模块导入,正则表达式,常见模块,异常处理
一 模块导入
1. 模块基础
模块即文件
模块的分类:
- 内置模块;
- 第三方/扩展模块;
- 自定义模块,模块名一定符合变量名的规范
导入多个模块:一行导入一个(规范)
导入顺序:内置模块;第三方;自定义(规范)
导入模块发生了:
- 开辟以模块命名的内存空间
- 执行模块内代码,生成变量字典
重复导入无效果:第一次导入后就将模块名加载到内存,重复导入仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句。sys.modules是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
不要循环导入
2 . 导入方式:
导入方式大致分为导入func和moudle两类,两者差距不大:都在全局命名空间增加相应的名称;两者都会执行moudle中的执行语句
- import moudle_name (as xxx)
- from package import moudle_name (as xxx)
- from moudle_name import func (as xxx)
- from package.moudle_name import func (as xxx)
from moudle_name import func (as xxx) 的本质是在当前文件的全局变量中加入func名,然后指向moudle_name中的func
#myfile.py #注意文件名符合变量规范 print('the beginning') a = 100 def func(): print(a) #myfile2.py from myfile import func # 该func只是函数名,内存地址还是指向上式中的func a = 200 func()
the beginning;100 #还是会执行导入模块中的语句
3.__name__
3.1 __name__介绍
内置变量,返回当前模块(不是类和函数)的命名空间
文件执行的两种方式:
- 以模块形式导入
- 在pycharm或cmd中以脚本方式直接运行
应用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
全局变量__name_:
- 当文件被当做脚本执行时:__name__ 等于'__main__'
- 当文件被当做模块导入时:__name__等于模块名
3.2 sys.moudles[__name__]和sys.moudles[‘__main__’]区别
反射自身模块(导入模块或者主程序)内容的写法:
getattr(sys.moudles[__name__],func_name),而不是getattr(sys.moudles[‘__main__’],func_name)
__name__是个内置变量,'__main__'是个字符串
#mylife.py
print('the beginning') import sys print(__name__) print(sys.modules['__main__'])
print(sys.moudles[__name__]) #因为__name__是个变量,在sys.moudles应该查询字符串‘__mylife__’
#mylife2.py import mylife import sys print(__name__) print(sys.modules['__main__']) #获取当模块 print(sys.moudles[__name__])
the beginning #导入的文件自动执行 mylife #作为模块导入时,显示模块名 <module '__main__' from 'E:/2019allstark/practice1/1/a002.py'> #模块中的sys.moudles其实主程序的信息 <module 'mylife' from 'E:\\2019allstark\\practice1\\1\\mylife.py'>
__main__ <module '__main__' from 'E:/2019allstark/practice1/1/a002.py'>
<module '__main__' from 'E:/2019allstark/practice1/1/a002.py'>
4. 查找路径
根据模块名寻找顺序:内存中已经加载的模块->内置模块->sys.path路径中包含的模块(第三方模块在此处);内存、内置、path
自定义模块切勿与内置模块重名
['E:\\2019allstark\\practice1\\mylife', #当前目录路径,windows中使用\\表示路径分隔符防止转义
'E:\\2019allstark\\practice1', #当前项目路径
'D:\\PyCharm 2019.1.1\\helpers\\pycharm_display',
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37\\python37.zip',
