【MySql】Explain执行计划
-- 使用 Explain + SQL
分析执行计划:
-
id:表示此表的执行优先级
-
id相同,表的执行顺序依次从上往下;
-

-
-
id不同,并且递增,id值越大执行优先级越高,越先被执行;
-

-
select_type:读取一张表的操作类型
-
SIMPLE:简单SELECT查询,并且整个语句中的查询不包含<子查询>和<联合查询UNION>
-
PRIMARY:复杂查询中最外层查询,即PRIMARY
-
SUBQUERY:子查询``
-
DERIVED:衍生,FROM后面跟的子查询; select * from (select * from t1 where id = 1) d1
-
UNION:联合查询
-
UNION RESULT:UNION合并的结果集;
-
-
table:表示这一行操作,是哪一张表的
-
type:表示此条查询的检索方式(7种,下面是按照效率由高到低排列)
-
system:基本用不到,表示一张表,只有一条记录;
-
const: where id = 1 指定的常量查询;
-
eq_ref:唯一索引扫描;对于某个索引键,表中只有一条记录与之匹配;(比如id主键索引)
-
ref:非唯一索引扫描; where name = 'ZhangSan' ,如果ZhangSan不止一个人,且name字段建有索引,那么就是ref检索;
-
range: where id between 30 and 60 或者类似 where id in (1,3,5)
-
index: select id from user 其中id是主键索引;
-
ALL:表明检索方式为全表扫描;出ALL类型检索,需要优化。
-
-
possible_keys:可能用到的索引
-
key:实际使用的索引
-
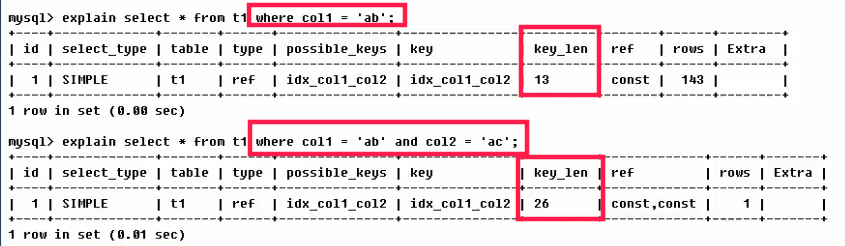
key_len:索引中使用的字节数
-
ref:MySQL 用来与索引值进行比较的值。单次 const表示的是对常数进行比较,若是某个列的名称,则表示逐个比较列。
-
rows:大致估算出每张表有多少行记录被查询了
-
Extra:额外信息
-
Using filesort:文件排序,在无法通过索引来进行排序的情况下,就会默认使用文件排序;如果出现此信息,表示需要优化;
-
Using temporary:使用临时表,表示在排序时,使用了临时表;也是提示我们,此语句需要优化;
-
Using index:表明相应的查询操作中,使用了覆盖索引;
如果同时伴有Using where:表明索引被用来执行索引键值的查找;
-

如果不带有Using where:表明索引用来读取数据,而非查找动作;

-
-
impossible where:表示错误的where,比如 where name = 'lisi' and name = 'zhangsan'
-
distinct:自动优化distinct关键字,在找到第一条匹配项后停止
-
Explain例子
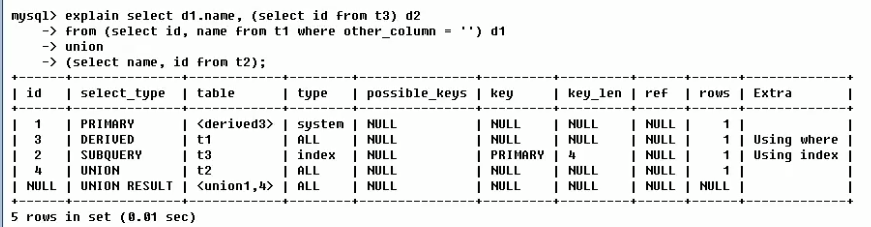
表的执行顺序:
-
【select name, id from t2】
-
【select id, name from t1 where other_column = ' '】子查询
-
【select id, from t3 】衍生查询
-
【select d1.name ...】最外层查询
-
UNION操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号