一文读懂 Redis 分布式部署方案
为什么要分布式
Redis是一款开源的基于内存的K-V型数据库,因为内存访问速度快,一般被用来做系统的缓存。
Redis作为单机部署能够支持业务简单,数据量不大的系统需求,但在实际应用中,一旦系统规模上来,单机的Redis就会遇到下面的挑战:
- 伸缩性。系统随着长期运行与业务增长,对Redis存储的数据量需求也越来越大,单机必然受限于服务器的内存与磁盘大小。
- 高性能。系统规模变大后,对Redis的吞吐量需求也会提高,而单机的吞吐量必然有限,这种情况会影响整体系统的性能。
- 高可用。Redis持久化机制一定程度上能缓解单点问题,但是需要花费时间去恢复,在恢复的过程中服务可能不可用,或者数据会有丢失。
分布式解决方案
分布式的解决方案对于业内是通用的:
- 水平拆分。单点的一个重要挑战就是数据量大的时候单点存储不够。直接的想法就是部署多个实例,将需要存储的数据分散存储到各个实例中。当实例存储空间不够时,继续扩大实例个数就可以解决数据伸缩性问题。同时这种数据水平拆分的方法也可以解决单机性能问题,因为不同的数据读写可以分配到不同的实例。
- 主从复制。如果只有水平拆分,如果其中一个实例出现了问题,那该实例上存储的数据都不可访问,还是存在可用问题。为此可以进行所有数据的主备复制,同一份数据可以有多个副本,当某个实例出现问题时,可以启用该实例的副本,达到高可用的目的。同时副本也可以帮助提高系统的吞吐能力,因为对数据的访问也可以分发到副本上。
存储的分布式解决方案大抵如上,不同的是各种系统的实现方法不同。下面我们来看下Redis的分布式解决方案是怎样的。
历史发展
分布式解决方案不是一蹴而就的,也有个发展的过程,不同历史时期提供的方案可能不同,最新的解决方案也可能在不远的将来被替换。
主从复制(replication)是Redis分布式的基础。Redis中包含两种节点:master节点与slave节点。同一份数据存放在master与多个slave节点上,
master对外提供读写,slave不对外提供写操作。当master宕机时,slave节点还能继续提供服务。主从复制中最重要的就是主从数据如何同步。
Redis的主从同步分为全量同步与增量同步,在下面的章节会详细介绍。
如果只有主从复制,当master宕机时,需要运维人工将slave节点切换成master。这在生产环境是不可接受的,在这过程中系统可能无法使用。所以需要有一个机制,当master宕机时能自动进行主从切换,应用程序无感知,继续提供服务。于是Redis官方提供了一种方案: Redis Sentinel(哨兵模式)。
简单的说,哨兵模式就是在主从基础上增加了哨兵节点,哨兵节点不存储业务数据,它负责监控主从节点的健康,当主节点宕机时,它能及时发现,并自动选择一个从节点,将其切换成主节点。为了避免哨兵本身成为单点,哨兵一般也由多个节点组成。
主从复制与哨兵模式解决了高可用问题,但数据的伸缩性还不行,还需要进行水平拆分。而这个时期大数据高并发的需求在快速增长,哪里有需求,哪里就有市场。在Redis官方自己的集群方案出来之前,Codis应运而生并得到快速发展。
Codis是中国人开发并开源的,来自前豌豆荚中间件团队。Codis和后面的Redis Cluster相似,将特定的key分发到特定的Redis实例上,默认将key化为1024个槽位;另外Codis采用zookeeper来维护节点间数据的一致性;更方便的是Codis提供了非常友好的后台管理界面。更深入的大家可以自行去了解。但是当Redis官方的集群方案 Redis Cluster 发布后,Codis的境遇就有些尴尬了。毕竟不是亲生的,很多新的特性总比Redis官方慢一拍。