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37\\DLLs',
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37\\lib', #部分内置模块,还有一些内置模块由C编写,看不到源码
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37',
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages', #第三方模块
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\win32',
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\win32\\lib',
'C:\\Users\\matt\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\Pythonwin',
'D:\\PyCharm 2019.1.1\\helpers\\pycharm_matplotlib_backend']
如果导入模块不在sys.path里面,可以用sys.path.append('你要导入的绝对路径')加入。
import sys, os print(os.path.dirname( os.path.abspath(__file__))) #获取当前文件目录或文件的绝对路径 sys.path.append(os.path.dirname( os.path.abspath(__file__)))
5. 包
包就是含有__init__文件的目录,导入包的本质就是执行包下的__init__文件。切记,包的查找路径包含当前目录和项目目录,项目目录一般定义为:base_path
注意事项:
- 凡是在导入时带点的,点的左边都必须是一个包,否则非法;
- 包A和包B下有同名模块也不会冲突,如A.a与B.a来自两个命名空间(不推荐)
绝对导入:
- 从项目目录或根目录开始导入;
- 绝对路径增删后修改繁琐
相对导入:
- 从当前目录导入(sys.path含有当前目录);使用 . 或者 .. 导入。符号 . 代表当前目录,..代表上一级目录,...代表上一级的上一级目录
- 本文件不能以脚本执行,只能以模块导入的方式执行
自定义导入:
执行文件使用绝对导入较繁琐,使用内置变量__file__构造项目目录,__file__返回当前文件路径
import os,sys print(__file__) ret = __file__.split('/') ret = ret[:-2] base_path= '/'.join(ret) # base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #(推荐此方法);os.path.dirname(),返回目录名;os.path.abspath()返回绝对路径; sys.path.append(base_path)
E:/2019allstark/practice1/path1/a1.py #file在pycharm返回绝对路径,在cmd返回相对路径
参考:__file__返回路径解析
https://www.cnblogs.com/jyfootprint/p/9429346.html
二 正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern)。
将正则表达式放到带匹配字符串从头到尾一一匹配。
1. 正则基础
1.1 字符组
在一个字符的位置上允许出现字符的组合,字符组表示的是一个字符的位置。
| 字符组 | 举例 | 说明 |
| 枚举 | [0123456] | 内部是or的关系 |
| 范围 | [1-9] | - 表示范围匹配 |
| 组合 | [1-9abcA-Z] | 只能检测 - 左右两边各一个字符,进而确定范围 |
1.2 元字符
简化字符组的写法
| 元字符 | 匹配内容 | 元字符 | 匹配内容 |
| . | 除换行符(\n)以外的任意字符 | ^,\A | 开始 |
| \d | 数字 | $,\Z | 结尾 |
| \w | 数字、字符、下划线 | a|b | a或b(优先匹配a;a、b相似,a长) |
| \s | 空格、\n、\t | () | |
| \D | 非数字 | [...] | 字符组 |
| \W | 非(数字、字符、下划线) | [^...] | 非 |
| \S | 非(空格、\n、\t) | ||
| \n | 换行符 | ||
| \t | 制表符 | ||
| \b | 边界(开始、结尾、空格) |
1.3 量词
量词只作用于前边一个元字符
| 量词 | 含义 |
| * | 重复0次或多次 |
| + | 重复1次或多次 |
| ? | 出现0次或1次(可有可无) |
| {n} | 重复n次 |
| {n,} | 重复至少n次 |
| {n,m} | 重复n到m次 |
贪婪匹配:匹配尽可能多的内容,程序默认,采用回溯算法;
惰性匹配:匹配尽可能少的内容,调用方法为在量词后边加一个问号?
