C语言代码区错误以及编译过程
C语言代码区错误
欲想了解C语言代码段会有如何错误,我们必须首先了解编译器是如何把C语言文本信息编译成为可以执行的机器码的。🌞🌞🌞🌞
背景介绍
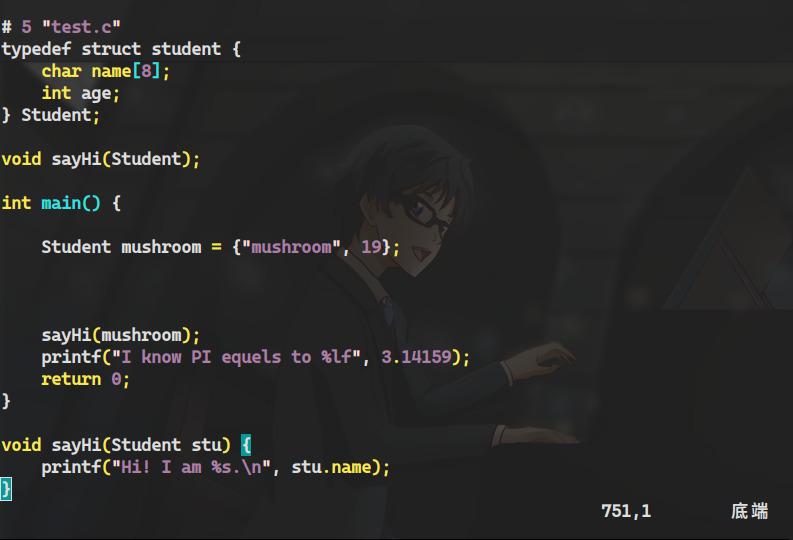
- 测试使用的C语言代码
- 导入标准库,定义宏变量,定义结构体,重命名结构体,
- 函数原型声明,主函数入口,函数定义
#include <stdio.h>
#define PI 3.14159
typedef struct student {
char name[8];
int age;
} Student;
void sayHi(Student);
int main() {
// we define a Student structure here.
Student mushroom = {"mushroom", 19};
/*
Output some massage.
*/
sayHi(mushroom);
printf("I know PI equels to %lf", PI);
return 0;
}
void sayHi(Student stu) {
printf("Hi! I am %s.\n", stu.name);
}
- C语言编译基本流程

- 一共划分为了文件输入,预处理,编译,汇编,连接,最后输出为可执行文件。GCC正好就为我们提供了所有的这些方法,下面来一一介绍下
GCC内置的处理C语言文件的指令。 GCC编译器基本指令了解
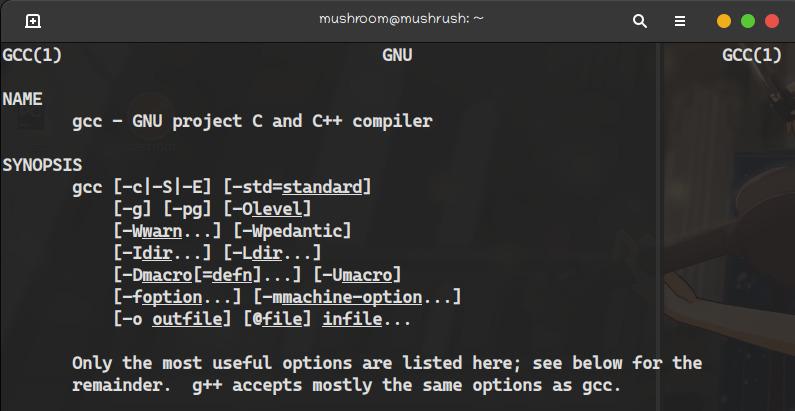
| 指令名 | 解释 |
|---|---|
gcc -c |
编译或汇编源文件,但是不作连接.编译器输出对应于源文件的目标文件. |
gcc -S |
编译后即停止,不进行汇编.对于每个输入的非汇编语言文件,输出文件是汇编语言文件. |
gcc -E |
预处理后即停止,不进行编译.预处理后的代码送往标准输出. |
gcc -o filename |
指定输出文件为file.该选项不在乎GCC产生什么输出,无论是可执行文件,目标文件,汇编文件还是 预处理后的C代码. |
这里只是给出了gcc最常见的指令,如果还想了解更多的细节可以查看下官方文档.这里给出国内维护的GCC中文手册
如上的GCC相关指令给出了一整套处理C语言文件的完整方法,下面使用来完整的按流程编译下C语言文件。
预处理阶段(preprocessing)
再看一眼
test.c文件

