
用CIL写程序:你好,沃尔德
前言:
项目紧赶慢赶总算在年前有了一些成绩,所以沉寂了几周之后,小匹夫也终于有时间写点东西了。以前匹夫写过一篇文章,对CIL做了一个简单地介绍,不过不知道各位看官看的是否过瘾,至少小匹夫觉得很不过瘾。所以决定写几篇关于CIL的文章,即和各位看官一起进行个交流,同时也是匹夫自己总结和巩固一下这些知识点。俗话说的好,“万事开头,Hello World”,那么作为匹夫总结CIL的第一篇文章,就从Hello World开始吧。当然,正式开始写CIL代码之前,我们还有点闲话要说,那就是运行时的选择为何是它?为何是CIL?而CIL为何又是基于堆栈的?内存或者寄存器难道不是更理想的选择吗?
为何是CIL?
开始正文内容之前,匹夫带领大家先回顾一下《Mono为何能跨平台?聊聊CIL(MSIL)》的简要内容:首先,用C#写的代码被C#的编译器编译成CIL(当然除了C#还有很多其他的语言,比如VB等等),之后再有JIT编译器在程序运行时即时编译或者AOT(或者NGEN)进行提前编译将CIL代码编译成对应平台的机器码,最后运行在平台上的便是机器码。小匹夫在那篇文章中提过,首先将各种不同的语言都统一编译成CIL,再由CIL编译成各个平台的机器码是跨平台的基础。那么仔细想想,一定有人会提出这样的疑问,直接从C#编译到机器码,省略掉“多余”的中间语言,是不是也可行呢?这个问题的确值得讨论,同时也为了小匹夫接下来的文章师出有名,所以首先聊聊CIL的“合法性”(用必要性这个词也许更好)问题就成了匹夫写这篇文章的头等大事。
论据一:考虑下“性价比”
首先提出我们的论据一,那就是使用CIL这套体系对实现跨平台的开销要小的多的多。
引入一个“多余的”中间语言和两个编译器(C#----->CIL------>机器码)听上去总是要比只使用一种编译器(C#-------->机器码)的实现代价高的多,因为我们的目的是C#代码能编译成机器能运行的机器码,显然一步到位是最直接有效的方式。相反,引入中间语言之后,我们就需要实现两种语言的分析和编译,看上起的确多此一举。但如果我们考虑到跨平台这个前提,就会发现中间语言是多么的重要。
假设你可以选择的语言有N种(比如C#, VB, F#, JScript .NET,Boo...),而我们的目标平台有M种(win,mac,linux,ios,android...)。那么如果我们采用最直接的编译方式,即从源代码直接编译成机器码,那么到底需要多少个编译器呢?
答案很直接咯:需要N*M种编译器。因为你需要为每一种语言针对每一个平台写一个编译器。
如果我们采用了中间语言呢?
我们只需要为N种语言写N种编译器,将它编译成CIL代码。再为M种平台写M种编译器,将上一步生成的CIL代码编译成M种平台的机器码。那么这次我们到底需要多少编译器呢?
答案也很明显:需要M+N种编译器。
所以,采用中间语言要比直接编译代码的开销小的多得多。
论据二:实现的难度
假设,匹夫对硬件语言一窍不通(当然事实上是这样的。。。),但却具备一种分析源代码语义的特殊天赋(瞎掰的)。那么要实现从C#到各个平台机器码一步到位的编译,匹夫就要去啃各种目标芯片的说明,将C#代码转化成对应芯片的机器码。这听上去就像是一条不归路,因为你并不擅长这个领域而且工作量巨大,同时由于不擅长带来的隐患难以估量。
换言之,这个难度太大了。
但是如果我们通过对C#进行语义分析,能十分容易的就生成一份和芯片无关的CIL代码,那么实现的难度相比直接从C#到机器码那可是大大的降低了。因为CIL语言本身就十分简单(至少匹夫这种粗人都能看懂),所以从源代码到CIL的编译器实现就十分容易。同时,也是因为CIL语言本身十分简单,所以从CIL到机器码的编译器也十分简单。
而且即便有新的平台出现,你也不需要为每种语言都写一个针对新平台的编译器,而只需要实现一个从CIL到新平台机器码的编译器就可以了。
所以可以看到,CIL中间语言的出现,大大降低了跨平台的实现难度。
《Mono为何能跨平台?聊聊CIL(MSIL)》这篇文章中,小匹夫也给各位列举了一些CIL的代码,同时做了一些解释,文中在介绍CIL不依托cpu的寄存器时写了这样一句话:
不错,CIL是基于堆栈的,也就是说CIL的VM(mono运行时)是一个栈式机。
那么不知道各位看官是否也有这样的疑问呢?那就是~~~~~~~
为什么是栈式机?直接放在内存中不好吗?
终于要聊聊小匹夫也觉得挺有趣的一个话题了。对啊,为什么CIL基于堆栈呢?那么我们首先就来聊聊什么是“栈式机”。
假如让你来...
假如让你来设计一种机器语言,同时实现一个简单地加法功能,简单到什么程度呢?比如a+b等于c这样好了。那么思路是什么呢?
