MapReduce中TextInputFormat分片和读取分片数据源码级分析
转载自: http://www.cnblogs.com/lxf20061900/p/3810977.html
InputFormat主要用于描述输入数据的格式(我们只分析新API,即org.apache.hadoop.mapreduce.lib.input.InputFormat),提供以下两个功能:
(1)数据切分:按照某个策略将输入数据切分成若干个split,以便确定MapTask个数以及对应的split;
(2)为Mapper提供输入数据:读取给定的split的数据,解析成一个个的key/value对,供mapper使用。
InputFormat有两个比较重要的方法:(1)List<InputSplit> getSplits(JobContext job);(2)RecordReader<LongWritable, Text> createRecordReader(InputSplit split,TaskAttemptContext context)。这两个方法分别对应上面的两个功能。
InputSplit分片信息有两个特点:(1)是逻辑分片,只是在逻辑上对数据进行分片,并不进行物理切分,这点和block是不同的,只记录一些元信息,比如起始位置、长度以及所在的节点列表等;(2)必须可序列化,分片信息要上传到HDFS文件,还会被JobTracker读取,序列化可以方便进程通信以及永久存储。
RecordReader对象可以将输入数据,即InputSplit对应的数据解析成众多的key/value,会作为MapTask的map方法的输入。
我们本节就以最长使用的TextInputFormat为列来讲解分片和读取分片数据。
先看继承关系:(1)public class TextInputFormat extends FileInputFormat;(2)public abstract class FileInputFormat<K, V> extends InputFormat;(3)public abstract class InputFormat。最顶的父类InputFormat只有两个未实现的抽象方法getSplits和createRecordReader;而FileInputFormat包含的方法比较多,如下图:
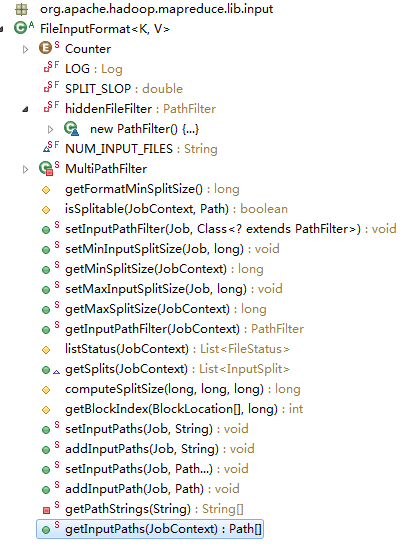 ,我们在自己的MR程序中设置输入目录就是调用这里的方法;TextInputFormat这个类只有俩个方法,代码如下:
,我们在自己的MR程序中设置输入目录就是调用这里的方法;TextInputFormat这个类只有俩个方法,代码如下:

1 /** An {@link InputFormat} for plain text files. Files are broken into lines.
2 * Either linefeed or carriage-return are used to signal end of line. Keys are
3 * the position in the file, and values are the line of text.. */
4 public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
5
6 @Override
7 public RecordReader<LongWritable, Text>
8 createRecordReader(InputSplit split,
9 TaskAttemptContext context) {
10 return new LineRecordReader();
11 }
12
13 @Override
14 protected boolean isSplitable(JobContext context, Path file) {
15 CompressionCodec codec =
16 new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
17 return codec == null;
18 }
19
20 }
isSplitable方法就是是否要切分文件,这个方法显示如果是压缩文件就不切分,非压缩文件就切分。
接下来,我们只关注上面说的那两个主要方法,首先来看:
一、getSplits方法,这个方法在FileInputFormat类中,它的子类一般只需要实现TextInputFormat中的两个方法而已,getSplits方法代码如下:


1 /** 2 * Generate the list of files and make them into FileSplits. 3 */ 4 public List<InputSplit> getSplits(JobContext job 5 ) throws IOException { 6 long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); 7 long maxSize = getMaxSplitSize(job); //Long.MAX_VALUE 8 9 // generate splits 10 List<InputSplit> splits = new ArrayList<InputSplit>(); 11 List<FileStatus>files = listStatus(job); 12 for (FileStatus file: files) { 13 Path path = file.getPath(); 14 FileSystem fs = path.getFileSystem(job.getConfiguration()); 15 long length = file.getLen(); //整个文件的长度 16 BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length); 17 if ((length != 0) && isSplitable(job, path)) { //默认是true,但是如果是压缩的,则是false 18 long blockSize = file.getBlockSize(); //64M,67108864B 19 long splitSize = computeSplitSize(blockSize, minSize, maxSize); //计算split大小 Math.max(minSize, Math.min(maxSize, blockSize)) 20 21 long bytesRemaining = length; 22 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { 23 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); 24 splits.add(new FileSplit(path, length-bytesRemaining, splitSize, 25 blkLocations[blkIndex].getHosts())); //hosts是主机名,name是IP 26 bytesRemaining -= splitSize; //剩余块的大小 27 } 28 29 if (bytesRemaining != 0) { //最后一个 30 splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining, 31 blkLocations[blkLocations.length-1].getHosts())); 32 } 33 } else if (length != 0) { //isSplitable(job, path)等于false 34 splits.add(new FileSplit(path, 0, length, blkLocations[0].getHosts())); 35 } else { 36 //Create empty hosts array for zero length files 37 splits.add(new FileSplit(path, 0, length, new String[0])); 38 } 39 } 40 41 // Save the number of input files in the job-conf 42 job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); 43 44 LOG.debug("Total # of splits: " + splits.size()); 45 return splits; 46 }
(1)minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)):getFormatMinSplitSize()=1,getMinSplitSize(job)获取"mapred.min.split.size"指定的大小,默认是1;
(2)maxSize = getMaxSplitSize(job):getMaxSplitSize(job)获取"mapred.max.split.size",默认是Long.MAX_VALUE,Long类型的最大值;
(3)返回输入目录下所有文件的FileStatus信息列表;
(4)然后对每一个文件获取它的目录、文件的长度、文件对应的所有块的信息(可能有多个块,每个块对应3个副本);
(5)然后如果文件长度不为0且支持分割(isSplitable方法等于true):获取block大小,默认是64MB,通过方法computeSplitSize(blockSize, minSize, maxSize)计算分片大小splitSize,这个方法Math.max(minSize, Math.min(maxSize, blockSize));然后将bytesRemaining(剩余未分片字节数)设置为整个文件的长度,A、如果bytesRemaining超过分片大小splitSize一定量才会将文件分成多个InputSplit:bytesRemaining)/splitSize > SPLIT_SLOP(默认1.1),B、就会执行getBlockIndex(blkLocations, length-bytesRemaining)获取block的索引,第二个参数是这个block在整个文件中的偏移量,在循环中会从0越来越大,该方法代码如下:
1 protected int getBlockIndex(BlockLocation[] blkLocations, 2 long offset) { 3 for (int i = 0 ; i < blkLocations.length; i++) { 4 // is the offset inside this block? 5 if ((blkLocations[i].getOffset() <= offset) && 6 (offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){ 7 return i; 8 } 9 } 10 BlockLocation last = blkLocations[blkLocations.length -1]; 11 long fileLength = last.getOffset() + last.getLength() -1; 12 throw new IllegalArgumentException("Offset " + offset + 13 " is outside of file (0.." + 14 fileLength + ")"); 15 }
这个方法中的if语句的条件会限制获取到,这个偏移量对应的block的索引;C、将这个索引对应的block信息的主机节点以及文件的路径名、开始的便宜量、分片大小splitSize封装到一个InputSplit中加入List<InputSplit> splits;D、bytesRemaining -= splitSize修改剩余字节大小;E、返回A中继续判断,如果满足即系走BCD,否则跳出循环。如果剩余bytesRemaining还不为0,表示还有未分配的数据,将剩余的数据及最后一个block加入splits。
(6)如果不允许分割isSplitable==false,则将第一个block、文件目录、开始位置为0,长度为整个文件的长度封装到一个InputSplit,加入splits中;
(7)如果文件的长度==0,则splits.add(new FileSplit(path, 0, length, new String[0]))没有block,并且初始和长度都为0;
(8)将输入目录下文件的个数赋值给 "mapreduce.input.num.files",方便以后校对;
(9)返回分片信息splits。
这就是getSplits获取分片的过程。当使用基于FileInputFormat实现InputFormat时,为了提高MapTask的数据本地性,应尽量使InputSplit大小与block大小相同。
特殊问题:就是如果分片大小超过bolck大小,但是InputSplit中的封装了单个block的所在主机信息啊,这样能读取多个bolck数据吗?这个问题我们留到最后讲解。
二、createRecordReader方法,该方法返回一个RecordReader对象,实现了类似的迭代器功能,将某个InputSplit解析成一个个key/value对。RecordReader应该注意两点:
A、定位记录边界:为了能识别一条完整的记录,应该添加一些同步标示,TextInputFormat的标示是换行符;SequenceFileInputFormat的标示是每隔若干条记录会添加固定长度的同步字符串。为了解决InputSplit中第一条或者最后一条可能夸InputSplit的情况,RecordReader规定每个InputSplit的第一条不完整记录划给前一个InputSplit。
B、解析key/value:将每个记录分解成key和value两部分,TextInputFormat每一行的内容是value,该行在整个文件中的偏移量为key;SequenceFileInputFormat的记录共有四个字段组成:前两个字段分别是整个记录的长度和key的长度,均为4字节,后两个字段分别是key和value的内容。
TextInputFormat使用的RecordReader是org.apache.hadoop.mapreduce.lib.input.LineRecordReader。我们在MapReduce的MapTask任务的运行源码级分析这篇文章中有介绍过LineRecordReader,initialize方法主要是获取分片信息的初始位置和结束位置,以及输入流(若有压缩则是压缩流);mapper的key/value是通过LineRecordReader.nextKeyValue()方法将key和value读取到key和value中的,在这个方法中key被设置为在文件中的偏移量,value通过LineReader.readLine(value, maxLineLength, Math.max((int)Math.min(Integer.MAX_VALUE, end-pos),maxLineLength))这个方法会读取一行数据放入value之中,方法代码如下:
1 /** 2 * Read one line from the InputStream into the given Text. A line 3 * can be terminated by one of the following: '\n' (LF) , '\r' (CR), 4 * or '\r\n' (CR+LF). EOF also terminates an otherwise unterminated 5 * line. 6 * 7 * @param str the object to store the given line (without newline) 8 * @param maxLineLength the maximum number of bytes to store into str; 9 * the rest of the line is silently discarded. 10 * @param maxBytesToConsume the maximum number of bytes to consume 11 * in this call. This is only a hint, because if the line cross 12 * this threshold, we allow it to happen. It can overshoot 13 * potentially by as much as one buffer length. 14 * 15 * @return the number of bytes read including the (longest) newline 16 * found. 17 * 18 * @throws IOException if the underlying stream throws 19 */ 20 public int readLine(Text str, int maxLineLength, 21 int maxBytesToConsume) throws IOException { 22 /* We're reading data from in, but the head of the stream may be 23 * already buffered in buffer, so we have several cases: 24 * 1. No newline characters are in the buffer, so we need to copy 25 * everything and read another buffer from the stream. 26 * 2. An unambiguously terminated line is in buffer, so we just 27 * copy to str. 28 * 3. Ambiguously terminated line is in buffer, i.e. buffer ends 29 * in CR. In this case we copy everything up to CR to str, but 30 * we also need to see what follows CR: if it's LF, then we 31 * need consume LF as well, so next call to readLine will read 32 * from after that. 33 * We use a flag prevCharCR to signal if previous character was CR 34 * and, if it happens to be at the end of the buffer, delay 35 * consuming it until we have a chance to look at the char that 36 * follows. 37 */ 38 str.clear(); 39 int txtLength = 0; //tracks str.getLength(), as an optimization 40 int newlineLength = 0; //length of terminating newline 41 boolean prevCharCR = false; //true of prev char was CR 42 long bytesConsumed = 0; 43 do { 44 int startPosn = bufferPosn; //starting from where we left off the last time 45 if (bufferPosn >= bufferLength) { 46 startPosn = bufferPosn = 0; 47 if (prevCharCR) 48 ++bytesConsumed; //account for CR from previous read 49 bufferLength = in.read(buffer); //从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。以整数形式返回实际读取的字节数。 50 if (bufferLength <= 0) //结束了,没数据了 51 break; // EOF 52 } 53 //'\n',ASCII码:10,意义:换行NL;;;;'\r' ,ASCII码:13,意义: 回车CR 54 for (; bufferPosn < bufferLength; ++bufferPosn) { //search for newline 55 if (buffer[bufferPosn] == LF) { //如果是换行字符\n 56 newlineLength = (prevCharCR) ? 2 : 1; 57 ++bufferPosn; // at next invocation proceed from following byte,越过换行字符 58 break; 59 } 60 if (prevCharCR) { //CR + notLF, we are at notLF,如果是回车字符\r 61 newlineLength = 1; 62 break; 63 } 64 prevCharCR = (buffer[bufferPosn] == CR); 65 } 66 int readLength = bufferPosn - startPosn; 67 if (prevCharCR && newlineLength == 0) //表示还没遇到换行,有回车字符,且缓存最后一个是\r 68 --readLength; //CR at the end of the buffer 69 bytesConsumed += readLength; 70 int appendLength = readLength - newlineLength; //newlineLength换行符个数 71 if (appendLength > maxLineLength - txtLength) { 72 appendLength = maxLineLength - txtLength; 73 } 74 if (appendLength > 0) { 75 str.append(buffer, startPosn, appendLength); //将数据加入str 76 txtLength += appendLength; 77 } 78 } while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);//循环条件没有换行并且没超过上限 79 80 if (bytesConsumed > (long)Integer.MAX_VALUE) 81 throw new IOException("Too many bytes before newline: " + bytesConsumed); 82 return (int)bytesConsumed; 83 }