正是因为分布式是刚需,所以Redis官方在3.0版本推出了自己的分布式方案,这就是Redis Cluster。这个名词可能有些歧义,它不是简单地代表Redis集群,而是Redis的一种分布式方案,该方案的名称就叫Redis Cluster。下面我们就重点介绍下该方案。
Redis Cluster
Redis Cluster 提供了一种去中心化的分布式方案,该方案可以实现水平拆分,故障转移等需求。
拓扑结构
一个Redis Cluster由多个Redis节点组成,这里的节点指的是Redis实例,一台服务器上可能有多个实例。这些节点可按节点组划分,每个节点组里的节点存放相同的数据,里面有且只有一个是master节点,同时有0到多个slave节点。不同节点组存放的数据没有交集,而所有节点组的数据组成这个Redis Cluster的全部数据集合。
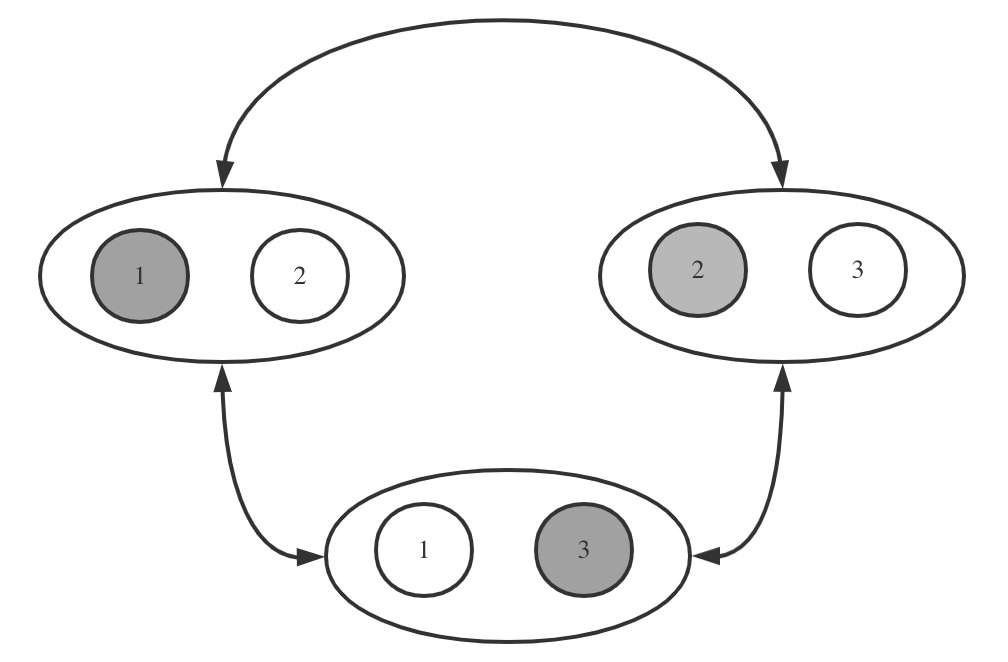
如图所示,这里有3台服务器,每台服务器上有2个 Redis 实例。标号相同的节点组成一个节点组,他们存放相同的数据,如标号为1的2个节点组成一个节点组,其中深色的为master节点,另外一个为slave节点。也就是全量数据被划分为3份,分别标号1/2/3。每份数据又有1个 slave 节点,他们通过主从复制保存和 master 节点相同的数据。这里主要有两方面:一是主从复制,二是数据横向划分,在 Redis 中称为分片 Sharding。
主从复制 Replication
主从节点最重要的是如何保证主从节点数据的一致性。只有 master 节点提供数据的写操作,数据被写到 master 节点后,再同步到 slave 节点。
主从之间的数据同步可以分为全量同步与增量同步。
全量同步
全量同步也称为快照同步,主节点上进行一次 bgsave 操作,将当前内存的数据全部快照写到磁盘文件中,然后将文件同步给从节点。从节点清空当前内存全部数据后全量加载该文件,这样达到与主节点数据同步的目的。
但是在从节点加载快照文件的过程中,主节点还在对外提供写服务。所以当从节点加载完快照后,依旧可能与主节点数据不一致,这时就需要增量同步上场了。
增量同步
增量同步的不是数据,而是指令流。主节点会将对当前数据状态产生修改的指令记录在内存的一个buffer中,然后异步地将buffer同步到从节点,从节点通过执行buffer中的指令,达到与主节点数据一致的目的。
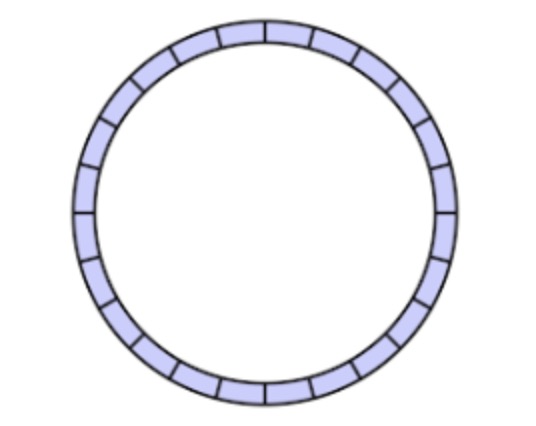
Redis的buffer是一个定长的环形结构,当指令流满的时候,会覆盖最前面的内容。所以当从节点上次增量同步由于各种原因,导致花费时间较长时,再次同步指令流时,就有可能前面没有同步的指令被覆盖掉了。这种情况就需要进行全量同步了。
所以全量同步与增量同步是相辅相成的关系。全量同步时一个很耗资源与时间的操作,如果单靠全量同步,同步操作会很重,在同步的长时间过程中不能提供服务。而增量同步有buffer容量限制,仅仅靠增量同步可能造成数据丢失,导致主从数据不一致。
分片 Sharding
所谓分片,就是将数据集按照一定规则,分散存储在各个节点上。这里涉及两个问题:
1.分片规则是什么?
2.如何存储在各个节点上?