转义符:只会对\\起作用
mm = "c:\\ab\\bc\\cd\\" print(mm) mm = r"c:\\ab\\bc\\cd\\" print(mm) mm = "c:\\\ab\\bc\\cd\\" print(mm) mm = r"c:\\\ab\\bc\\cd\\" print(mm) # mm = r"c:\\ab\\bc\\cd\" # print(mm) # mm = "c:\\ab\\bc\\cd\" # print(mm)
2. 常用方法
2.1 re.finall(pattern, string)
以列表的形式返回匹配到的值
2.2 re.search(pattern, string);
以对象的形式返回匹配到值,只会匹配字符串第一个值,配合result.group()查看,匹配不到返回None
2.3 re.match(pattern, string)
完全等效于re.search(^str)
2.4 re.sub(pattern, repl, string, count=0)
相当于字符串的replace方法,返回值为修改后的字符串
2.5 re.sub(pattern, repl, string, count=0)
返回值是元组:(str,n),n表示替换的次数
2.6 re.split(pattern, string)
相当于字符串的split,返回值为列表
2.7 re.comfile(pattern)
将正则模式存储在result中,允许多次调用,节省时间
2.8 re.finditer()
将匹配结果存储在可迭代对象中,一般使用for循环调用
import re
print(re.findall('\d+', '123matt456logan'))
print(re.search('\d+','123matt456logan').group())
print(re.match('\d+','123matt456logan'))
print(re.sub('\d+','AAA','123matt456logan'))
print(re.subn('\d+','AAA','123matt456logan'))
print(re.split('\d+','123matt456logan'))
ret = re.compile('\d+')
print(ret)
print(ret.findall('123matt456logan'))
print(re.finditer('\d+', '123matt456logan'))
['123', '456']
123
<re.Match object; span=(0, 3), match='123'>
AAAmattAAAlogan
('AAAmattAAAlogan', 2)
['', 'matt', 'logan'] #分割时会产生空字符
re.compile('\\d+')
['123', '456']
<callable_iterator object at 0x00000000027C89E8>
3. 分组
使用分组会产生诸多特性
3.1 re.findall()分组特性
分组部分优先显示,经常配合‘’或 |‘’用于优先显示
import re
print(re.findall('\d+\w', '123matt456Logan'))
print(re.findall('\d+(\w)', '123matt456Logan'))
print(re.findall('\d+(?:\.\d+)|\d+', '12-252+26-3*89/25-25.36*56+5.25'))
print(re.findall('\d+(?:\.\d+)|(\d+)', '12-252+26-3*89/25-25.36*56+5.25'))
['123m', '456L']
['m', 'L']
['12', '252', '26', '3', '89', '25', '25.36', '56', '5.25']
['12', '252', '26', '3', '89', '25', '', '56', ''] #没显示部分为空白
3.2 re.search() 分组特性
实现括号的定位显示
print(re.search('\d+\w+', '123matt-456Logan'))
ret = re.search('\d+(\w)(\w)(\w)', '123matt-456Logan')
print(ret.group(0));print(ret.group(1));print(ret.group(2));print(ret.group(3)) #定位括号
123mat; m; a; t #result.group(int = 0)
3.3 re.split()分组特性
显示分割内容
print(re.split('\d+', '123matt-456Logan'))
print(re.split('(\d+)', '123matt-456Logan'))
['', 'matt-', 'Logan']
['', '123', 'matt-', '456', 'Logan']
3 4 分组命名
print(re.search('<\w+>\w+</\w+>', '<h1>abcdef</h1>').group())
ret = re.search('<(?P<id1>\w+)>\w+</(?P=id1)>', '<h1>abcdef</h1>') #分组关键字形式
print(ret.group()) #全部显示
print(ret.group(1))
# print(ret.group(2)) #报错,分组命名前后()表示一个
print(ret.group('id1')) #显示对应名称的分组()内容
res = re.search(r'<(?P<id1>\w+)>\w+<(/\1)>', '<h1>abcdef</h1>') #分组位置形式
<h1>abcdef</h1>
<h1>abcdef</h1>
h1; h1
三 time模块
1. 时间形式
- timestamp:时间戳,从1970年1月1日00:00:00开始按秒计算,北京时间为从8时开始计算;
- struct_time:时间元组,共有九个元素组;
- format time :格式化时间,已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
1.1 时间戳
生成函数:time.time()
print(time.time()) #1567067674.6788714,从1970年1月1日08:00:00计算的秒数
1.2 时间元组
伪生成函数:time.localtime(seconds=None);When 'seconds' is not passed in, convert the current time instead.
print(time.localtime()) #返回值为struct_time对象格式 print(time.localtime().tm_year) time.struct_time(tm_year=2019, tm_mon=8, tm_mday=29, tm_hour=18, tm_min=29, tm_sec=14, tm_wday=3, tm_yday=241, tm_isdst=0) 2019
属性 值 tm_year(年) 比如2017 tm_mon(月) 1 - 12 tm_mday(日) 1 - 31 tm_hour(时) 0 - 23 tm_min(分) 0 - 59 tm_sec(秒) 0 - 61 tm_wday(weekday) 0 - 6(0表示周日) tm_yday(一年中的第几天) 1 - 366 tm_isdst(是否是夏令时) 默认为-1
1.3 格式化字符串时间
伪生成函数:time.strftime(format,p_tuple=None);When the time tupleis not present, current time as returned by localtime() is used.
