es6 模块与commonJS的区别
在刚接触模块化开发的阶段,我总是容易将export、import、require等语法给弄混,今天索性记个笔记,将ES6 模块
知识点理清楚
未接触ES6 模块时,模块开发方案常见的有CommonJS、AMD、CMD三种。CommonJS用于服务器,而另外两种是用于浏览器。
接触ES6 模块后,模块体系变得更加完善,功能实现更简单,服务器和浏览器都通用,完全可以取代常见的三种规范。今天就记一下es6模块和CommonJS的区别。
一、加载方式
ES6 模块的设计思想,是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。CommonJS 和 AMD、CMD 模块,都只能在运行时确定这些东西。
比如,CommonJS 模块就是对象,输入时必须查找对象属性。
// CommonJS模块
let { stat, exists, readFile } = require('fs');
// 等同于
let _fs = require('fs');
let stat = _fs.stat, exists = _fs.exists, readfile = _fs.readfile;
上面的代码实质是整体加载了模块fs的所有方法,生成了一个_fs对象,然后从这个对象读取三个方法。如果模块里没有很多方法的话,这样开发貌似是不错的,
可是一旦方法多了起来,那性能将大大降低,加载了多余的方法,浪费我的宽带。这加载简称点就是“运行后加载”。
而ES6 模块不是对象,而是通过export命令显式指定输出的代码,再通过import命令输入。
// ES6模块
import { stat, exists, readFile } from 'fs';
上面代码的实质是从fs模块加载3个方法,其他方法不加载。这种加载称为“编译时加载”或者静态加载,即 ES6 可以在编译时就完成模块加载,效率要比 CommonJS 模块的加载方式高。当然,这也导致了没法引用 ES6 模块本身,因为它不是对象。
由于 ES6 模块是编译时加载,使得静态分析成为可能。有了它,就能进一步拓宽 JavaScript 的语法,比如引入宏(macro)和类型检验(type system)这些只能靠静态分析实现的功能。
除了静态加载带来的各种好处,ES6 模块还有以下好处。
- 不再需要UMD模块格式了,将来服务器和浏览器都会支持 ES6 模块格式。目前,通过各种工具库,其实已经做到了这一点。
- 将来浏览器的新 API 就能用模块格式提供,不再必要做成全局变量或者navigator对象的属性。
- 不再需要对象作为命名空间(比如Math对象),未来这些功能可以通过模块提供。
二、值的引用
除了加载方式的不一样,在模块值的运用也有不一样的特点。CommonJS模块输出的是一个值的拷贝,而ES6模块输出的是值的引用。
CommonJS模块输出的是被输出值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。请看下面这个模块文件lib.js的例子。
// lib.js
var counter = 3;
function incCounter() {
counter++;
}
module.exports = {
counter: counter,
incCounter: incCounter,
};
上面代码输出内部变量counter和改写这个变量的内部方法incCounter。然后,在main.js里面加载这个模块。
// main.js
var mod = require('./lib');
console.log(mod.counter); // 3
mod.incCounter();
console.log(mod.counter); // 3
上面代码说明,lib.js模块加载以后,它的内部变化就影响不到输出的mod.counter了。这是因为mod.counter是一个原始类型的值,会被缓存。除非写成一个函数,才能得到内部变动后的值。
// lib.js
var counter = 3;
function incCounter() {
counter++;
}
module.exports = {
get counter() {
return counter
},
incCounter: incCounter,
};
上面代码中,输出的counter属性实际上是一个取值器函数。现在再执行main.js,就可以正确读取内部变量counter的变动了。
ES6模块的运行机制与CommonJS不一样,它遇到模块加载命令import时,不会去执行模块,而是只生成一个动态的只读引用。等到真的需要用到时,再到模块里面去取值,换句话说,ES6的输入有点像Unix系统的“符号连接”,原始值变了,import输入的值也会跟着变。因此,ES6模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
还是举上面的例子。
// lib.js
export let counter = 3;
export function incCounter() {
counter++;
}
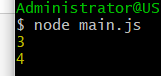
// main.js
import { counter, incCounter } from './lib';
console.log(counter); // 3
incCounter();
console.log(counter); // 4
上面代码说明,ES6模块输入的变量counter是活的,完全反应其所在模块lib.js内部的变化。
再举一个出现在export一节中的例子。
// m1.js
export var foo = 'bar';
setTimeout(() => foo = 'baz', 500);
// m2.js
import {foo} from './m1.js';
console.log(foo);
setTimeout(() => console.log(foo), 500);
上面代码中,m1.js的变量foo,在刚加载时等于bar,过了500毫秒,又变为等于baz。