Redis将所有数据分为16384个hash slot(槽),每条数据(key-value)根据key值通过算法映射到其中一个slot上,这条数据就存储在该slot中。映射算法是:
slotId=crc16(key)%16384
Redis的每个key都会基于该分片规则,落到特定的slot上。而在集群部署完成时,slot的分布就已经确定了。
172.16.190.78:7001> cluster nodes 08a5e808d2e6f6b231d73519bd4f05f74614c2a2 172.16.190.77:7000@17000 master - 0 1592218859545 3 connected 10923-16383 2c75029ab638a48537a4c02ed0ca77a19fc4106b 172.16.190.78:7000@17000 master - 0 1592218860448 1 connected 0-5460 50884e234c5f1ccf03f5a6d1cc4e6e6dc4779752 172.16.242.36:7000@17000 master - 0 1592218860000 2 connected 5461-10922 d0381ef4aad364c42e08bf1c2d78168f4901bd90 172.16.190.78:7001@17001 myself,slave 08a5e808d2e6f6b231d73519bd4f05f74614c2a2 0 1592218859000 4 connected e5c154dcf02526b807c67bebf0a63b4c98118ffe 172.16.190.77:7001@17001 slave 50884e234c5f1ccf03f5a6d1cc4e6e6dc4779752 0 1592218861048 6 connected 4a1b49cd77dbd18eba677663777f211be6f68dae 172.16.242.36:7001@17001 slave 2c75029ab638a48537a4c02ed0ca77a19fc4106b 0 1592218860000 5 connected
如上图,3个master节点,172.16.190.77:7000节点存放10923-16383 slot,172.16.190.78:7000节点存放0-5460 slot,172.16.242.36:7000存放5461-10922 slot。
对于一个稳定的集群,slot的分布也是固定的。但在一些情况下,slot的分布需要发生改变:
- 新的master加入
- 节点分组退出集群
- slot分布不均匀
这些情况下就需要进行slot的迁移。slot迁移的触发与过程控制都是由外部系统完成,Redis只提供能力,但不自动进行slot迁移。
MOVE & ASKING
MOVED/ASKING 类似http的重定向码3xx,是操作的一种错误返回。
当客户端向某个节点发出指令,该节点发现指令的key对应的slot不在当前节点上,这时Redis会向客户端发送一个MOVED指令,告诉它正确的节点,然后客户端去连这个正确的节点并进行再次操作。如下,15495为key a所在的slot id。
172.16.190.78:7001> get a (error) MOVED 15495 172.16.190.77:7000
