

Hive自定义函数的学习笔记(1)
前言:
hive本身提供了丰富的函数集, 有普通函数(求平方sqrt), 聚合函数(求和sum), 以及表生成函数(explode, json_tuple)等等. 但不是所有的业务需求都能涉及和覆盖到, 因此hive提供了自定义函数的接口, 方便用户扩展.
自己好像很久没接触hadoop了, 也很久没博客了, 今天趁这个短期的项目, 对hive中涉及的自定义函数做个笔记.
准备:
编写hive自定义函数前, 需要了解下当前线上hive的版本.
1 | hive --vesion |
比如作者使用到的hive版本为:
1 2 | $ hive --versionHive 1.2.1 |
具体编写的自定义函数所依赖的库最好和线上版本保持一致.
使用maven组织工程的话, 如下所示:
1 2 3 4 5 | <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version></dependency> |
编写代码:
Hive中的UDF的设计思路是, 一具体类对应一具体函数.
以最简单的大小写转换函数为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 | package test.ql;import org.apache.hadoop.hive.ql.exec.UDF;public final class LowerUDF extends UDF { public String evaluate(String src) { if ( src == null ) { return ""; } return src.toLowerCase(); }} |
注: 继承于UDF类之后, 编写具体的evaluate函数即可. 这边evaluate感觉像基于名字的约定, 有待后续文章的分析和挖掘, ^_^.
jar打包(非主流做法):
使用maven直接打成jar包(非fat包), 这个非常容易. 因此这边装下逼, 使用一回石器时代的打包方式.
hive的udf函数, 自然依赖于hive相关的jar包.
在linux环境中:
1 2 | $ echo $HIVE_HOME/data/hadoop/hive |
或者使用
1 2 3 4 5 6 7 | $ locate *hive*jardata/hadoop/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar/data/hadoop/apache-hive-1.2.1-bin/lib/hive-contrib-1.2.1.jar/data/hadoop/apache-hive-1.2.1-bin/lib/hive-exec-1.2.1.jar..../data/hadoop/apache-hive-1.2.1-bin/lib/udf.jar.... |
都可以获取到, hive的jar库地址为/data/hadoop/apache-hive-1.2.1-bin/lib
编写编辑脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #! /bin/bash# HIVE_LIB="/data/hadoop/apache-hive-1.2.1-bin/lib/"# 遍历hive的jar库, 放置于classpath中去cp_libs=.for jarfile in $(ls ${HIVE_LIB} ); do cp_libs=${cp_libs}:${HIVE_LIB}/${jarfile}donemkdir -p build# 编译javac -cp ${cp_libs} LowerUDF.java -d build# 打包jar cvf lower.jar -C build . |
这样就可以出一个lower.jar的jar包了.
临时函数的使用:
进入hive的交互shell中
1. 上传自定义udf的jar
hive> add jar /path/to/lower.jar
2. 创建临时函数
hive> create temporary function xxoo_lower as 'test.ql.LowerUDF';
3. 验证
hive> select xxoo_lower("Hello World!");
整个交互流程如下:
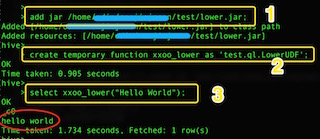
不过这个临时函数, 其生命周期和hive的这个交互session保持一致, 一旦退出, 这个临时函数就消失了.
永久函数的使用:
1. 把自定义函数的jar上传到hdfs中.
hdfs dfs -put lower.jar 'hdfs:///path/to/hive_func';
2. 创建永久函数
hive> create function xxoo_lower as 'test.ql.LowerUDF' using jar 'hdfs:///path/to/hive_func/lower.jar'
3. 验证
hive> select xxoo_lower("Hello World");
hive> show functions;
整个交互流程图如下:
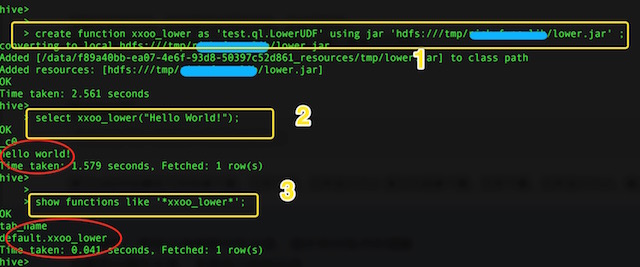
永久函数的删除也容易:
hive> drop function xxoo_lower;
总结:
就如开头所讲的, 该文章纯粹为hive自定函数的学习实战笔记. 将来有机会, 好好研究一下hive自定义函数的类结构和设计模型, ^_^.
个人站点&公众号:
个人微信公众号: 小木的智慧屋

个人游戏作品集站点(尚在建设中...): www.mmxfgame.com

posted on 2016-10-08 17:28 mumuxinfei 阅读(7304) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构