print(time.strftime('%Y-%m-%d %X')) 2019-08-29 18:09:27
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
2. 三种格式转化
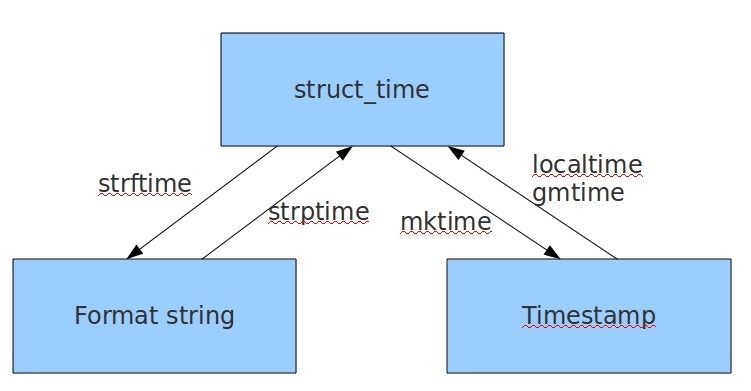
1、time.localtim(seconds=None)
返回时间戳的struct_time格式;
2、time.mktime(p_tuple)
将struct_time格式转成时间戳;
3、time.strftime("%Y-%m-%d %H:%M:%S",p_tuple=None )
将struct_time格式转成指定的字符串格式
4、time.strptime("2016/05/22","%Y/%m/%d")
将日期字符串转成 struct_time格式
import time print(time.time()) print(time.localtime(1500000000)) print(time.strftime('%Y-%m-%d')) print(time.strptime('2019-08-30','%Y-%m-%d')) #'%Y-%m-%d'为'2019-08-30'的识别模式 1567076841.7220666 time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) 2019-08-29 time.struct_time(tm_year=2019, tm_mon=8, tm_mday=30, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=242, tm_isdst=-1)
时间差练习:只有时间戳能加减
import time true_time=time.mktime(time.strptime('2018-09-11 08:30:00','%Y-%m-%d %H:%M:%S')) time_now=time.time() dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec))
过去了0年11月18天10小时42分钟25秒
3. 固定格式转化
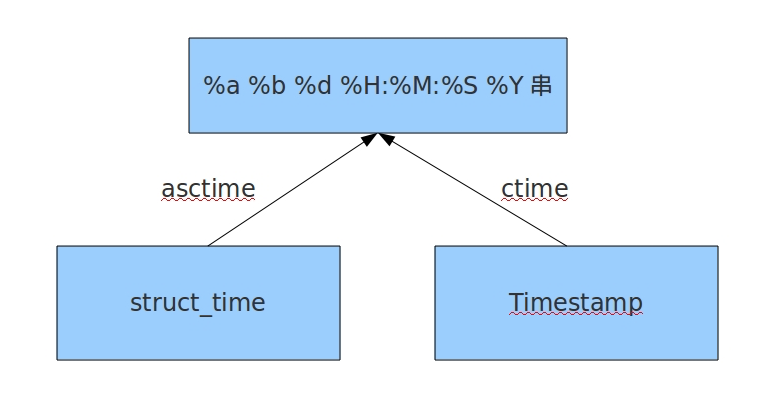
5、time.ctime(second=None)
转化为C格式字符串
6、time.asctime(p_tuple=None)
与time.strftime类似,转化为C格式字符串
import time print(time.ctime()) print(time.asctime()) Thu Aug 29 19:21:33 2019 #西方习惯的格式 Thu Aug 29 19:21:33 2019
四 datetime模块
datetime模块封装了time模块,提供更多接口,内部的类有:date,time,datetime,timedelta,tzinfo。
1. date类
def __init__(self, year: int, month: int, day: int),提供日期的操作
1、obj = date(2017,8,8)
初始化函数,创建date类型的对象
2、date.today()
返回当前本地日期
3、date.fromtimestamp(timestamp)
返回时间戳的日期
4、date.strftime(format)
返回自定义格式的时间字符串
5、replace(year, month, day):
生成一个新的date对象,指定参数替换
2. time类
def __init__(self, hour, minute, second, microsecond, tzinfo)
6、datetime.time()
初始化函数
7、time_obj. hour/min/sec/micsec()
返回小时/分钟/秒/毫秒
8、time_obj. isoformat()
返回型如"HH:MM:SS"格式的字符串表示
3. datetime类
封装time模块
4. timedelta类
9、timedelta(days,hours,minutes,second,microseconds,weeks)
初始化函数
10、timedelta_obj. days/secons/microseconds()
返回天数、秒、毫秒,没有小时,分钟
加减操作
- datetime_obj = datetime_obj +/- timedelta_obj
- timedelta_obj = datetime_obj - datetime_obj
date与datetime对象都可进行加减操作
import datetime t1 = datetime.datetime.now() delta = datetime.timedelta(weeks=1) #默认为days=1 print(t1 + delta) t3 = datetime.datetime(2019, 12, 26, 10, 10, 10) print(t3 - t1);print((t3 - t1).days) 2019-09-06 12:44:34.275388 117 days, 21:25:35.724612; 117