使用gcc -E filename > outputFilename预处理文件
gcc -E test.c
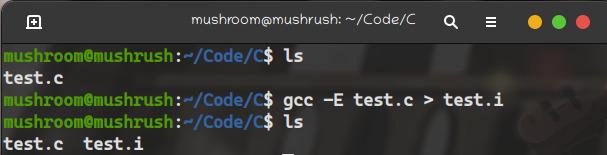
将信息输出到test.i文件之中
原本只有二十五行的代码,一下子被扩张到了751行
基本数据类型的重新定义

标准输入输出函数

外部函数
test.c代码段
这里说的代码段不准确,代码段是整个代码,这里是特指
test.c中手动写入的代码区
预处理后效果分析
- 插入了头文件信息
- 宏消失,发生了宏替换
- 注释删除

编译阶段(compilation)
使用gcc -S filename
gcc -S test.i
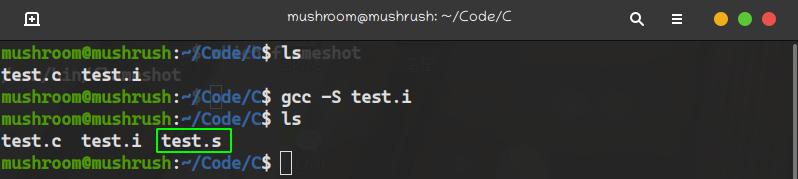
编译生成了
test.s文件,只是一个汇编代码文件借助汇编代码翻译为机器码
汇编代码

讨论汇编代码已经超过了本次讨论的内容,这里附上一篇讲解汇编的文章汇编代码,里面正对于计算机内存,与CPU的关系阐释的相当清楚,各位有时间可以看看。
可以从汇编代码的一些细节处看出来,这汇编代码实际上是原
test.c向汇编语言的翻译,像C语言这样计算机编程语言实际上是高级语言,简单来说是给人看的,语法等等各个方面的都适用于人类去阅读,但是计算机是无法理解的。计算机只能理解0和1,二进制, (最开始电子计算机刚刚被发明出来的时候,程序员们编程就是使用的手动输入01二进制指令的方法编程的),带有特定功能的二进制码被称为指令,指令的集合被称为指令集,(这也正是当前中国被卡脖子的地方)汇编语言是机器码的封装,每一个汇编指令都对应与一个机器码,这也是为什么汇编语言被成为低级语言。
梳理下编译阶段
我们不去考察
GCC是如何巴拉巴拉变出这一堆看不懂的汇编代码,但我们应当明白,C语言是想把自己转化成为汇编码然后直接交给CPU,我们可以这么理解C语言是汇编语言的重构封装,使得,而编译器就好像是翻译器。大致理解为如下流程。

汇编阶段(assembly)
gcc -c filename
gcc -c test.s
汇编阶段是汇编语言向机器码转化的过程,可以理解为汇编语言的编译过程。

强行读取一下

虽然基本上是乱码,但是其中还是有不少的部分如
I know PI equels to %lf等等字符串类型的数据可以被显示出来。但是此程序还无法交给CPU计算,还缺少最后一步连接(link)