方案一:使用内存
add [a的地址], [b的地址], [结果的地址也就是c的地址]
当机器遇到add操作符时,它就会去寻找a的地址和b的地址这两个地址中存放的值,然后用balabala的方式将它们求和,并将结果存放在c的地址。
方案二:使用寄存器
当然匹夫也是一个学过汇编的汉子,也了解一点点单片机的知识,知道有一个叫做累加器的东西。累加器就属于寄存器了,它主要用来储存计算所产生的中间结果,最后将其转存到其它寄存器或内存中。所以使用累加器的思路也很简单,一开始将累加器设定为0,每个数字依序地被加到累加器中,当所有的数字都被加入后,结果才写回到主内存中。
方案三:使用堆栈
等等,这个部分介绍的不是栈式机吗?怎么感觉有点跑题呢?好吧,拉回思绪,让我们再来考虑下使用堆栈如何实现这个简单地加法功能呢?
push a
push b
add
pop c
add操作符首先将a,b弹出堆栈,然后将二者相加,再将结果压栈。那么,使用了这种方案的虚拟机,就被称为“栈式机”。
所以如果要回答为何CIL的选择是使用堆栈,那么就绕不过堆栈和另外两种方案的比较。
首先看一下我们做这种简单加法时,硬件需要为我们提供一些什么呢?对,就是存放这些值的临时空间。所谓的临时空间,就是说存储这个值的空间只有在需要这个值的时候才有用,其余的时候你并不需要关心这个空间或者说它的地址到底是什么。假设我们已经定义了一些操作符,比如Allocate用来分配内存,Call用来调用函数,Add用来求和,Store则是用来存储数据。
首先我们直接使用内存来运行CIL,那么遇到这样的表达式:
x = A() + B() + C() + 100
机器首先要为A()在内存上分配空间用来保存它的返回值,然后调用A()并将A()的返回值保存在之前分配给它的地址中,我们就管它叫做ret1好了。之后为B()在内存上分配空间来保存B()的返回值,接着调用B(),同样将B()的返回值保存在刚才分配给它的内存中,我们暂时称呼它ret2。这时,我们遇到了第一个“+”号,所以此时会为ret1和ret2相加的结果在内存上分配一个空间,并且将ret1和ret2相加,并将结果保存在刚刚分配的内存中(我们称为sum1),之后的过程以此类推。
Allocate ret1 //为A()的返回值分配临时空间ret1 Call A(),ret1 //调用A()并将结果保存在ret1 Allocate ret2 //为B()的返回值分配临时空间ret2 Call B(),ret2 //调用B()并将结果保存在ret2 Allocate sum1 //为第一次相加的结果分配临时空间sum1 Add ret1,ret2,sum1 //使用Add操作符将ret1和ret2中的内容相加,并将结果保存在sum1中。 ...
可以看到这样的CIL代码在每一步真正的逻辑执行之前,都会先在内存上分配一块临时空间,用来存储我们此时需要的数据。如果使用堆栈,这个步骤是不需要,因为你将你需要的数据存储在了堆栈之中,而非在内存上临时去分配空间。所以,使用堆栈时,CIL代码看上去也许像是这样的:

push x的地址 // 将x的地址压栈 call A() // 现在堆栈中包含x的地址和A()的返回值ret1 call B() // 现在堆栈中包换x的地址,ret1,B()的返回值ret2 add // 现在堆栈中包含x的地址,ret1 + ret2的结果sum1 call C() // 现在堆栈中包含x的地址,sum1和C()的返回值ret3 add // 现在堆栈中包含x的地址, ret1+ret2+ret3的返回值sum2 push 100 // 现在堆栈中包含x的地址,sum2,以及100 add // 现在堆栈中包含x的地址, ret1+ret2+ret3+100的和sum3 store //将sum3存在x的地址中。
同时,我们还可以看到如果CIL直接使用内存的话,由于在内存上的空间是临时分配的,所以CIL代码在运行时需要带上它的操作数地址以及返回地址,比如上例中的Add ret1,ret2,sum1,因为如果不告诉它这些地址,它就不知道该从何处得到数据,并将返回的数据放在何处。
所以直接使用内存来运行CIL代码,会使得CIL代码变得十分的臃肿不堪,而且要做很多多余的工作。所以不直接使用内存,而是使用堆栈的原因就是因为:如果我们仅仅只是为了临时存储一些值,而在使用完这些值之后我们就不再关心这块空间如何如何,显然使用堆栈要比直接使用内存方便的多,简洁的多。