参考:datetime模块详解
https://www.cnblogs.com/xtsec/p/6682052.html
五 random模块
1. 整数
1、random.randint(1,6) 随机生成指定范围 [a,b] 的整数
2、rangdom.randrange(1,100,2) 随机生成指定范围 [a,b] 的整数,步长为2
2. 浮点数
3、random.random() 随机生成指定范围 [0,1) 的浮点数
4、random.uniform(a,b) 随机生成指定范围 [a,1) 的浮点数
源码 a + (b-a) * self.random()
3. 抽取
5、random.choice(seq) 随机抽取元素
Some built-in sequence types are list, str, tuple and bytes
6、random.sample(Population,k) 随机抽取k个元素
Population must be a sequence or set. For dicts, use list(d)
4. 打乱
7、random.shuffle(list) 随机打乱顺序
return None
#随机验证码实例
import random check_code = '' for i in range(4): cur = random.randrange(0,4) #随机猜的范围,与循环次数相等 #字母 if cur == i: tmp = chr(random.randint(65,90)) #数字 else: tmp = random.randint(0,9) #randint包含最后一位 check_code += str(tmp) print(check_code)
六 os模块
1 基本方法
os模块是与操作系统交互的一个接口
# 当前执行这个python文件的工作目录相关的工作路径
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径;与(__file__)返回的文件路径不相同
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
# 和目录相关
os.makedirs(name,exit_ok=False) 可生成多层递归目录,最底层目录存在时报错;
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印,不向下二级递归搜索
# 和文件相关
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息,返回对象
# 和操作系统差异相关
# os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
# os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
# os.pathsep 输出用于分割文件路径的字符串,在环境变量中; win下为;,Linux下为:
# os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
# 和执行系统命令相关
os.system("bash command") 运行shell命令,直接显示,不能保存结果
os.popen("bash command).read() 运行shell命令,获取执行结果;返回对象,以read()打开
os.environ 获取系统环境变量
# path系列,和路径相关
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录;os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略;自动添加分隔符
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回文件的大小
os.urandom(int) 返回int位的bytes
os.getpid() 返回进程的号
os.getppid() 返回父进程号
os.stat('path/filename') 获取文件/目录信息 的结构说明
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
2. 获取文件夹大小
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向下递归。
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
-
top -- 是你所要遍历的目录的地址, 返回值是一个三元组(root,dirs,files)。
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
-
topdown --可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
-
onerror -- 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
-
followlinks -- 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