这个方法目的就是读取一行记录写入str中。bytesConsumed记录这读取的字节总数;bufferLength = in.read(buffer)从输入流读取bufferLength字节的数据放入buffer中;do-while中开始部分的if语句是要保证将bufferLength个字节数据处理完毕之后再从输入流中读取下一批数据;newlineLength表示换行的标记符长度(0,1,2三种值),因为不同的系统换行标记可能不同,有三种:\r(回车符)、\n(换行符)、\r\n(\n: UNIX 系统行末结束符;\r\n: window 系统行末结束符;\r: MAC OS 系统行末结束符);for循环会挨个检查字符是否是\r或者\n,如果是回车符\r,还会将prevCharCR设置为true,当前字符如果是换行符\n,prevCharCR==true时(表示上一个字符是回车符\r)则newlineLength=2(这表明当前系统的换行标记是\r\n),prevCharCR==false时(表示上一个字符不是回车符\r)则newlineLength=1(这表明当前系统的换行标记是\n),并退出for循环;如果当前字符不是换行符\n且prevCharCR==true(表明当前系统的换行标记是\r)则newlineLength = 1并退出for循环;这样就找到了换行的标记,然后计算数据的长度appendLength(不包括换行符),将buffer中指定位置开始长度为appendLength的数据追加到str(这里其实是value)中;txtLength表示的是str(这里其实是value中值的长度);do-while循环的条件是:1、没有发现换行标记newlineLength == 0;2、读取的字节数量没有超过上限bytesConsumed < maxBytesToConsume,这俩条件要同时满足。这其中有个问题就是当前系统的换行标记是\r\n,但是这两个字符没有同时出现在这次读取的数据之中,\n在下一个批次之中,这没关系,上面的for循环会检查\r出现之后的下一个字符是否是\n再对newlineLength进行设置的。从这个方法可以看出,即使是记录跨split、跨block也不能阻止它完整读取一行数据的决心啊。
再返回查看LineRecordReader.nextKeyValue()方法,这个方法代码如下:
1 public boolean nextKeyValue() throws IOException { 2 if (key == null) { 3 key = new LongWritable(); 4 } 5 key.set(pos); 6 if (value == null) { 7 value = new Text(); 8 } 9 int newSize = 0; 10 while (pos < end) { 11 newSize = in.readLine(value, maxLineLength, 12 Math.max((int)Math.min(Integer.MAX_VALUE, end-pos), 13 maxLineLength)); 14 if (newSize == 0) { 15 break; 16 } 17 pos += newSize; 18 if (newSize < maxLineLength) { 19 break; 20 } 21 22 // line too long. try again 23 LOG.info("Skipped line of size " + newSize + " at pos " + 24 (pos - newSize)); 25 } 26 if (newSize == 0) { 27 key = null; 28 value = null; 29 return false; 30 } else { 31 return true; 32 } 33 }
这个方法会控制split的读取数据的结束位置,上面的readLine方法只关注输入流不会管split的大小的。需要注意的是其中的while循环,其中的pos和end表示当前在文件中的偏移量和split的结束位置,即使这个split的最后一行跨split也会完整的获取一行。也就保证了一个记录的完整性。mapper获取key/value会通过调用getCurrentKey()和getCurrentValue()来达到的,但是调用这俩方法前得先调用nextKeyValue()方法才能实现key和value的赋值。
到这我们回头看看上面的那个特殊问题,就是split的大小超过block的大小数据读取的问题,我们前面已经讲过split是逻辑分片,不是物理分片,当MapTask的数据本地性发挥作用时,会从本机的block开始读取,超过这个block的部分可能还在本机也可能不在本机,如果是后者的话就要从别的节点拉数据过来,因为实际获取数据是一个输入流,这个输入流面向的是整个文件,不受什么block啊、split的影响,split的大小越大可能需要从别的节点拉的数据越多,从从而效率也会越慢,拉数据的多少是由getSplits方法中的splitSize决定的。所以为了更有效率,应该遵循上面的黑体字。
至此,TextInputFormat的分片和数据读取过程讲完了。这只是一个例子,其他InputFormat可以参考这个。
参考:1、董西成,《hadoop技术内幕---深入理解MapReduce架构设计与实现原理》
2、http://www.cnblogs.com/clarkchen/archive/2011/06/02/2068609.html
可以分3层来理解。
物理层:block数据块,hadoop1默认blocksize为64MB, hadoop2默认为128MB。如果数据小于block大小,占用真实数据大小,而不会占一个block大小。一条记录可以跨block存储。
逻辑层:split,split确定maptask的操作单元。splitsize = Math.max(minSize, Math.min(maxSize, blockSize))。split可能跨block,当跨block的时候就需要远程读取数据。
业务层:在每个spit中根据RecordReader来读取数据。记录可能跨spit,在这种情况下,每个Split的第一条不完整记录划给前一个Split。于是RecordReader读到的记录一定是完整的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号