让我们看看,m2.js能否正确读取这个变化。
$ babel-node m2.js bar baz
上面代码表明,ES6模块不会缓存运行结果,而是动态地去被加载的模块取值,并且变量总是绑定其所在的模块。
由于ES6输入的模块变量,只是一个“符号连接”,所以这个变量是只读的,对它进行重新赋值会报错。
// lib.js
export let obj = {};
// main.js
import { obj } from './lib';
obj.prop = 123; // OK
obj = {}; // TypeError
上面代码中,main.js从lib.js输入变量obj,可以对obj添加属性,但是重新赋值就会报错。因为变量obj指向的地址是只读的,不能重新赋值,这就好比main.js创造了一个名为obj的const变量。
最后,export通过接口,输出的是同一个值。不同的脚本加载这个接口,得到的都是同样的实例。
// mod.js
function C() {
this.sum = 0;
this.add = function () {
this.sum += 1;
};
this.show = function () {
console.log(this.sum);
};
}
export let c = new C();
上面的脚本mod.js,输出的是一个C的实例。不同的脚本加载这个模块,得到的都是同一个实例。
// x.js
import {c} from './mod';
c.add();
// y.js
import {c} from './mod';
c.show();
// main.js
import './x';
import './y';
现在执行main.js,输出的是1。
$ babel-node main.js 1
这就证明了x.js和y.js加载的都是C的同一个实例。
三、循环加载
“循环加载”(circular dependency)指的是,a脚本的执行依赖b脚本,而b脚本的执行又依赖a脚本。
// a.js
var b = require('b');
// b.js
var a = require('a');
通常,“循环加载”表示存在强耦合,如果处理不好,还可能导致递归加载,使得程序无法执行,因此应该避免出现。
但是实际上,这是很难避免的,尤其是依赖关系复杂的大项目,很容易出现a依赖b,b依赖c,c又依赖a这样的情况。这意味着,模块加载机制必须考虑“循环加载”的情况。
对于JavaScript语言来说,目前最常见的两种模块格式CommonJS和ES6,处理“循环加载”的方法是不一样的,返回的结果也不一样。
CommonJS模块的循环加载
CommonJS模块的重要特性是加载时执行,即脚本代码在require的时候,就会全部执行。一旦出现某个模块被"循环加载",就只输出已经执行的部分,还未执行的部分不会输出。
让我们来看,Node官方文档里面的例子。脚本文件a.js代码如下。
exports.done = false;
var b = require('./b.js');
console.log('在 a.js 之中,b.done = %j', b.done);
exports.done = true;
console.log('a.js 执行完毕');
上面代码之中,a.js脚本先输出一个done变量,然后加载另一个脚本文件b.js。注意,此时a.js代码就停在这里,等待b.js执行完毕,再往下执行。
再看b.js的代码。
exports.done = false;
var a = require('./a.js');
console.log('在 b.js 之中,a.done = %j', a.done);
exports.done = true;
console.log('b.js 执行完毕');
上面代码之中,b.js执行到第二行,就会去加载a.js,这时,就发生了“循环加载”。系统会去a.js模块对应对象的exports属性取值,可是因为a.js还没有执行完,从exports属性只能取回已经执行的部分,而不是最后的值。
a.js已经执行的部分,只有一行。
exports.done = false;
因此,对于b.js来说,它从a.js只输入一个变量done,值为false。
然后,b.js接着往下执行,等到全部执行完毕,再把执行权交还给a.js。于是,a.js接着往下执行,直到执行完毕。我们写一个脚本main.js,验证这个过程。
var a = require('./a.js');
var b = require('./b.js');
console.log('在 main.js 之中, a.done=%j, b.done=%j', a.done, b.done);
执行main.js,运行结果如下。
$ node main.js 在 b.js 之中,a.done = false b.js 执行完毕 在 a.js 之中,b.done = true a.js 执行完毕 在 main.js 之中, a.done=true, b.done=true
上面的代码证明了两件事。一是,在b.js之中,a.js没有执行完毕,只执行了第一行。二是,main.js执行到第二行时,不会再次执行b.js,而是输出缓存的b.js的执行结果,即它的第四行。
exports.done = true;
总之,CommonJS输入的是被输出值的拷贝,不是引用。
另外,由于CommonJS模块遇到循环加载时,返回的是当前已经执行的部分的值,而不是代码全部执行后的值,两者可能会有差异。所以,输入变量的时候,必须非常小心。
var a = require('a'); // 安全的写法
var foo = require('a').foo; // 危险的写法
exports.good = function (arg) {
return a.foo('good', arg); // 使用的是 a.foo 的最新值
};
exports.bad = function (arg) {
return foo('bad', arg); // 使用的是一个部分加载时的值
};
