
RNN和LSTM
必看:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
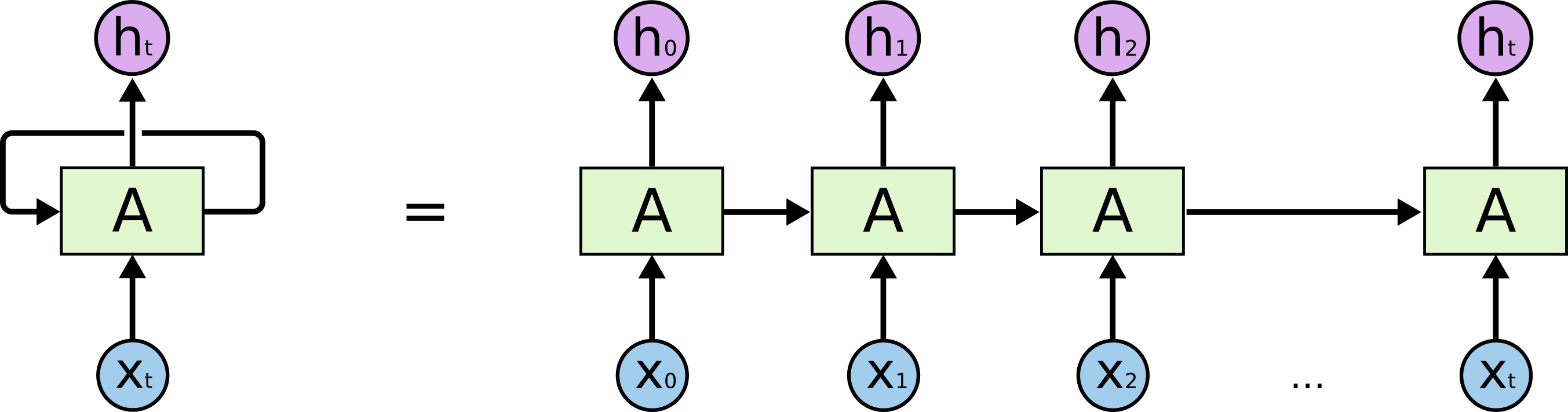
RNN(Recurrent)
前馈神经网络:https://www.cnblogs.com/mumuzeze/p/16883851.html
前馈网络的输入之间是没有关系的,可以近似认为它们服从独立同分布。
而循环神经网络数据之间存在时序关系,如语言、视频帧等。
循环神经网络可以被看作同一网络的多个副本,每个副本都将消息传递给后继者。它可以处理输入数据内部的时序关系,它能够将先前的信息与当前任务联系起来,例如使用先前的视频帧可能会告知对当前帧的理解。
长时依赖问题
有时,我们只需要查看最近的信息即可执行当前任务。例如,一个语言模型试图根据之前的单词预测下一个单词。如果我们试图预测“云在天空”中的最后一个词,我们不需要任何进一步的上下文————很明显下一个词将是天空。在这种情况下,相关信息与所需位置之间的差距很小,RNN可以学习学习使用过去的信息。

但更多的情况下我们需要更多的上下文信息。例如,语言模型长时预测文本“我在法国长大.......,我说流利的法语”中的最后一个词。首先,距离当前最近的信息表明下一个词可能是一种语言的名称,但如果我们想缩小这种语言的范围,我们需要‘法国’的上下文信息,这在句子中距离预测的单词很远。相关信息和预测点之间的距离完全有可能变得非常大。