import os def getdirsize(dir): size = 0 for root, dirs, files in os.walk(dir): size += sum([os.path.getsize(os.path.join(root, name)) for name in files]) #生成列表再相加 return size if __name__ == '__main__': size = getdirsize(os.getcwd()) print('There are %.3f Mb' %(size/1024/1024)) #保留小数的位数
七 sys模块
与python解释器交互的命令
sys.argv 命令行参数List,第一个元素是程序本身路径,例如cmd中输入mysql -uroot -ppwd;sys.argv[0]='mysql'; sys.argv[1]='-uroot'; sys.argv[2]='-ppwd' sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
八 json & picle模块
json 和 pickal模块都只有四个方法: dumps、dump、loads、load
1. json四种方法
JSON (JavaScript Object Notation)是一种使用广泛的轻量数据格式,主要用于数据交互。json和js对象格式一样,字符串中的属性名必须加双引号其他得和js语法一致。
json生成的数据存在于内存,需要write和read进行存储和读取。
JSON和Python之间的数据转换对应关系如下表:(不支持set)
| JSON | Python |
|---|---|
| object | dict |
| array | list、tuple |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
json方法大致分为:
- 网络传输:dumps、loads
- 文件读写:dump、load
1.1 dumps(obj)、dump(obj,fp)
用于将 Python 对象编码成 JSON 字符串
1.2 loads(obj)、load(fp)
用于解码 JSON 数据;返回 Python 字段的数据类型
import json dic = {'a': 1, 'b': 2} dic_json = json.dumps(dic) print([dic_json]) #print([ ])加上[]为真实打印,附带数据类型 dic_new = json.loads(dic_json) print([dic_new]) with open('file', 'w')as f: json.dump(dic, f) with open('file')as f2: aaa = json.load(f2) print([aaa])
['{"a": 1, "b": 2}'];[{'a': 1, 'b': 2}];[{'a': 1, 'b': 2}]
1.3 格式化显示
import json data = {'username': ['李华', '二愣子'], 'sex': 'male', 'age': 16} #针对字典类型 json_dic2 = json.dumps(data, sort_keys=True, indent=2, separators=(',', ':'), ensure_ascii=False) #ensure_asscii = True显示Unicode编码,不显示汉字 print(json_dic2) { "age":16, "sex":"male", "username":[ "李华", "二愣子" ] }
2. json限制
2.1 json转化字典时, keys must be str, int, float, bool or None
key不接受元组,且数字必须字符串化
元组在做value时,会被转换为list
2.2 双引号
json生成和导入字符串时必须是双引号
2.3 文件允许多次dump,不允许多次load
import json dic1 = {1: 'a', 2: 'b'} dic2 = {'c': 3, 'd': 4} with open('file', 'w') as f: # json.dump(dic1, f) 形成数据黏连,在一行中 # json.dump(dic2, f) ret1 = json.dumps(dic1) ret2 = json.dumps(dic2) f.write(ret1 + '\n') f.write(ret2 + '\n') with open('file') as f2: # json.load(f2) 不允许读取多个数据 for line in f2: ret = json.loads(line) print(ret)
{'1': 'a', '2': 'b'};{'c': 3, 'd': 4}
3. pickle特性
pickle模块是将Python所有的数据结构以及对象等转化成bytes类型,然后还可以反序列化还原回去。pickle都是bytes类型
json模块序列化出来的是通用格式,其它编程语言都认识,就是普通的字符串;pickle模块序列化出来的只有python可以认识,其他编程语言表现为乱码
