
案例分析:数据计算系统频发fullgc
一、背景
数据计算系统,日处理数据量在上亿的规模; 简单来说就是不停的从各种存储中读取大量数据在内存中进行计算处理,大致每分钟执行500次数据提取和计算任务
总共5台机器,那么每台机器每分钟大概负责100次数据提取和计算,每次提取 1万条数据,平均计算耗时10秒
二、GC过程分析
机器配置4C8G, 堆3G、年轻代1.5G、老年代1.5G
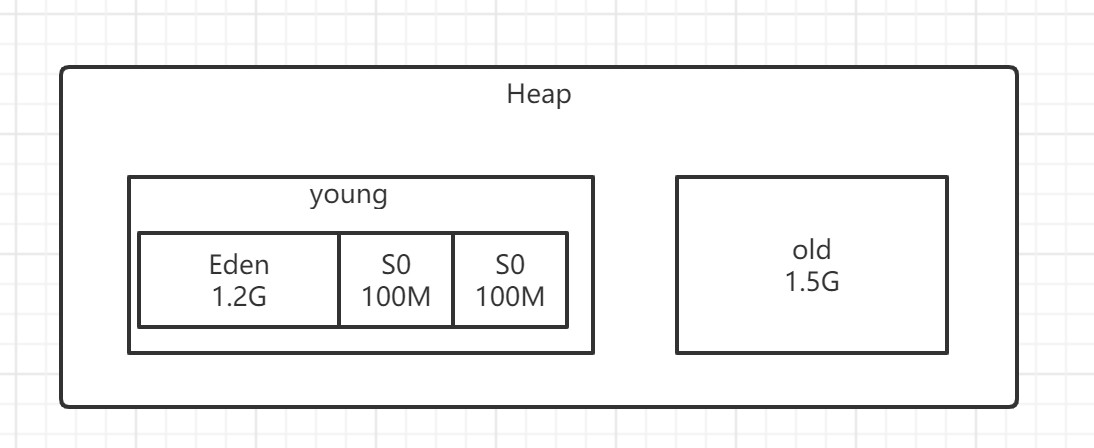 数据分析的每条数据比较大,20个字段,平均大小在1kb,那么每次计算的1万条数据为 10MB 大小
数据分析的每条数据比较大,20个字段,平均大小在1kb,那么每次计算的1万条数据为 10MB 大小
新生代多快会塞满?
执行一次产生10m 对象,一分钟执行100次, 10m * 100 大概1G,加上其他系统对象 eden区就被塞满
触发minor gc后有多少对象晋升老年代
一分钟后,进行一次 minor gc,假设有80个计算任务执行完毕了,还有20个任务还没执行完毕 此时存活对象有 200M,survivor 放不下,只能进入老年代
老年代多久会塞满,进行full gc?
每次 minor gc 有200m的对象进入老年代,当进行第七次minor gc 后, 老年代就只剩100m了,然后当发生第8次 minor gc 的时候由于空间担保 老年代不足以存放历次 minor gc晋升的对象大小,就要先进行 full gc; 也就是平均 8分钟进行一次 full gc,频率非常高
三、如何优化?
按照现有的 内存分配,最大的问题是 每次minor gc 的时候 survivor 区都不够存放存活对象,导致全部晋升到老年代;
调整内存比例 3G的堆内存,2G年轻代(Eden 1.6G、 Survivor 200MB * 2) + 1G老年代
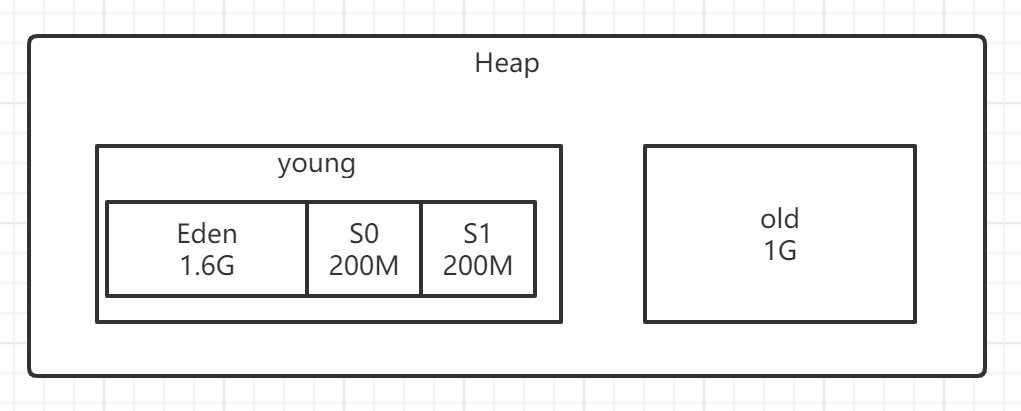 这样每次 minor gc 基本就很少进入老年代 大大降低了 full gc 的频率
这样每次 minor gc 基本就很少进入老年代 大大降低了 full gc 的频率
但是还要注意 “动态年龄判断”,回收后 survivor区域 同龄对象超过其一半,就要直接进入老年代 还可以通过 -XX:survivorRatio=8 进行调整,降低eden区的比例
本文来自博客园,作者:mushishi,转载请注明原文链接:https://www.cnblogs.com/mushishi/p/14550841.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号