Django路由系统
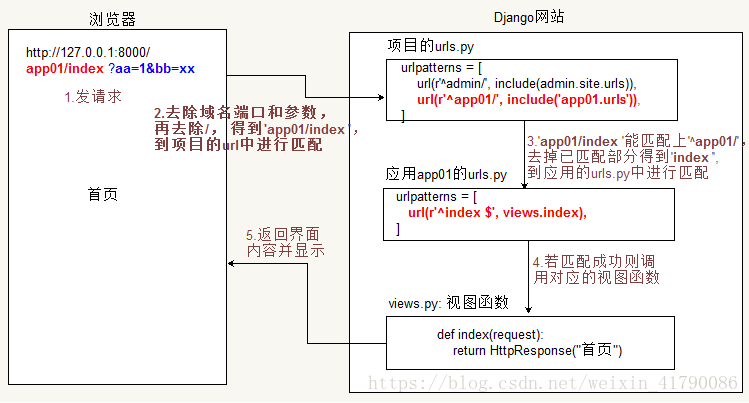
一 Django处理请求过程
路由系统就是建立url地址和视图函数的对应关系,当用户请求某个url地址时,让django能找到对应的视图函数进行处理。
当用户请求一个页面时,Django根据下面的逻辑执行操作:
- 决定要使用的根URLconf模块。通常,这是
ROOT_URLCONF设置的值,但是如果传入的HttpRequest对象具有urlconf属性(由中间件设置),则其值将被用于代替ROOT_URLCONF设置。通俗的讲,就是你可以自定义项目入口url是哪个文件! - 加载该模块并寻找可用的urlpatterns。 它是
django.conf.urls.url()实例的一个列表。 - 依次匹配每个URL模式,在与请求的URL相匹配的第一个模式停下来。也就是说,url匹配是从上往下的短路操作,所以url在列表中的位置非常关键。
- 导入并调用匹配行中给定的视图,该视图是一个简单的Python函数(被称为视图函数),或基于类的视图。 视图将获得如下参数:
- 一个HttpRequest 实例。
- 如果匹配的正则表达式返回了没有命名的组,那么正则表达式匹配的内容将作为位置参数提供给视图。
- 关键字参数由正则表达式匹配的命名组组成,但是可以被
django.conf.urls.url()的可选参数kwargs覆盖。
- 如果没有匹配到正则表达式,或者过程中抛出异常,将调用一个适当的错误处理视图。
二 转换器
2.1 path转换器
在django2.0 以上的版本中,默认使用的是path转换器,url字符串有以下规则:
- 在url里使用尖括号“<>”来捕获值
- 尖括号捕获值的格式<converter:name>。其中converter为路径转换器,name为参数名,如<int:year>。对于捕获的值没有路径转换器,那么它会匹配除了斜杠"/"外的所有字符作为捕获的值。可以转换捕获到的值为指定类型,比如例子中的int。默认情况下,捕获到的结果保存为字符串类型,不包含
/这个特殊字符 - url不需要以斜杠开头,不用再使用^和$。
Path converter:
- str:匹配除了路径分隔符(/)之外的非空字符串,如果没有转换器,默认使用str作为转换器。
- int:匹配0及正整数。
- slug:匹配字母、数字以及横杠、下划线组成的字符串。
- uuid:匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
- path:匹配任何非空字符串,包含了路径分隔符(/)
from django.urls import path from . import views urlpatterns = [ path('articles/2003/', views.special_case_2003), path('articles/<int:year>/', views.year_archive), path('articles/<int:year>/<int:month>/', views.month_archive), path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail), ]
实例:
/articles/2005/03/ 将匹配第三条,并调用views.month_archive(request, year=2005, month=3); /articles/2003/匹配第一条,并调用views.special_case_2003(request); /articles/2003将一条都匹配不上,因为它最后少了一个斜杠,而列表中的所有模式中都以斜杠结尾; /articles/2003/03/building-a-django-site/ 将匹配最后一个,并调用views.article_detail(request, year=2003, month=3, slug="building-a-django-site"
参考:自定义path转换器
https://majing.io/posts/10000004841213
2.2 re_path转换器
Django2.0向老版本兼容。使用re_path,其效果与url基本一致。
from django.urls import path, re_path from . import views urlpatterns = [ path('articles/2003/', views.special_case_2003), re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive), re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive), re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<slug>[\w-]+)/$', views.article_detail), ]
与path()方法不同的在于:传递给视图的所有参数都是字符串类型。而不像path()方法中可以指定转换成某种类型。
三 分组命名
详细解释:https://www.cnblogs.com/mushuiyishan/p/11568567.html#_label2
分组未命名位置传参,分组命名为关键词传参
分组命名主要的作用是用于传参,采用正则search()方法,默认group(0),分组未命名传递group(1)、group(2)等参数。
在Python的正则表达式中,分组命名的语法是(?P<name>pattern),其中name是组的名称,pattern是要匹配的模式。