pickle可以序列化函数;反序列化时,读取文件中需要有该函数的定义(定义和参数必须相同,内容可以不同)
pickle方法:
- 传输:loads(obj)、dumps(obj)
- 文件操作:load(fp)、dump(obj,fp)
3.1 pickle支持几乎所有数据类型
3.2 pickle支持序列化自定义对象和函数
3.2 pickle支持多次存储和读取
import pickle def func(): #反序列化时必须在 print('aaa') class Student: def __init__(self, name, age): #反序列化时必须在 self.name = name self.age = age s1 = Student('matt', 20) with open('file', 'wb') as f: #每次写入会有标识,二进制形式写入 pickle.dump(func, f) pickle.dump(s1, f) with open('file', 'rb') as f2: while True: try: #多次读取的格式,多次写入就多少次读取,不能一次读取 print(pickle.load(f2)) except EOFError: break <function func at 0x00000000005EC1E0> <__main__.Student object at 0x00000000027D8E48>
参考:json详细解析
https://www.jb51.net/article/139498.htm
九 hashlib模块
1. 模块介绍
此模块通过一个函数,把任意长度的数据转换为一个固定长度的数据串,又称为摘要算法,加密算法,哈希算法,散列算法等等,算法有md5, sha1, sha224, sha256, sha384, sha512。
md5是常用的算法,主要是速度快。
import hashlib md5 = hashlib.md5() #创建md5对象 md5.update('how to use md5 in python hashlib?'.encode()) md5.update(b'haha') #update的数据必须是bytes print(md5.hexdigest())
#文件读取 def file_check(file_path): with open(file_path,mode='rb') as f1: sha256 = hashlib.sha256() while 1: content = f1.read(1024) if content: sha256.update(content) else: return sha256.hexdigest()
2. hmac
基本与hashlib用法一致,在加salt时方便一点
import hmac message = b'Hello, world!' key = b'secret' h = hmac.new(key, message, digestmod='MD5') # 如果消息很长,可以多次调用h.update(msg) print(h.hexdigest())
十 logging模块
logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级、日志保存路径、日志文件回滚等;相比print,具备如下优点:
- 可以通过设置不同的日志等级,只输出重要信息,而不必显示大量的调试信息;
- print将所有信息都输出到标准输出中(screen);logging则可以设置信息输出的文件和格式;
1. 函数式配置
该方法简单,但定制型差:只能屏幕或文件输出一种、没有encode()选项,文件显示中文乱码
import logging logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', filename='file' #没有改语句时、屏幕显示,没有encoding选项 level=logging.ERROR #输出等级,一般都是INFO等级 ) logging.error('你好')
2019-08-31 11:45:03 AM - root - ERROR -test100: ��� #文件输出中文乱码
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 #level = logging.DEBUG stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 handles:
没有encoding选项,只能以ANSI(本地字符编码)输出
format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
输出等级
FATAL:致命错误
CRITICAL:50,特别糟糕的事情,如内存耗尽、磁盘空间为空,一般很少使用
ERROR:40,发生错误时,如IO操作失败或者连接问题
WARNING:30,发生很重要的事件,但是并不是错误时,如用户登录密码错误
INFO:20,处理请求或者状态变化等日常事务
DEBUG:10,调试过程中使用DEBUG等级,如算法中每个循环的中间状态
2. 对象配置