至于为何不使用寄存器,小匹夫在上文提到的文章中已经解释过了。简单的讲就是因为简单。
好啦,到此为CIL正名的过程就结束啦。那么下面就开始首尾呼应,结尾点题,从Hello World开始踏上我们的CIL语言的征程吧~~
Hello Wolrd 你好,沃尔德
本文开篇就提到了那句名言:“万事开头,Hello World”。那么我们第一个CIL语言的程序,就从Hello World开始吧。因为匹夫使用的是mac机器,所以编译.il文件所使用的工具是mono的ilasm。
那么匹夫就先新建一个.il文件,起名就叫做chen.il好了。

与C#不同,CIL并不要求方法必须要属于一个类。所以,我们无需定义一个类,只需要声明一个主函数(按照C#的说法main)即可。其实在CIL中我们应该管这种函数叫做“entrypoint”,也就是入口函数。只要定义了“entrypoint”,函数叫不叫main都无关紧要,为了演示这一点,我们的函数名就叫做Fanyou好了。
那么小匹夫就这样写一下咯:

上面就是小匹夫的Fanyou方法的定义了。和一般的语言一样,包括方法签名和方法体。但是在CIL语言中,方法的定义有以下需要注意的地方:
- 方法的定义以.method作为标识,可以在类中声明,也可以在类外声明。
- 和C#一样,CIL程序的入口也必须是静态的,也就是意味着调用这个入口函数并不需要某个类的实例。当然,使用static关键字来标识。
- 入口的标识.entrypoint,这个标志表明了该方法是CIL程序的入口。所以咯,只有一个函数能拥有.entrypoint标识。
- .maxstack这个标识表明了预计使用的堆栈槽,这里是1,因为我们只是把“Hello World”这个字符串压栈。举个例子,如果像上文那样做2个数相加的加法,则需要2个堆栈槽,首先需要将2个数压栈,之后add操作符将2个数弹出并求和,最后将结果压栈。所以最多需要2个栈槽。
- ldstr操作符将“Hello World”压栈,供之后的WriteLine方法使用。
- call调用了mscorlib程序集中System.Console类的WriteLine方法。这里call指明了WriteLine完整的签名(void [mscorlib]System.Console::WriteLine(string))所以运行时可以选择WriteLine的正确地重载。
- ret操作符则将结果返回给调用者。在这里,作为入口函数的返回,也意味着应用运行的结束。
- 有一些同学可能也看过很多CIL语言的代码,是不是发现它们每一条语句之前往往有一个“IL_0000:”这样的东东?但是匹夫你写的代码里没有啊!是不是你写错了?NO,NO,那个IL_XXXX其实仅仅是行号,是不会影响程序的运行的。
好啦,一个简单地Hello World的确能带来一些最基本的知识点,但是这个.il文件编译之后能运行吗?答案是NO。因为上面的第6点也说了,调用了mscorlib程序集。但是我们貌似没有引入什么程序集啊?所以我们还要加入一些程序集的信息才可以哦。那么完整的代码如下了:
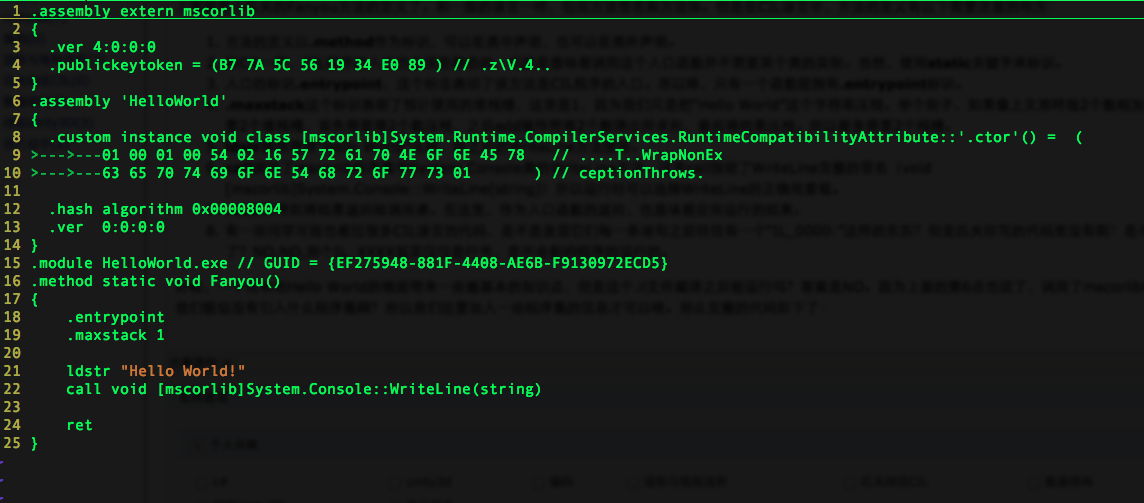
然后,让我们编译并且运行一下,看看我们写的实现了Fanyou方法,输出Hello World的CIL代码到底是否可以运行吧!
运行结果:

首先
ilasm chen.il
对chen.il这个CIL文件进行编译,生成的结果是chen.exe
之后再运行chen.exe
mono chen.exe
可以看到屏幕上输出了“Hello World”。
OK,大功告成!
如果各位看官觉得文章写得还好,那么就容小匹夫跪求各位给点个“推荐”,谢啦~
装模作样的声明一下:本博文章若非特殊注明皆为原创,若需转载请保留原文链接(http://www.cnblogs.com/murongxiaopifu/p/4257264.html)及作者信息慕容小匹夫
后记
CIL代码虽然号称不是很友好,但是作为C#程序员的确还是很有必要掌握一下。匹夫水平一般,能力有限,愿抛砖引玉和大家共同探讨,共同进步。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)