from django.urls import path,re_path from app01 import views urlpatterns = [ re_path(r'^articles/2003/$', views.special_case_2003), re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive), re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive), re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail), ]
这个实现与前面的示例完全相同,只有一个细微的差别:捕获的值作为关键字参数而不是位置参数传递给视图函数。例如:
/articles/2005/03/ 请求将调用views.month_archive(request, year='2005', month='03')函数,而不是views.month_archive(request, '2005', '03')。 /articles/2003/03/03/ 请求将调用函数views.article_detail(request, year='2003', month='03', day='03')。
在path里支持对view中的视图函数的形参设置默认值
rom django.urls import path from . import views urlpatterns = [ path('blog/', views.page), path('blog/page<int:num>/', views.page), ] # View (in blog/views.py) def page(request, num=1): pass
传统参数传递:?
例如,http://127.0.0.1:8000/plist/?p1=china&p2=2012,url中‘?’之后表示传递的参数,这里传递了p1和p2两个参数。通过这样的方式传递参数,就不会出现因为正则匹配错误而导致的问题了。在Django中,此类参数的解析是通过request.GET.get方法获取的。
def helloParams(request): p1 = request.GET.get('p1') p2 = request.GET.get('p2') return HttpResponse("p1 = " + p1 + "; p2 = " + p2)
输出结果为:”p1 = china; p2 = 2012″
四 路由分发
在项目url中:
from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('mainapp/', include('mainApp.urls')), ]
路由转发使用的是include()方法,需要提前导入,它的参数是转发目的地路径的字符串,路径以圆点分割。
注意,这个例子中的正则表达式没有包含$(字符串结束匹配符),但是包含一个末尾的斜杠。 每当Django 遇到include()(来自django.conf.urls.include())时,它会去掉URL中匹配的部分并将剩下的字符串发送给include的URLconf做进一步处理,也就是转发到二级路由去。
在app下的url中:mainApp/urls文件中
from django.urls import path from mainApp import views urlpatterns = [ path('author/', views.author), ]
五 反向解析
在使用Django 项目时,一个常见的需求是获得URL 的最终形式,Django 提供不同的工具用于URL 反查:
- 在模板中:使用url 模板标签
- 在Python 代码中:使用from django.urls import reverse
实例,首先url命名
re_path(r'^home', views.home, name='home'), # 给我的url匹配模式起名为 home re_path(r'^index/(\d*)', views.index, name='index'), # 给我的url匹配模式起名为index,传递参数
在模板里面可以这样引用:
{% url 'home' %}
{% url 'index' 2008 %}
在views函数中可以这样引用:
from django.urls import reverse
reverse("index", args=("2018", ))
六 命名空间
即使不同的APP使用相同的URL名称,URL的命名空间模式也可以让你唯一反转命名的URL。
project中的urls.py
from django.conf.urls import url, include
urlpatterns = [
url(r'^app01/', include('app01.urls', namespace='app01')),
url(r'^app02/', include('app02.urls', namespace='app02')),
]
app01中的urls.py
from django.conf.urls import url
from app01 import views
app_name = 'app01'
urlpatterns = [
url(r'^(?P<pk>\d+)/$', views.detail, name='detail')
]
app02中的urls.py
from django.conf.urls import url
from app02 import views
app_name = 'app02'
urlpatterns = [
url(r'^(?P<pk>\d+)/$', views.detail, name='detail')
]
现在,我的两个app中 url名称重复了,我反转URL的时候就可以通过命名空间的名称得到我当前的URL。
语法:'命名空间名称:URL名称'
模板中使用:
{% url 'app01:detail' pk=12 pp=99 %}
views中的函数中使用
v = reverse('app01:detail', kwargs={'pk':11})
这样即使app中URL的命名相同,我也可以反转得到正确的URL了。

