93的全部字符,但编码方式并不相同。GBK自身并非国家标准,只是曾由国家技术监督局标准化司、电子工业部科技与质量监督司公布为"技术规范指导性文件"。原始GB13000一直未被业界采用,后续国家标准GB18030技术上兼容GBK而非GB13000。
GB 18030,全称:国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB 18030-2000《信息技术 信息交换用汉字编码字符集 *本集的扩充》的修订版。与GB 2312-1980完全兼容,与GBK*本兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。GB 18030主要有以下特点:
- 与UTF-8相同,采用多字节编码,每个字可以由1个、2个或4个字节组成。
- 编码空间庞大,最多可定义161万个字符。
- 支持中国国内少数民族的文字,不需要动用造字区。
-
汉字收录范围包含繁体汉字以及日韩汉字
![]()
图4 GB18030编码总体结构
本规格的初版使中华人民共和国信息产业部电子工业标准化研究所起草,由国家质量技术监督局于2000年3月17日发布。现行版本为国家质量监督检验总局和中国国家标准化管理委员会于2005年11月8日发布,2006年5月1日实施。此规格为在中国境内所有软件产品支持的强制规格。
-
-
3.4.UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
UTF-8使用一至四个字节为每个字符编码:
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他*本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码。
-
其他极少使用的Unicode辅助平面的字符使用四字节编码。
在处理经常会用到的ASCII字符方面非常有效。在处理扩展的拉丁字符集方面也不比UTF-16差。对于中文字符来说,比UTF-32要好。同时,(在这一条上你得相信我,因为我不打算给你展示它的数学原理。)由位操作的天性使然,使用UTF-8不再存在字节顺序的问题了。一份以utf-8编码的文档在不同的计算机之间是一样的比特流。
总体来说,在Unicode字符串中不可能由码点数量决定显示它所需要的长度,或者显示字符串之后在文本缓冲区中光标应该放置的位置;组合字符、变宽字体、不可打印字符和从右至左的文字都是其归因。所以尽管在UTF-8字符串中字符数量与码点数量的关系比UTF-32更为复杂,在实际中很少会遇到有不同的情形。
优点
- UTF-8是ASCII的一个超集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。
- 使用标准的面向字节的排序例程对UTF-8排序将产生与*于Unicode代码点排序相同的结果。(尽管这只有有限的有用性,因为在任何特定语言或文化下都不太可能有仍可接受的文字排列顺序。)
- UTF-8和UTF-16都是可扩展标记语言文档的标准编码。所有其它编码都必须通过显式或文本声明来指定。
- 任何面向字节的字符串搜索算法都可以用于UTF-8的数据(只要输入仅由完整的UTF-8字符组成)。但是,对于包含字符记数的正则表达式或其它结构必须小心。
-
UTF-8字符串可以由一个简单的算法可靠地识别出来。就是,一个字符串在任何其它编码中表现为合法的UTF-8的可能性很低,并随字符串长度增长而减小。举例说,字符值C0,C1,F5至FF从来没有出现。为了更好的可靠性,可以使用正则表达式来统计非法过长和替代值(可以查看W3 FAQ: Multilingual Forms上的验证UTF-8字符串的正则表达式)。
缺点
因为每个字符使用不同数量的字节编码,所以寻找串中第N个字符是一个O(N)复杂度的操作 — 即,串越长,则需要更多的时间来定位特定的字符。同时,还需要位变换来把字符编码成字节,把字节解码成字符。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号