连接阶段(link)
gcc filename -o targetname
-o选项实际上可以处理很多种类的中间文件,如果没有使用`-o'选项,默认的输出结果是:可执行文件为`a.out', `source.suffix '的目标文件是`source.o',汇编文件是 `source.s',而预处理后的C源代码送往标准输出.
gcc test.o -o test
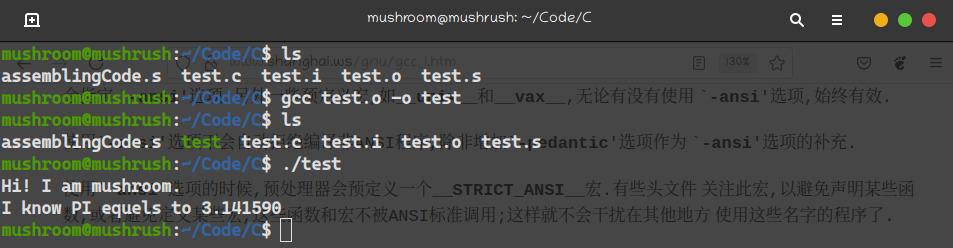
最终的阶段终于得到了真正的目标文件,完成了一次人机的简单交互。
但是这个
gcc -o实际上给出的很暧昧,这个过程中实际上是把我们自己写好的程序与存储在硬盘的库文件连接,比如说printf()函数,并没有定义它,但是却可以使用,这是由于上述操作与标准库建立了连接.
!!!注意!!!,所有的可执行程序必须放在CPU中才可以运行!!****
举个例子也许会好理解一些:
你们全家人要出去郊游,你跟妈妈说我要吃大雪糕,妈妈答应给你准备。
你把你的想法传达给了妈妈,你们一起建立起了一个约定,可以理解为上述汇编阶段产生的未连接的可执行文件
妈妈答应了你的约定,可是,如何去履现和你的承诺呢?
在郊游地点周围现买.(假设郊游地点周围一定有)
在家里就准备好,打包一起带走到郊游地点.
这导出了两种不同的连接方式:
- 静态连接:一起打包好,我要的我都准备好。(对应于上述的在家里准备雪糕)
- 动态链接: 我暂时不准备,但是我知道,它雪糕就在那儿,所以等到了之后在动态的把它拿过来执行。
很容易想到动态链接的文件体积会相对来说少很多,但是可移植性差点。
反思
真正的可执行的程序在经过预处理,编译,汇编,连接相关库文件。最终形成了程序的最终形态,当次文件执行的时候,立马从硬盘读取到了内存中,然后立马放置到CPU进行计算。
如何避免代码段出现内存错误呢?
代码段,是存放指令集的,所以我列举出了以下几个方面可能造成的错误.
1. 阻止C文件翻译为汇编代码 2. 阻止库连接,或者库连接失败
阻止C文件翻译为汇编代码:
#include <stdio.h>
int mian() {
printf("Mushroon!!!!\n");
return 0;
}
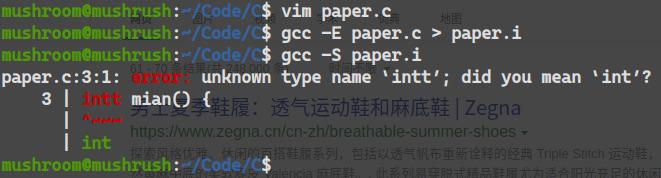
如上代码,故意将函数入口main写成mian``int写成intt
虽然我们已经尽力的想去迫害C语言的编译器,可是它还是认真的指出了我们的恶劣行经。
预处理完全没问题,编译阶段出现了问题,失败了,超出了C语言编译器可以理解的符号系统
阻止库连接
回到上面给出的一家人郊游你却想吃雪糕的例子,当你提出吃雪糕的时候,你妈妈给你一大耳巴子,说"吃什么吃!不给吃!!",这就是阻止了库的连接。自然无法完成你想要吃雪糕这件事了。
总结
实际上本文没有得到什么比较深刻的结论。
目前随着编译器越来越完善,各大IDE(集成式编程环境)越来越强大,语义分析,自动查询语法错误,还能在不编译的时候察觉出想C语言编译器无法查出的问题:如数组访问越界。
这些工具的出现使得编程时代码准确无误的被翻译成为机器码,确保可以执行,让程序员更注重于程序的功能上,是否准确?是否有效?这也是时代的一大进步吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号