ASKING 是在slot迁移过程中的一种错误返回。当某个slot在迁移过程中,客户端发了一个位于该slot的某个key的操作请求,请求被路由到旧的节点。此时该key如果在旧节点上存在,则正常操作;如果在旧的节点上找不到,那么可能该key已被迁移到新的节点上,也可能就没有该key,此时会返回ASKING,让客户端跳转到新的节点上去执行。
MOVED 与 ASKING 的共同点是两者都是重定向,区别在于 MOVED 是永久重定向,下次对同样的key
进行操作,客户端就将请求发送到正确的节点,而 ASKING 是临时重定向,它只对这次操作起作用,不会更新客户端的槽位关系表。
故障恢复
前面提到Redis Cluster是一个去中心化的集群方案。比如Codis采用zookeeper来维护节点间状态一致性,Redis哨兵模式是哨兵来管理节点的状态,这些都是中心化的例子。Redis Cluster没有专门用于维护节点状态的节点,而是所有节点通过Gossip协议相互通信,广播自己的状态以及自己对整个集群认知的改变。
如果一个节点宕掉了,其他节点和它进行通信时,会发现改节点失联。当某个节点发现其他节点失联时,会将这个失联节点状态变成PFail(possible fail),并广播给其他节点。当一个节点收到某个节点PFail的数量达到了主节点的大多数,就标记该节点为Fail,并进行广播,通过这种方式确认节点故障。
当slave发现其master状态为Fail后,它会发起选举,如果其他master节点都同意,则该slave进行从主切换,变成master节点。同时会将自己的状态广播给其他节点,达到大家信息一致性。
根据上面的原理,下面情况下是无法自动从主切换,达到集群继续可用目的的,在实际部署时应避免:
- 如果一个节点组中的master与slave部署在同一服务器上,当服务器发生故障时,master与salve同时Fail。
- 比如总共3个master,其中2个master部署在同一服务器上,当服务器发生故障时,这两个master同时Fail,slave无法完成从主切换,因为PFail的数量无法达到主节点的大多数。
当集群节点发生变化时,需要将变化同步到客户端,客户端才能根据新的集群拓扑来向正确的节点发送请求。
比如Redis客户端Lettuce,在连接配置中配置了多个节点,Lettuce会选择其中一个可用节点进行连接。在连接断开之前,如果该节点挂掉,Lettuce不会自动进行节点切换,此时会不断地抛连接异常,无法继续读写。Lettuce提供了在连接过程中自适应刷新集群拓扑,即在连接失败时自动刷新,也可以设计定时刷新。
ClusterTopologyRefreshOptions topologyRefreshOptions = ClusterTopologyRefreshOptions.builder()
.enablePeriodicRefresh(Duration.ofMinutes(10))
.enableAllAdaptiveRefreshTriggers()
.adaptiveRefreshTriggersTimeout(Duration.ofSeconds(30)).build();
参考:
1.《深入分布式缓存 从原理到实战》于君泽 曹洪伟 邱硕等著
2.《Redis 深度历险:核心原理与应用实践》老钱
3.Redis官网:https://lettuce.io/core/release/reference/index.html
更多分享,👇


 浙公网安备 33010602011771号
浙公网安备 33010602011771号