
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
研究问题
1.作者认为LLM(GPT-4、Gemini)已经很先进了,视觉模态的大模型于LLM性能之间存在gap。
2. 对于视觉自身,图像分辨率是一个核心因素,但是提高分辨率对计算性能和cost有要求。
综上所述,作者希望“how to push forward the VLMs approaching well-developed models with acceptable cost in an academic setting?”
研究方法
三个策略
为了解决上述问题,作者从三个策略:
1. “efficient high-resolution solution”
2. “high-quality data”
3. “expanded applications”
具体来说,首先,使用ConvNet来有效地生成高分辨率的候选,因此在增强视觉细节的同时保持视觉token的数量不变。然后,从多个公开源获取高质量的数据集,保证一个丰富和多样的数据基础。另外,使用最先进的大语言模型和生成模型,保证VLM的表现和用户体验最先进。
研究方法
总的来说,提出的方法采用any-to-any范式,擅长处理图像和文本都作为输入和输出的情况。
具体地,
1.提出了一种用于输入图像的高效视觉标记增强管道(an efficient visual token enhancement pipeline for input images),该管道具有双编码器系统,包括两个编码器,分别用于高分辨率图像和低分辨率视觉嵌入,反映了Gemini constellation (看不到什么意思,双子座?写作用词太高级不容易让人理解)的协作能力。在推理阶段,它们通过注意力机制起作用,其中低分辨率生成视觉queries,高分辨率提供候选keys和values。
2.为了增强数据质量,作者基于公开源收集并制作了更多数据,包括还质量的响应(high-quality responses)、任务导向的指令(task-oriented instructions)和生成相关的数据(generation-related data)。
3.模型支持并行图像和文本生成,这得益于我们的VLM与高级生成模型的无缝集成。它通过提供LLM生成的文本,利用VLM指导生成图像。
相关工作综述
大语言模型
最近自然语言处理的进程被大语言模型(LLMs)戏剧性地加速了。
Transformer框架的开创性引入成为基石,促成了新一轮的语言模型,如Bert和OPT,它们表现出了深刻的语言理解能力。生成预训练Transformer(Generative Pre-trained Transformer, GPT)的诞生通过自回归语言建模引入了一种新的范式,为语言预测和生成建立了一种稳健的方法 。ChatGPT、GPT-4、LLaMA和Mixtral等模型的出现进一步促进了该领域的快速发展,由于它们在广泛的文本数据集上进行了训练,每个模型在复杂的语言处理任务上都表现出了更强的性能。
指令微调(Instruction Tuning)已成为细化预训练LLM输出的关键技术,其在Alpaca和Vicuna等开源模型开发中的应用证明了这一点。它们使用自定义指令集对LLaMA进行迭代。
此外,LLM与视觉任务的集成突出了它们的适应性和广泛应用的潜力,强调了LLM在超越传统的基于文本的处理包括多模式交互方面的实用性。
在这项工作中,作者以几个预先训练的LLM为基准,并在此基础上构建多模态框架,以进一步扩展令人印象深刻的推理能力。
视觉语言模型
计算机视觉和自然语言处理的融合产生了VLM,它将视觉和语言模型结合起来,以实现跨模态理解和推理能力。这种集成在推进既需要视觉理解又需要语言处理的任务方面至关重要,在不同数据集上训练的模型证明了这一点,用于理解和推理。