import logging logger = logging.getLogger() #1、创建一个logger对象 fh = logging.FileHandler('file_name',encoding='utf-8') #2、创建一个文件管理操作符 #函数配置没有encoding选项 sh = logging.StreamHandler() #3、创建一个屏幕管理操作符 #4、创建一个日志输出的格式 fm1 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') fh.setLevel(logging.DEBUG) #5、设置输出等级 fh.setFormatter(fm1) #6、文件管理操作符绑定一个格式 sh.setFormatter(fm1) #7、屏幕管理操作符绑定一个格式 logger.addHandler(fh) #8、logger对象绑定文件管理操作符 logger.addHandler(sh) #9、logger对象绑定屏幕管理操作符 logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message') #屏幕和文件同时输出
参考:logging模块解析
https://www.cnblogs.com/liujiacai/p/7804848.html
十一 异常处理
1. 异常基础
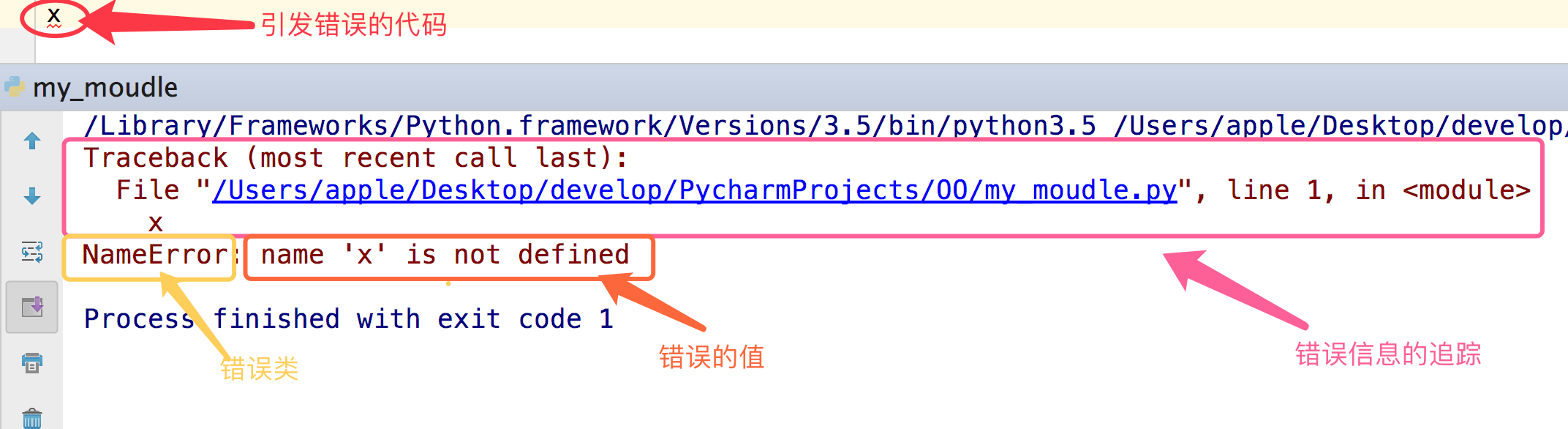
常见的异常:
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量, 导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
2. 异常处理语句
发生异常后,会执行exit(),直接退出程序
异常处理只能处理指定、有限的异常,因为异常类的数量是一定的。
2.1 try/except
基础语法,最常用
try: a = [1, 2] b = a[5] #发生异常 except (ValueError,IndexError) as e: #多状况,发生任何一种都触发 print(e) print('aaa') #发生错误,能够执行
list index out of range;aaa
发生错误后只是try中的程序不再执行,而执行except中的语句,之后再执行主程序。即使发生错误,下端的主程序也能执行。
2.2 try/except/else
类似于for/else语句:for正常走完能执行else语句,若for内部有break,则不执行else语句
try: a = [1, 2] b = a[1] except IndexError as e: print(e) else: #未发生错误,执行else,发生错误,不执行else print('aaa') print('bbb')
aaa;bbb
2.3 try/except(/excepy)/finally
不管是否发生错误,都会执行finally语句,比下端主程序更安全
try: a = [1, 2] b = a[3] except IndexError as e:print(e) else:print('aaa') finally:print('bbb')
aaa;bbb
3. Exception
万能异常,Exception包含了所有的异常类
try: a = [1, 2] b = a[3] except Exception as e: #不用指定异常类的类名,方便一些,但一定打印信息 print(e)
4. raise
主动抛出异常,能改写异常类的具体信息
try: a = [1, 2] b = a[3] # raise ValueError('aaa') #这样抛出异常会打印aaa except Exception as e: print(e) raise #源码中常见,原封不动抛出异常
list index out of range
Traceback (most recent call last):
File "E:/2019allstark/soft/core/test100.py", line 3, in <module>
b = a[3]
IndexError: list index out of range
5. 自定义异常
class EvaException(Exception): def __init__(self, msg): self.msg = msg def __str__(self): return self.msg try: raise EvaException('类型错误') except EvaException as e: print(e)
6. assert
源码中个经常出现,assert只有True和False,主要判断源码中继续执行的条件是否准备好。
assert True #ture继续往下走 print('aaa') assert 0 #false报错 print('bbb')
aaa
Traceback (most recent call last):
File "E:/2019allstark/soft/core/test100.py", line 3, in <module>
assert 0
AssertionError