不幸的是,随着距离的扩大,RNN无法学习到需要的相关信息。
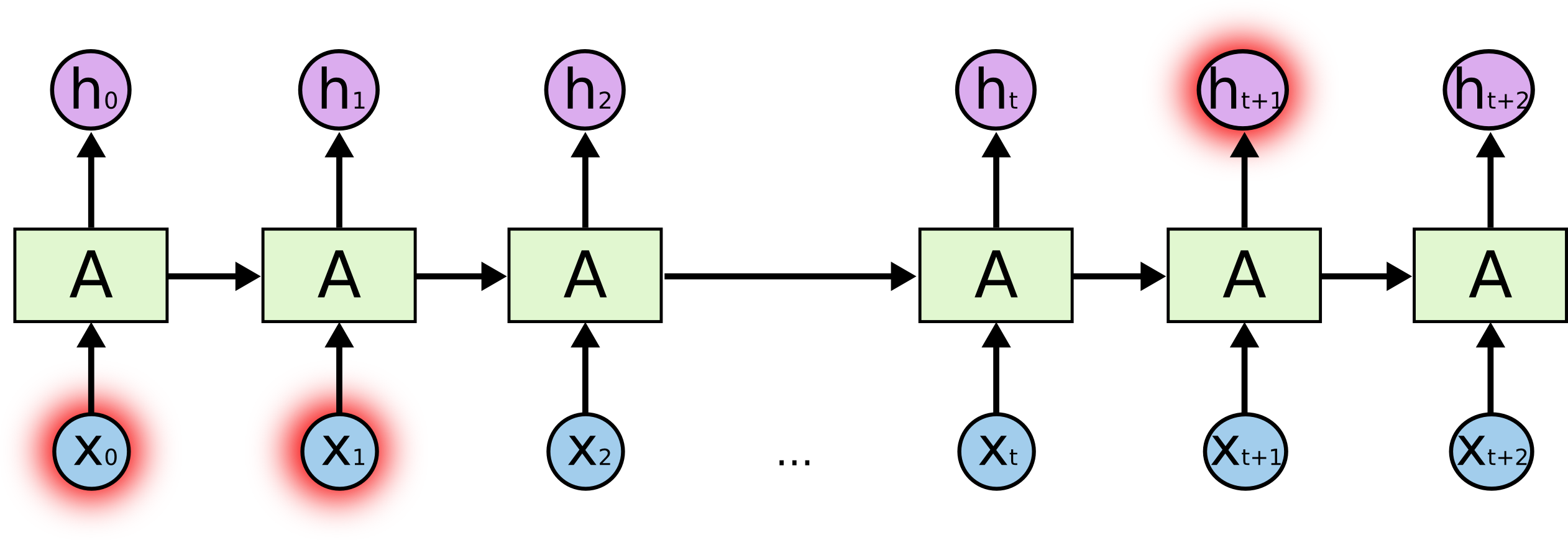
理论上,RNNs绝对有能力处理这种 "长期依赖"。人类可以为它们仔细挑选参数,以解决这种形式的玩具问题。可悲的是,在实践中,RNNs似乎无法学习它们。Hochreiter(1991)[德语]和Bengio等人(1994)对这个问题进行了深入探讨,他们发现了一些相当基本的原因(梯度爆炸和梯度消失),为什么它可能很难。
梯度爆炸和梯度消失
https://www.cnblogs.com/mumuzeze/p/16885928.html
LSTM(Long-Short Term Memory)
在RNN的基础上引入门控机制来控制单元状态,进而控制信息的传播,它包含三个门,分别是:遗忘门,输入门,输出门。
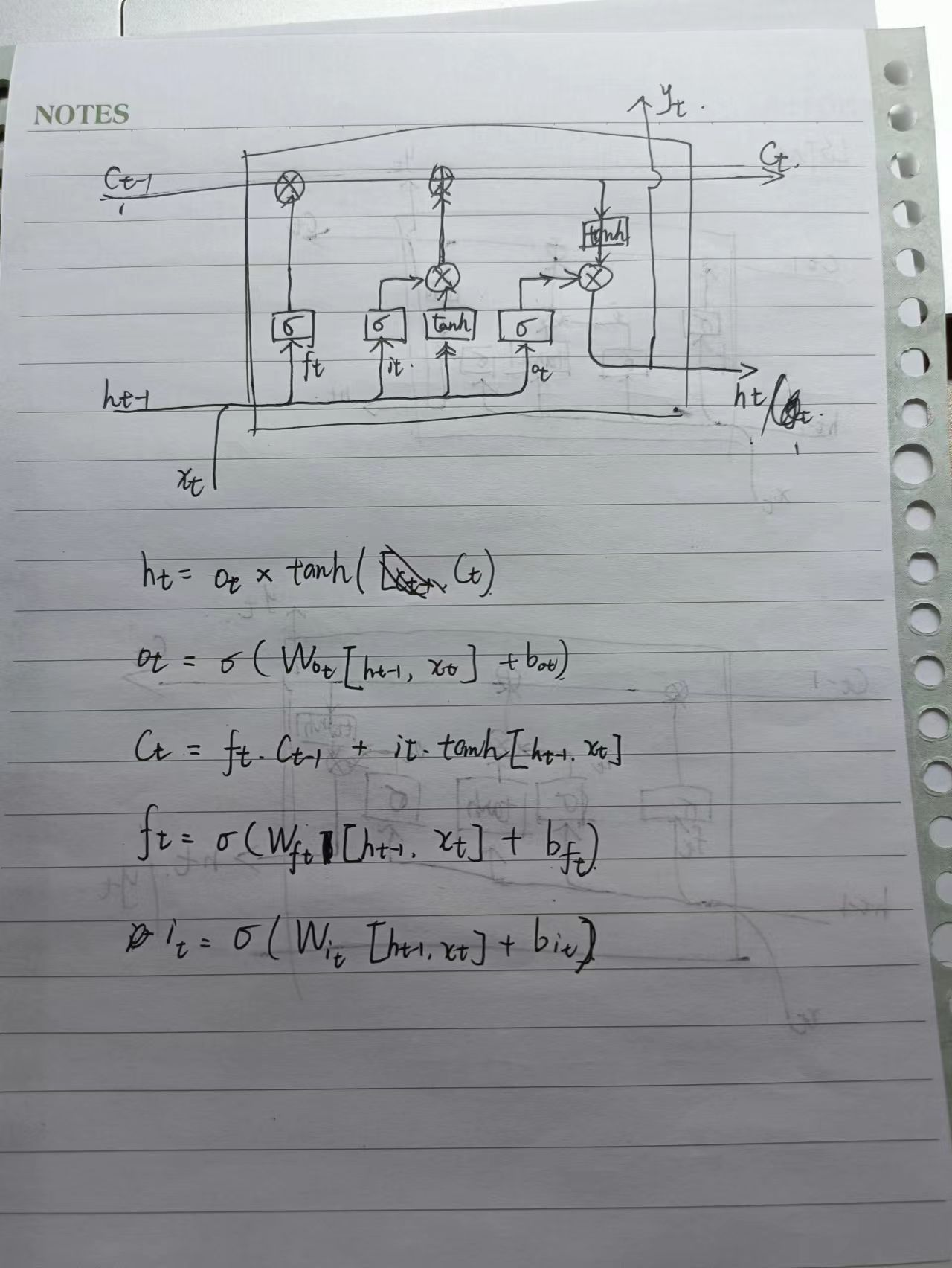
LSTM 解决梯度消失或梯度爆炸的问题
通过链式法则求梯度,连乘项为关于sigmoid的函数,sigmoid结果位于[,1]之间,实际中使其趋近于1即可缓解梯度消失和梯度爆炸的问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构