CLIP等开创性的模型进一步弥合了语言模型和视觉任务之间的差距,展示了跨模态应用的可行性。最近的发展强调了在VLM领域内利用LLM强大能力的日益增长的趋势。Flamingo和BLIP-2等创新利用了大量的图像-文本对集合来微调跨模态对齐,显著提高了学习效率。在这些进步的基础上,一些工作专注于基于BLIP-2生成高质量的教学数据,从而显著提高了性能。此外,LLaVA采用了一种简单的线性投影仪,以最小的可学习参数促进图像-文本空间对齐。它利用了量身定制的指令数据,并举例说明了一种高效的策略,展示了该模型的强大功能。与他们不同的是,作者旨在探索理解和生成的潜力。
大语言模型作为生成助理
将LLM与图像输出相结合已成为最近多模态研究的一个关键领域。像InternetLM XComposer这样的方法利用图像检索来产生交错的文本和图像输出,绕过直接生成。相反,以EMU和SEED为例的自回归令牌预测方法使LLM能够直接通过海量图像文本数据对图像进行解码。
这些方法需要大量的训练资源,并且它们的自回归性质导致了不期望的延迟。最近的研究努力与潜在扩散模型保持一致,以简化图像生成。它们通常需要设计文本嵌入和额外的优化来实现所需的生成效果。这种联合训练可能会影响VLM在文本生成中的性能。
Mini-Gemini通过采用文本数据驱动的方法使模型能够生成高质量的图像而脱颖而出。仅利用13K纯文本数据来激活LLM作为高质量重字幕机(re-captioner)的能力,而不会破坏VLM的基本性能。
Mini-Gemini
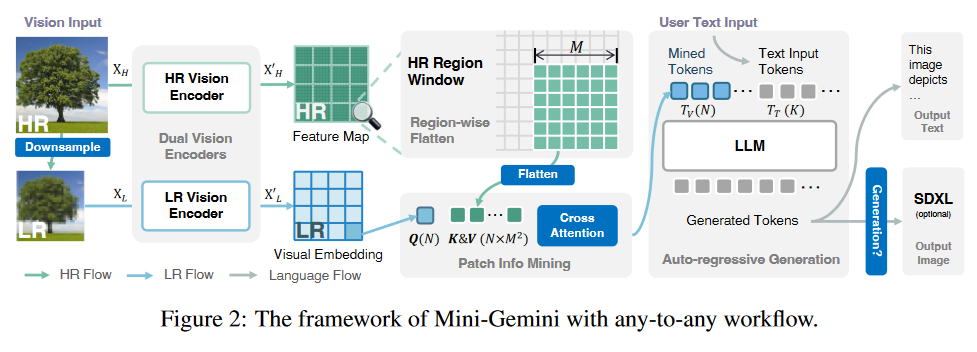
Mini-Gemini的框架在概念上很简单:双视觉编码器(dual visual encoders)用于提供低分辨率的视觉嵌入和高分辨率的候选者;提出了补丁信息挖掘(patch info mining),对高分辨率区域和低分辨率视觉查询进行补丁级挖掘;LLM用于将文本与图像结合起来,同时用于理解和生成。
Dual Vision Encoders
如图2所示,使用双视觉编码器,分别提取高分辨率和低分辨率的视觉信息。
对于低分辨率流,保留传统管道,使用CLIP预训练的ViT编码视觉嵌入。这样,视觉patch之间的长程关系可以很好地保留用于LLM中的后续交互。
对于高分辨率流,使用基于CNN的编码器来实现自适应且高效的高分辨率图像处理。例如,为了对其低分辨率的视觉嵌入,LAION-pretrained ConvNext 被用作高分辨率视觉编码器。因此,高分辨率特征图可以通过将来自不同卷积级的特征上采样和拼接到1/4的输入规模。
Patch Info Mining
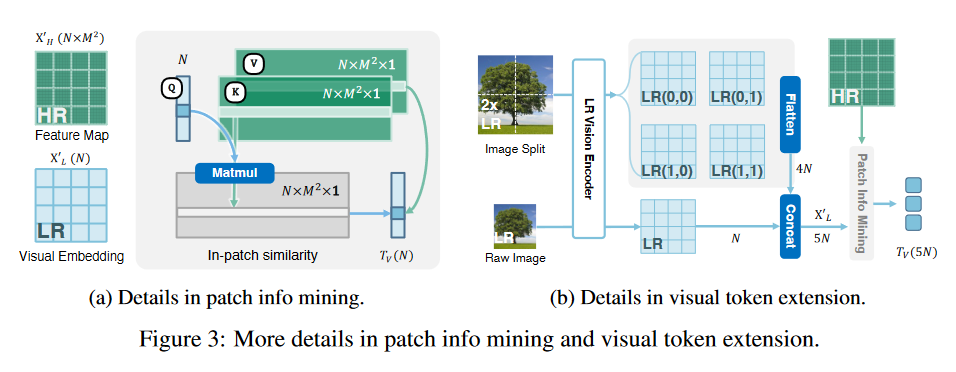
获得生成的低分辨率嵌入和高分辨率特征后,作者提出patch 信息挖掘方法,通过增强视觉token扩展VLMs的潜力。具体来说,为了在LLMs中保持最终视觉标记的数量以提高效率,作者将低分辨率嵌入作为query,从高分辨率候选者中(keys,values)检索相关的视觉线索,如图3(a)所示。公式化表示为:
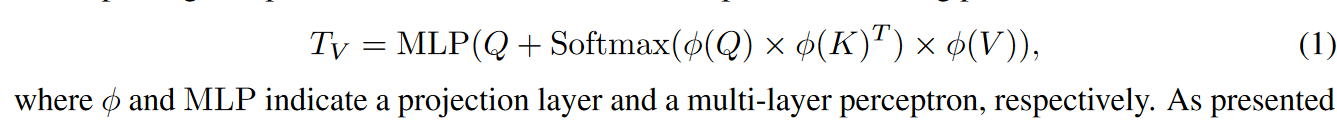
另外,patch信息挖掘还支持视觉token扩展(visual token extension)。如图3(b)所示,该方法可以将视觉token扩展到5N来捕获更多细节。该方法通过将原始图像与其2倍方法的对应图像合并来实现,从而产生批量输入。并且可以通过上一小节的低分辨率视觉编码器来获得编码的视觉嵌入。由于基于CNN的高分辨率视觉编码器的灵活设计,它可以在补丁信息挖掘过程中熟练地处理增强的视觉标记计数。上述过程中唯一的区别是,高分辨率特征中的子区域应根据扩展的视觉嵌入进行更改。
Text and Image Generation
将输入的文本token和挖掘的视觉token进行拼接,作为LLM的输入,进而实现自回归地生成,如图2所示。相较于传统VLMs,Mini-Gemini支持text-only and text-image generation as input and output, 即 any-to-any 推理。
Text-image Instructions

Generation-related Instructions




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律