上面代码中,如果发生循环加载,require('a').foo的值很可能后面会被改写,改用require('a')会更保险一点。
ES6模块的循环加载
ES6处理“循环加载”与CommonJS有本质的不同。ES6模块是动态引用,如果使用import从一个模块加载变量(即import foo from 'foo'),那些变量不会被缓存,而是成为一个指向被加载模块的引用,需要开发者自己保证,真正取值的时候能够取到值。
请看下面这个例子。
// a.js如下
import {bar} from './b.js';
console.log('a.js');
console.log(bar);
export let foo = 'foo';
// b.js
import {foo} from './a.js';
console.log('b.js');
console.log(foo);
export let bar = 'bar';
上面代码中,a.js加载b.js,b.js又加载a.js,构成循环加载。执行a.js,结果如下。
$ babel-node a.js b.js undefined a.js bar
上面代码中,由于a.js的第一行是加载b.js,所以先执行的是b.js。而b.js的第一行又是加载a.js,这时由于a.js已经开始执行了,所以不会重复执行,而是继续往下执行b.js,所以第一行输出的是b.js。
接着,b.js要打印变量foo,这时a.js还没执行完,取不到foo的值,导致打印出来是undefined。b.js执行完,开始执行a.js,这时就一切正常了。
再看一个稍微复杂的例子(摘自 Dr. Axel Rauschmayer 的《Exploring ES6》)。
// a.js
import {bar} from './b.js';
export function foo() {
console.log('foo');
bar();
console.log('执行完毕');
}
foo();
// b.js
import {foo} from './a.js';
export function bar() {
console.log('bar');
if (Math.random() > 0.5) {
foo();
}
}
按照CommonJS规范,上面的代码是没法执行的。a先加载b,然后b又加载a,这时a还没有任何执行结果,所以输出结果为null,即对于b.js来说,变量foo的值等于null,后面的foo()就会报错。
但是,ES6可以执行上面的代码。
$ babel-node a.js foo bar 执行完毕 // 执行结果也有可能是 foo bar foo bar 执行完毕 执行完毕
上面代码中,a.js之所以能够执行,原因就在于ES6加载的变量,都是动态引用其所在的模块。只要引用存在,代码就能执行。
下面,我们详细分析这段代码的运行过程。
// a.js
// 这一行建立一个引用,
// 从`b.js`引用`bar`
import {bar} from './b.js';
export function foo() {
// 执行时第一行输出 foo
console.log('foo');
// 到 b.js 执行 bar
bar();
console.log('执行完毕');
}
foo();
// b.js
// 建立`a.js`的`foo`引用
import {foo} from './a.js';
export function bar() {
// 执行时,第二行输出 bar
console.log('bar');
// 递归执行 foo,一旦随机数
// 小于等于0.5,就停止执行
if (Math.random() > 0.5) {
foo();
}
}
我们再来看ES6模块加载器SystemJS给出的一个例子。
// even.js
import { odd } from './odd'
export var counter = 0;
export function even(n) {
counter++;
return n == 0 || odd(n - 1);
}
// odd.js
import { even } from './even';
export function odd(n) {
return n != 0 && even(n - 1);
}
上面代码中,even.js里面的函数even有一个参数n,只要不等于0,就会减去1,传入加载的odd()。odd.js也会做类似操作。
运行上面这段代码,结果如下。
$ babel-node > import * as m from './even.js'; > m.even(10); true > m.counter 6 > m.even(20) true > m.counter 17
上面代码中,参数n从10变为0的过程中,even()一共会执行6次,所以变量counter等于6。第二次调用even()时,参数n从20变为0,even()一共会执行11次,加上前面的6次,所以变量counter等于17。
这个例子要是改写成CommonJS,就根本无法执行,会报错。
// even.js
var odd = require('./odd');
var counter = 0;
exports.counter = counter;
exports.even = function(n) {
counter++;
return n == 0 || odd(n - 1);
}
// odd.js
var even = require('./even').even;
module.exports = function(n) {
return n != 0 && even(n - 1);
}
上面代码中,even.js加载odd.js,而odd.js又去加载even.js,形成“循环加载”。这时,执行引擎就会输出even.js已经执行的部分(不存在任何结果),所以在odd.js之中,变量even等于null,等到后面调用even(n-1)就会报错。
$ node
> var m = require('./even');
> m.even(10)
TypeError: even is not a function

